![[OS] Process Scheduling](https://img1.daumcdn.net/thumb/R750x0/?scode=mtistory2&fname=https%3A%2F%2Fblog.kakaocdn.net%2Fdn%2FbeENOO%2Fbtsmz32iimK%2FDStkGXOaLG74CEV4Mto4r0%2Fimg.png)
이 글은 포스텍 박찬익 교수님의 운영체제(CSED312) 강의를 기반으로 재구성한 것입니다.
이 글은 process scheduler를 설명한다.
CPU Scheduler
CPU scheduler는 ready queue에 있는 process 중 하나를 선택해 CPU에 할당한다. 이 때 강제로 다른 process의 가져올 수 있는지 또는 해당 process가 끝난 이후에 scheduling을 진행하는지에 따라 크게 2종류로 나뉜다.
- preemptive : 필요 시 process로부터 CPU를 강제로 회수하는 방법.
- non preemptive : process의 동작이 종료되거나 process가 자발적으로 중지할 때까지 해당 process의 실행을 보장하는 방법.
용어
- task : 사용자의 request
- latency 또는 response time : task를 완료하는 데 걸리는 시간
- throughput : 단위 시간당 끝내는 task 개수
- overhead : scheduler가 추가로 해야 하는 연산량
- fairness : process들이 얼마나 공평하게 실행되는지 여부
- workload : 실행하고자 하는 task set
- work conserving : task가 있는 한 resource를 사용하는 방식. 이 방법의 경우 non-preemptive는 별로이기 때문에 preemptive만 사용한다.
- scheduling algorithm
- input으로는 workload를 받고, output으로는 throughput이나 latency와 같은 성능이 나온다.
- 알고리즘으로는 task를 어떠한 순서로 실행하는지이다.
목표
scheduling을 통해 response time 최소화, throughput 최대화, fair 3가지를 달성하고자 한다.
FIFO : First In, First Out
먼저 들어온 task를 먼저 처리하는 방식이다. 간단하고, 이미 실행중인 task를 끝내야 다음 것을 실행할 수 있기 때문에 non preemptive이다.
이 방법에는 실행시간이 긴 process 뒤에 실행시간이 짧은 process가 오는 경우 wait time이 크게 늘어난다.
예시
예를 들어 process P1이 24s, P2와 P3가 3s가 걸린다고 하자.
P2 - P3 - P1 순서대로 들어온 경우 P2는 3초에, P3는 6초에, P4는 30초에 작업을 끝낸다.
P1 - P2 - P3 순서대로 들어온 경우 P1이 먼저 작업을 시작하고, 24초에 끝낸다. P2는 24초에 작업을 시작하고 27초에 끝낸다. P3는 27초에 작업을 시작하고 30초에 끝낸다.
비록 끝나는 시간은 같지만 P1과 P2가 기다리는 시간이 매우 크게 차이난다.
SJF : Shortest Job First
짧은 task를 먼처 처리하는 방식이다.
- preemptive SJF : SRJF(shortest remain job first)라고 한다. 만약 새로운 task가 도착하는 경우, CPU가 이미 task를 실행 중이었더라도 모든 task 중 제일 짧은 task를 먼저 실행한다.
- non preemptive SJF : task가 양보하거나 끝나기 전까지는 양보하지 않으므로 task를 실행해야 하는 시점에 실행시간이 제일 짧은 것을 먼저 실행한다.
장단점
이 방법은 평균 response time이 최소이기 때문에 optimal이라는 장점이 있다.
그러나 짧은 task가 여러 개 들어올 경우 긴 task가 실행되지 않는 starvation이 일어날 수 있다. (unfair) 또한 task 실행 시간을 완벽하게 예측할 수 없다는 문제점도 있다.
RR : Round Robin
time quantum이라는 정해진 시간을 정해두고 CPU의 실행 시간이 time quantum만큼 되었을 때 해당 task를 ready list의 맨 뒤로 넣는 방식이다.
이 경우 process가 n개, time quantum이 q일 때 최대 (n-1)q만큼 기다린다. 때문에 성능은 q에 의존한다. 만약 q값이 크다면 FIFO와 유사하고, q값이 작다면 context switch에 의해 대부분의 시간을 사용할 수 있다.
장단점
짧은 job들의 처리가 좋다는 장점이 있다.. 그러나 같은 시간을 소모하는 task가 여러 개일 때는 context switch로 인해 성능이 나빠지고 wait time도 늘어난다.
Mixed Workload
RR은 I/O-bound와 CPU-bound를 같이 사용하는 task의 경우에도 성능이 나쁘다. 여기서 I/O-bound는 대부분의 시간을 I/O를 기다리는 데 사용하는 것을, CPU-bound는 대부분의 시간을 계산에 사용하는 것을 의미한다.
여러 I/O가 chain에 걸려있는 상황을 생각해 보자. I/O A가 오면 그것을 확인해서 B에 쓰는 상황을 가정하자. A를 받은 직후 task A는 yield()한다. 이후 CPU-bound 작업이 여러개 실행된다고 생각해 보면, 이 모든 CPU-bound task가 실행된 후 B가 실행되기 때문에 A가 끝난 후 B가 실행하는 것보다 훨씬 더 많은 시간이 걸린다.
