![[OS] Demand Paging & Thrashing](https://img1.daumcdn.net/thumb/R750x0/?scode=mtistory2&fname=https%3A%2F%2Fblog.kakaocdn.net%2Fdn%2F0172m%2FbtsnD2oHv6K%2FF8CGinQprQFzCmkJXFbAG1%2Fimg.png)
이 글은 포스텍 박찬익 교수님의 운영체제(CSED312) 강의를 기반으로 재구성한 것입니다.
이 글에서는 한정된 physical memory를 무한하게 볼 수 있게 만들어 주는 demand paged virtual memory, memory mapped file, replacement policy, thrashing 등을 살펴본다.
cache의 개념과 구조는 Cache와 Locality 포스팅에 작성했으므로 필요 시 참고하면 될 것 같다.
Cache 복습
cache는 속도가 크고 느린 하위의 저장소에 대한 사본을 만들어 사용해 더 빨리 접근할 수 있게 만드는 방법이다. 만약 cache에 해당 데이터가 있다면 hit, 없다면 miss이다.
cache는 사본인 만큼 cache에 값을 쓰더라도 원본에는 저장되지 않는다. 이를 위해 바꾼 값을 바로 원본에 쓰는 write through, eviction이 발생할 때 원본에 값을 쓰는 write back 등의 기법을 사용해야 한다.
cache가 작동하는 이유는 temporal locality와 spatial locality 때문이다. temporal locality는 최근에 참조한 주소를 반복적으로 참조하는 경향성, spatial locality는 최근에 참조한 주소 근처를 참조하는 경향성을 의미한다.
Demand Paging
address translation 포스팅에서 address space를 사용해 physical memory에 여러 개의 process를 올릴 수 있다는 것을 살펴보았다. 해당 글에서는 process가 physical memory에 올라가기 위해서는 single contiguous section이 필요하다는 것을 전제로 page를 살펴봤었다. 그러나 굳이 한 번에 모든 page를 physical memory에 올려야 할까?라는 의문에서 나온 것이 demand paging이다.
demand paging은 page가 필요할 때만 memory에 올리는 방법이다. 이를 통해 더 적은 memory를 사용할 수 있고, 때문에 더 많은 process를 동시에 실행할 수 있다.
demand paging은 page fault trap으로 작동한다. process가 어떤 page에 접근할 때 flow는 아래와 같다.
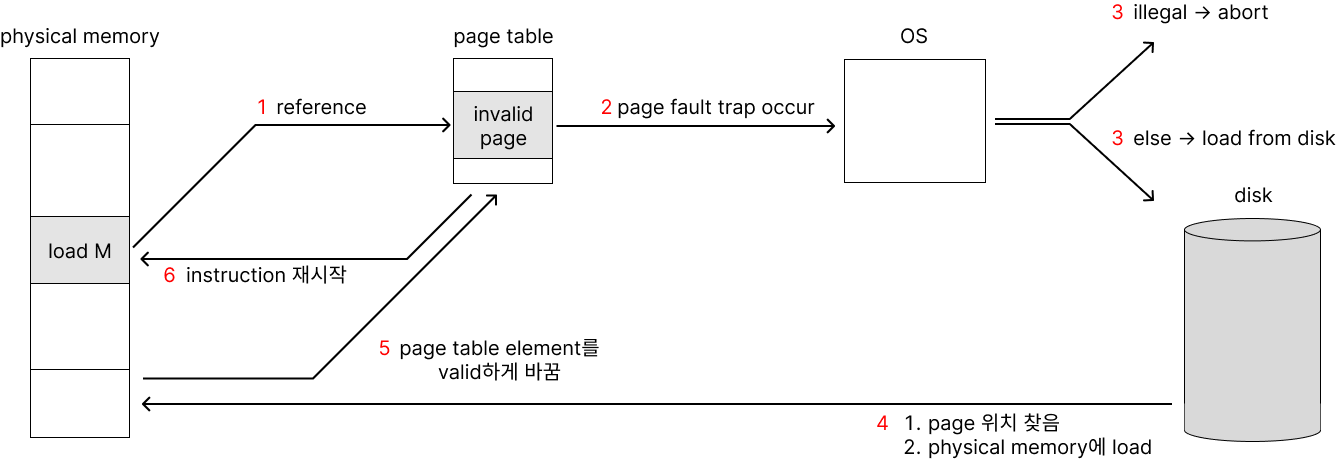
- page table을 살핀다. page table element가 valid하다면 계속 이어간다.
- page table element가 invalid하다면(해당 page가 memory에 올라와 있지 않다면) page fault trap을 호출한다.
- page fault handler가 trap을 받는다. reference가 illegal인지 legal인지 판정한다.
