![[OS] Implementing Synchronization](https://img1.daumcdn.net/thumb/R750x0/?scode=mtistory2&fname=https%3A%2F%2Fblog.kakaocdn.net%2Fdn%2Fbcxt3f%2Fbtsl0j6ufdC%2FBSFkzoi5XQkKTOQ5BMTheK%2Fimg.png)
이 글은 포스텍 박찬익 교수님의 운영체제(CSED312) 강의를 기반으로 재구성한 것입니다.
이전 포스팅에서 Lock, Condition Variable, Semaphore를 살펴봤었다. 이 글에서는 어떻게 이들을 구현하는시 살펴본다.
Sychronization 구현
synchronization을 구현하는 방법에는 크게 3가지가 있다.
- atomic한 memory load/store instruction. (note와 while문을 사용하는 peterson 알고리즘) 그러나 이 방법은 너무 복잡하고 thread 개수가 많아지면 구현하기 어렵기에 좋은 방법이 아니다.
- 특정 코드에 대해 interrupt를 차단하는 방법. 이 방법은 간단하지만 interrupt가 발생했을 때 해당 코드를 모두 실행한 후 interrupt가 실행되기 때문에 느리고, 모든 CPU에 대해 interrupt를 차단하기 때문에 multi processor인 컴퓨터의 경우 너무 비효율적이다. 단 uniprocessor인 경우에는 좋은 선택지이다.
- queueing lock. lock이 사용중일 때 busy waiting으로 만들지 않고 해당 thread를 waiting state로 변경하고 waiting queue에 해당 thread를 등록시키는 방법을 말한다. 이 게시글에서는 queueing lock을 구현한다.
Uniprocessor에서 구현

single processor인 경우에는 interrupt를 제외하고는 involuntary하게 control flow가 바뀌지 않으므로 interrupt를 막는 것만으로도 lock을 쉽게 구현할 수 있다.
- acquire()의 경우 lock BUSY라면 lock의 wait queue에 TCB를 넣는다. 그렇지 않다면 lock을 BUSY로 설정한다.
- release()의 경우 waiting thread가 있다면 그 thread에게 lock을 바로 주고, value값을 수정하지 않는다. waiting thread가 없다면 FREE로 설정한다.
Multiprocessor에서 구현
ready-modify-write instruction을 이용해 lock을 구현한다. 메모리에서 값을 읽고, CPU가 값을 수정하고, 다시 메모리에 값을 작성하는 instruction이며, 각각이 atomic하게 작동한다. 물론 하드웨어단에서 interrupt를 막는다. 예시로 test-and-set과 compare-and-swap이 있다.
test-and-set
boolean test_and_set(boolean *target){
boolean rv = *target;
*target = true;
return rv;
}test_and_set()은 target이 test_and_set()에 들어갔을 때의 값(true로 설정하기 이전의 값)을 리턴한다는 것을 기억하자. 각각의 instruction은 하드웨어가 atomic임을 보장해 준다.
Spin Lock
spinlock은 lock이 해제되기 전까지 무한루프를 돌리는 방법이다. busy waiting이지만 lock이 짧은 시간만 점유될 것이라 예상될 때 이를 사용한다.
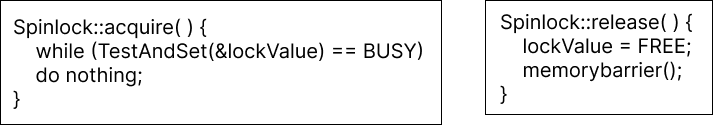
spin lock은 위와 같이 구현한다. 될 때까지 계속 test-and-set을 돌리는 것이다. 이 때 test_and_set()은 target이 test_and_set()에 들어갔을 때의 값(true로 설정하기 이전의 값)을 리턴한다. 이를 생각하고 acquire()를 보면 lockValue가 FREE이고 test_and_set()이 true를 리턴한 경우에만 while문을 탈출할 수 있다.
fixed size stack
thread scheduler는 switching을 위해 현재 실행중인 TCB를 찾아야 한다.
- uniprocessor인 경우 전역변수를 사용하면 간단하다.
- multiprocessor인 경우 여러 방법이 있지만 주로 stack size를 고정하고, stack의 제일 끝에 TCB로의 pointer를 하나 둔다.
- current running thread TCB를 찾기 위해서 current stack pointer를 보고, 해당 stack size는 이미 가지고 있으니 이 둘을 조합해서 TCB 위치를 찾아낸다.