MFQ : Multi-Level Feedback Queue
RR의 문제를 해결하기 위해 나온 방법이며 대부분의 OS가 사용하는 방식이다.
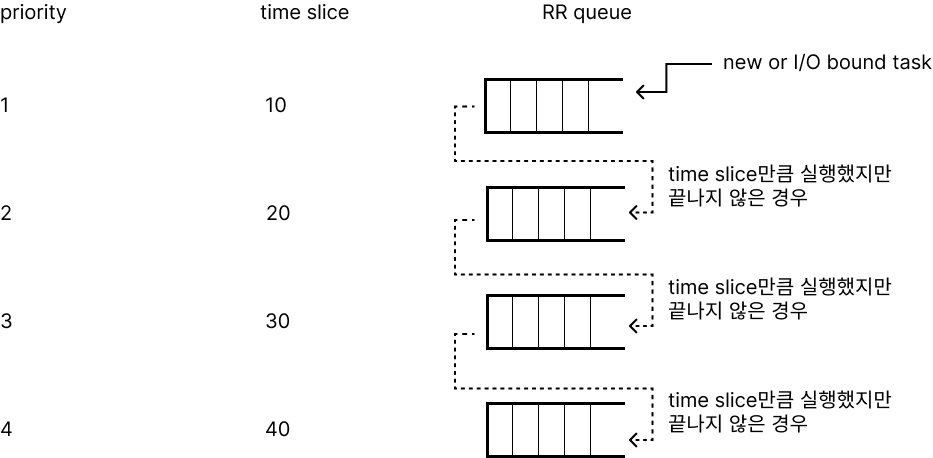
priority에 따라 RR queue를 여러 개 만들고, high priority queue는 짧은 time quantum을 사용하고 low priority queue는 긴 time quantum을 사용하는 방식이다. 방법은 아래와 같다.
- 새로운 task가 오면 high priority queue에 넣는다.
- 모든 queue에서 해당 queue의 time quantum만큼 task를 실행했는데 끝나지 않는다면 더 낮은 priority queue로 해당 task를 넣는다.
- time quantum만큼 실행했는데 끝나지 않았다면 더 긴 시간이 필요할 것이라 예측하고 lower priority queue에 넣는 방식이다.
장점
- 성능이 좋다 : SJF에 근사하기 때문에 optimal에 가깝다.
- overhead가 적다 : preemption의 회수를 최소화하기 때문에 overhead가 적다.
- starvation이 없다 : RR과 같은 방식으로 돌아가기 때문에 starvation이 적다.
- 공평하다.
Multi Processor MFQ; Per-Processor Affinity Scheduling
MFQ를 multi processor에 적용하면 여러가지 문제가 발생한다. ready queue는 shared data이기 때문에 이를 수정하기 위해 scheduler spinlock을 얻기 위한 경쟁이 일어날 수도 있고, cache ping이 발생할 수도 있고, cache에 수정한 값이 메모리에는 반영되지 않았을 수도 있다. 사실상 지난 포스팅에서 살펴본 대부분의 문제가 발생한다.
이를 해결하기 위해 Per-Processor Affinity Scheduling을 사용한다.
각 processor마다 MFQ로 만든 ready list를 두는 방식 + thread가 rescheduling될 때 이전에 할당되었던 processor에 다시 할당하는 방식이다. processor마다 MFQ가 따로 있기 때문에 spinlock을 신경쓰지 않아도 되고, processor에서 사용한 thread만 다시 사용하기 때문에 cache reuse도 해결한다. 이 경우 thread를 할당받지 못하는 processor가 생길 수도 있는데, 이 경우에는 다른 processor로부터 task를 훔쳐온다.
Virtualization & Scheduling
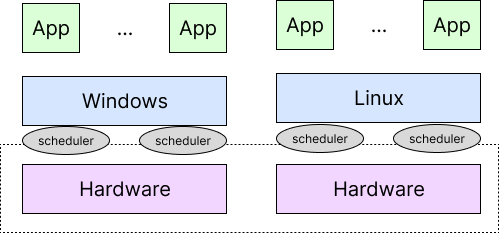

일반적인 경우 왼쪽 그림처럼 각 OS가 자신에게 주어진 CPU로 scheduling한다.
그러나 오른쪽 그림처럼 OS가 virtualization된 경우를 생각해 보자. 각 OS는 자신에게 주어진 virtual CPU로 scheduling하며, virtualization layer에서 physical CPU로 scheduling한다. 총 2번의 scheduling을 하게 되는 것이다! 이러한 구조는 성능 저하를 발생시킨다.
잘못된 내용이나 오탈자에 대한 지적, 질문 등은 언제나 환영합니다.
'CS > OS' 카테고리의 다른 글
| [OS] Demand Paging & Thrashing (0) | 2023.07.15 |
|---|---|
| [OS] Address Translation (0) | 2023.07.15 |
| [OS] Multiprocessor Synchronization & Deadlock (0) | 2023.07.04 |
| [OS] Implementing Synchronization (0) | 2023.07.01 |
| [OS] Synchronization - Lock, Condition Variable, Semaphore (0) | 2023.07.01 |