- 잘못된 접근이라면 abort한다.
- 올바른 접근이라면 memory에만 올라가 있지 않은 것이므로 disk로부터 memory를 가져온다. (필요 시 page table을 evict한다.)
- 필요 시 page table를 evict하고 element를 page table에 넣고, valid하게 바꾼다.
- instruction을 재시작한다.
Demand Paging in TLB
hardware가 TLB를 쓰는지, software가 TLB를 쓰는지에 따라 demand paging의 과정이 조금 달라진다.
Hardware Loaded TLB
TLB와 translation을 hardware가 관리할 때, page fault가 나면 아래와 같은 순서로 진행된다.
- TLB miss가 난다.
- page table을 살핀다.
- page fault가 난다. (page table에서 해당 page가 invalid)
- kernel로 trap한다.
- virtual address를 file + offset으로 변환한다.
- page frame을 할당한다. 필요 시 evict한다.
- disk block을 초기화하고 page frame으로 읽어온다.
- direct memory access가 끝나면 disk interrupt를 한다.
- page를 valid하게 마킹한다.
- page fault가 난 instruction에서 process를 재개한다.
- TLB miss가 난다.
- translation을 위해 page table을 살핀다.
- instruction을 실행한다.
1번에서 TLB miss가 났는데, 11번에서 또 TLB miss가 난다. page fault가 발생하지 않았다면 translation이 일어났을 것이고, 그 결과가 TLB에 저장되었을 것이다. 그러나 page fault가 발생해 제어권이 page fault로 넘어갔기 때문에 translation이 일어나지 않았고, 따라서 TLB에 그 값이 저장되지 않는다.
Software Loaded TLB
TLB와 translation을 software가 관리할 때, page fault가 나면 아래와 같은 순서로 진행된다.
- TLB miss가 난다.
- kernel로 trap한다.
- page table을 살핀다.
- page fault가 난다. (page table에서 해당 page가 invalid)
- page frame을 할당한다. 필요 시 evict한다.
- disk block을 초기화하고 page frame으로 읽어온다.
- direct memory access가 끝나면 disk interrupt를 한다.
- page를 valid하게 표기한다.
- TLB를 로드한다.
- page fault가 난 instruction에서 process를 재개한다.
- instruction을 실행한다.
Hardward Loaded TLB와는 달리 TLB miss가 2번 나지 않는다. software가 translation을 하기 때문에 TLB miss 이후 kernel trap이 일어난다. software가 page table을 살피고 TLB를 관리하기 때문에 TLB에 값을 바로 쓸 수 있다. 따라서 TLB miss가 2번 나지 않는다.
Page Frame 할당
page frame을 할당하는 과정은 disk로부터 physical memory로 page를 올리는 과정이며 다음과 같은 순서로 이루어진다.
- 새로운 page frame을 physical memory에 올릴 때, 가득 차 있다면 기존 page frame들 중 적당한 것을 찾아서 교체한다. (eviction)
- 기존 page를 가리키고 있는 모든 page table element를 invalid한다.
- TLB shootdown으로 해당 page table element와 관련된 모든 TLB element를 삭제한다.
- 기존 page frame이 dirty인 경우 write back한다.
Dirty Page 판정
dirty bit를 사용해 dirty page 여부를 판정할 수 있다. store instruction 등으로 해당 page에 무언가를 작성하는 instruction이 있다면 dirty bit를 true로 표현한다. 이 때 TLB와 page table element 둘 다에 dirty bit를 true로 쓴다.
이 과정은 hardware가 관리한다.
이후 해당 page를 가리키는 TLB의 dirty bit가 1이거나, 해당 page를 가리키는 모든 page table element 중 하나라도 dirty bit가 true라면 modified라고 판정한다.

위 그림처럼 TLB element 1개가 page A를 가리키고, page table element 2개가 page A를 가리키는 상황을 가정해 보자. 이 경우 page A를 가리키는 page table element와 TLB의 dirty bit가 true이므로 page A는 dirty page임을 알 수 있다.
Dirty Bit 없이 Dirty 판정 : Emulating Modified Bit
대부분 dirty bit와 use bit를 사용하지만 이를 사용하지 않고도 dirty 여부를 판정할 수 있다. 그러나 꼭 필요한 것은 아니고, permission bit를 적당히 사용해 dirty bit와 use bit를 표현할 수 있다.
dirty bit : store instruction에 대해 true로 설정된다. 수정되었는지 여부를 알 수 있다.
use bit : 모든 access에 대해 true로 설정된다. 최근에 사용했는지 여부를 알 수 있다.
Hardward Loaded TLB
dirty bit는 다음과 같이 모방할 수 있다.
- 초기화 시, page의 permission bit를 read only로 설정한다.