Lock

uniprocessor에서 lock에 spinlock만 추가하면 위와 같이 queueing lock을 구현할 수 있다.
Scheduler List Management

- makeReady() : 해당 thread를 ready state로 변경하고 ready list에 추가한다.
- suspend() : parameter로 받은 lock을 release하고, 현재 실행중인 thread에서 다음 thread로 switch한다.
Condition Variable & Scheduler List
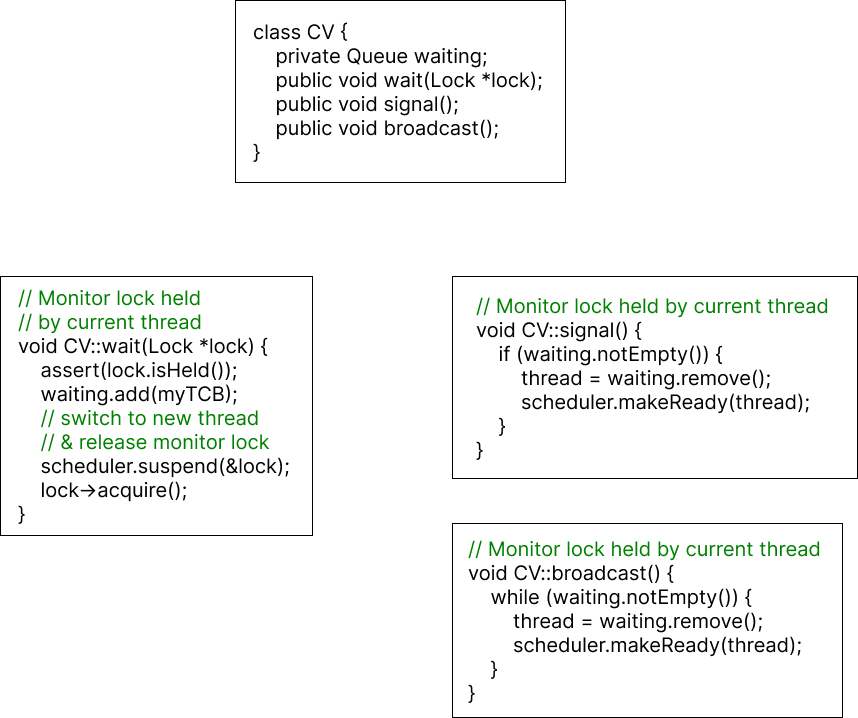
condition variable의 3가지 method과 lock의 기능을 생각해 보면 조금 편하게 위 코드를 이해할 수 있다.
Semaphore

이전 게시글에도 언급했든 semphore는 그렇게 좋은 방법이 아니다. semaphore 하나가 초기화를 어떻게 하냐에 따라 lock으로도, condition variable로도 사용되는데 이는 통일성이 없기 때문에 읽기도 힘들다. 차라리 lock과 condition variable을 같이 사용하는 것이 더 쉽다.
그렇지만서도 semaphore는 I/O device와 thread 사이에서 사용된다. 아마 I/O device는 여러 개로 입/출력이 있기 때문인 것 같다.
Communicating Sequential Process
shared object를 선언하고 lock 등의 방법으로 여러 개의 thread가 shared object에 접근하는 대신 오직 하나의 thread만 shared object에 접근하도록 제한해 synchronization을 구현하는 방법이다. golang이 이렇게 구현되어 있다.
이 방법을 사용하면 어떤 shared object에 접근하기 위해서는 해당 shared object에 접근할 수 있는 thread에게 message를 보내야만 한다. 따라서 event driven 방식으로 동작하게 된다!
예시 : bounded buffer (producer-consumer 문제)