- page에 처음 write가 발생하면 kernel로 trap한다.
- kernel이 해당 page의 permission bit를 read-write로 수정한다.
use bit는 다음과 같이 모방할 수 있다.
- 초기화 시, page의 permission bit를 invalid로 설정한다.. (read/write를 모두 감지해야 하기 때문)
- page에 처음 read/write가 발생하면 kernel로 trap한다.
- kernel이 해당 page의 permission bit를 read나 read-write로 수정한다.
Software Loaded TLB
software loaded TLB의 경우 TLB miss가 나거나 access permission 오류가 발생하면 kernel trap이 발생한다. 때문에 page table을 살펴보지 않고 handler가 이를 바로 구현할 수 있다.
- TLB miss의 경우
- page가 clean이라면 TLB를 read only로 가져온다. 만약 dirty라면 read-write로 설정한다.
- page를 recently used로 설정한다.
- TLB write의 경우
- kernel이 page table의 page를 수정했다고 설정한다.
- TLB element를 read-write로 설정한다.
- page를 recently used로 설정한다.
- TLB write miss의 경우
- kernel이 page table의 page를 수정했다고 표기한다.
- 해당 page의 TLB element를 read-write로 바꾼다.
- page를 recently used로 설정한다.
Memory Mapped File
file I/O를 수행하는 방식은 system call과 memory mapped file 2가지가 있다.
system call의 경우 system call이 발생하면 user process로 file을 복사하고, 해당 정보에 값을 쓰고, system call로 파일에 덮어쓰는 방식이다.
memory mapped file은 demand paging과 유사한 방법이다. demand paging은 실제로는 disk에 있지만 필요할 때 physical memory에 가져오는 방식이다. 때문에 process는 모든 page가 memory에 올라와 있지 않더라도 memory에 올라가 있는 것처럼 행동한다.
file도 똑같다. file을 memory의 일부분이라고 생각해서 physical memory에 올리는 방식으로 쓰면 demand paging과 동일하게 쓴다. file의 일부분이 아직 memory에 올라오지 않은 상태라면 page fault를 일으키고 나머지 file을 로드한다.
장점
- 큰 파일들도 프로그래밍이 간단하다.
- file이 memory에 올라가기 때문에 필요없는 I/O buffer가 사라진다.
- pipelining이 좋다. file의 모든 page가 올라가기 전에 process는 다른 작업을 할 수 있다.
- data sharing이 쉽다. memory에 올라가기 때문에 memory를 공유하는 것과 똑같이 구현하면 된다.
Replacement Policy
cache miss, 또는 page miss가 났을 때 기존 cache가 가득 찬 상태라면 원래 있던 것들 중 하나를 없애고 새로운 것을 넣는다. locality에 의해 최근에 사용한 것은 곧 사용할 확률이 높은 것이다. 어떤 것을 없애야 할까?
FIFO : First In, First Out
제일 먼저 들어온 cache를 교체하는 방식이다. 이 경우 sequential flooding 형태의 입력에 매우 취약하다.
cache가 4개인 상황에서 A, B, C, D, E가 순차적으로 들어오는 상황을 생각해 보자.
처음에는 A, B, C, D가 있을 것이다. 다음에 들어온 E는 A를 대체한다. 다음에 들어온 A는 B를 대체한다. 다음에 들어온 B는 C를 대체한다. ... 이렇게 program stride(반복되는 회수)가 cache size보다 큰 경우 sequential flooding이 발생해 효율이 매우 나쁘다.
Belady의 모순
FIFO replacement policy에서 page frame의 개수를 늘려도 page fault가 더 적게 나지 않는다는 것을 Belady의 모순이라 한다.
예를 들어 page frame이 3개와 4개인 경우에 다음과 같은 12개의 입력이 들어왔다고 생각하자.
A, B, C, D, A, B, E, A, B, C, D, E
3개인 경우 miss, miss ,miss, miss, miss, miss, miss, hit, hit, miss, miss, hit으로 hit 3개가 났다.
4개인 경우 miss, miss, miss, hit, hit, miss, miss, miss, miss, miss, miss, miss로 hit 2개가 났다.
이처럼 page frame의 개수가 는다고 무조건 page fault가 더 적게 나지는 않는다.
MIN
가장 오래 사용하지 않을 것 같은 cache를 교체하는 방식으로, optimal이지만 예측이 필요하기에 실제로 구현할 수 없다.
LRU : Least Recently Used
제일 오래된 cache를 교체하는 방식이다. MIN 방식에 근사한다.
LFU : Least Frequently Used
제일 적게 사용한 cache를 교체하는 방식이다.
Clock Algorithm : Second Chance Algorithm
clock algorithm은 LRU에 근사하는 방식으로, 다음과 같은 로직을 가진다.
- page fault가 나는 경우 page frame의 환형 리스트를 순회한다.
- used bit가 1인 경우 0으로 바꾸고 다음 page frame을 본다.
- used bit가 0인 경우 해당 page frame을 삭제한다.
처음 걸리면 넘어가되, 두 번 걸리면 교체하는 방식이다. 때문에 second chance algorithm이라고도 한다.
LRU를 사용하기 위해서는 해당 cache를 몇 번 사용했는지에 대한 정보인 counter와 같은 hardware가 필요하다. clock algorithm은 이러한 것이 필요없기 때문에 가볍게 쓰기 좋다.
LRU는 MIN에 근사하고, clock은 LRU에 근사한다.
Nth Chance Algorithm
clock algorithm은 2번 걸리면 교체하는 방식으로 used bit를 사용하지만 nth chance algorithm은 n번 걸리면 교체하는 방식으로 bit 대신 정수를 사용한다.
- page fault가 나는 경우 page frame의 환형 리스트를 순회한다.
- used bit가 n이 아닌 경우 1을 더하고 다음 page frame을 본다.
- used bit가 n인 경우 해당 page frame을 삭제한다.
Thrashing
process를 위해 얼만큼의 page frame을 할당해야 할까? equal allocation, proportional allocation으로 크게 2가지 방식이 있다.
- equal allocation : process마다 동일한 page frame을 할당하는 방법
- proportional allocation : process size에 비례해서 page frame을 할당하는 방법
- priority allocation : process priority에 비례해서 page frame을 할당하는 방법
Global vs Local replacement
일반적으로 성능상 이점 때문에 global replacement를 선택한다.
- global replacement : 모든 process의 모든 page frame 중 교체할 것을 선택한다.
- local replacement : 각 process가 자신이 가진 page frame 중에서 교체할 것을 선택한다.
Thrashing
demand paging은 missing page를 부른다. memory가 충분한 경우에는 모든 missing page를 memory에 올릴 것이다. 그러나 memory가 충분하지 않는다면? page fault가 발생하고 따라서 evict가 계속 일어난다. I/O는 100% 사용하지만 대부분을 page 교체에 사용하게 되므로 효율이 급감한다.
이처럼 page fault가 계속 발생하는 상황을 thrashing이라 한다.
thrashing이 발생하는 원인으로는 아래 3가지가 있다.
- physical memory의 page frame이 비효율적으로 사용되는 경우.
- allocated page frame의 개수보다 필요한 page frame의 개수가 더 많은 경우.
- process가 너무 많은 경우.
이 중 첫 번째와 두 번째는 process 자체의 문제이므로 해결하기 어렵지만 세 번째의 경우 해결할 수 있다.
Working Set Model
working set은 효율적인 cache hit를 위해 memory에 올라와 있어야 하는 page들의 set이다. working set model에서는 thrasshing을 막기 위해 working set을 threshold라고 본다.
따라서 working set model은 working set이 모두 올라와 있지 않은 process를 memory에서 잠시 내보내고 working set이 모두 올라온 process부터 실행하는데, 이를 통해 thrashing을 방지한다.
Page Coloring
page coloring은 어떤 cache bucket에 어떤 page frame을 넣을지 구분하는 방법이다. 원래는 같은 곳에 들어가야 하는 cache이지만 coloring을 통해 다른 cache에 넣을 수 있다.

위 그림처럼 memory의 0, 1K, 2K, 3K에 있는 page들이 cache의 같은 line에 저장된다고 하자. 만약 0, 1K, 2K, 3K에 있는 page가 반복적으로 부르면 eviction이 계속해 발생한다. 이를 방지하기 위해 page coloring을 사용한다.
fully associative cache의 경우 하나의 set에 모든 line이 들어가기에 coloring이 필요없다. 반면 direct mapped cache나 N-way associative cache의 경우 coloring을 사용하면 같은 곳에 caching되는 경우 다른 위치로 caching할 수 있기에 성능이 향상된다.
예를 들어 2MB 8-way set associative cache와 4KB page를 사용하는 경우, 2MB / 4KB / 8 = 64개의 color로 page를 구분해 사용한다.
잘못된 내용이나 오탈자에 대한 지적, 질문 등은 언제나 환영합니다.
'CS > OS' 카테고리의 다른 글
| [OS] File System 구현 (0) | 2023.07.17 |
|---|---|
| [OS] File System & Directory (0) | 2023.07.16 |
| [OS] Address Translation (0) | 2023.07.15 |
| [OS] Process Scheduling (0) | 2023.07.06 |
| [OS] Multiprocessor Synchronization & Deadlock (0) | 2023.07.04 |