producer-consumer 문제를 다시 생각해 보자. buffer에 값이 있다면 사용하는 consumer thread와, buffer에 값이 없다면 생성하는 producer thread가 있고, buffer가 shared data여서 오직 하나의 thread만 buffer에 접근할 수 있을 때 이를 어떻게 구현할지에 대한 문제이다.
semaphore로 이를 구현할 때는 복잡한 과정을 거쳤는데, communicating sequential process를 사용하면 bounded buffer에 접근하는 thread가 위와 같은 코드를 사용해 message에 응답하는 방식으로 구현한다. 훨씬 직관적이고 코드도 간단하다.
lock/condition variable VS communicating sequential process
| lock / condition variable | communicating sequential process |
| lock이나 condition variable을 사용해 shared data에 접근한다. | 하나의 thread를 생성해 data에 접근한다. |
| condition이 달성될 때까지 기다린다. (wait condition) | queue를 만들어 message/wait 구조를 만든다. |
| shared object의 method를 만든다. | 해당 data의 message/wait를 보낸다. |
Synchronization Problems
synchronization에 관련해서는 많은 문제가 있다.
- bounded buffer producer&consumer 문제 : 앞에서 살펴봤든 구현을 조금만 잘못해도 deadlock이 걸린다.
- reader-writer 문제 : read는 동시에 접근해도 괜찮지만 write는 독립적으로 수행되어야 한다.
- dining philosopher 문제 : 다음 포스팅에서 살펴볼 예정으로, deadlock과 starvation을 동시에 회피해야 한다.
Reader-Writer 문제
여러 process가 shared data를 본다고 하자. 이 때 reader들은 해당 shared data를 읽기만 하기 때문에 몇 개의 reader process가 shared data에 접근해도 값이 바뀌지 않기 때문에 문제가 없다. 반면 writer들은 shared data를 수정하기 때문에 mutual exclusive하게 shared data에 접근해야 한다.
따라서 한 번에 여러 개의 reader들은 shared data에 동시에 접근할 수 있는 반면, writer는 오직 하나만이 shared data에 접근해야 한다.
만약 read와 write가 동시에 shared data에 접근한 경우 어떻게 처리해야 할까? 2가지 해결법이 있고, 각각 문제가 있다.
1. writer에 더 높은 우선순위 주기
write부터 실행한 이후 read를 실행하는 방법이다. 이 경우 reader가 starvation을 겪을 수 있다.
2. reader에 더 높은 우선순위 주기
read부터 실행한 이후 write를 실행하는 방법이다. 이 경우 writer가 starvation을 겪을 수 있다.

위와 같이 코드를 작성해 reader-writer 문제를 reader에게 더 높은 우선순위를 주는 방식으로 해결할 수 있다.
- rw_mutex : write를 위해 사용하며, 1로 초기화한다. (lock으로 사용)
- reader가 하나라도 있으면 rw_mutex를 걸어 writer가 접근하지 못하게 한다.
- write 전후에 rw_mutex를 확인한다. 즉 reader가 없을 때만 write할 수 있게 한다.
- mutex : shared data인 read_count에 접근할 때 사용하며, 1로 초기화한다. (lock으로 사용)
- reader에서 read_count의 값을 바꿀 때 mutex를 얻어 다른 thread가 read에 접근하지 못하게 한다. read_count의 값을 바꾸면 mutex를 풀어준다.
- read_count : 동시에 접근중인 reader의 개수
잘못된 내용이나 오탈자에 대한 지적, 질문 등은 언제나 환영합니다.
'CS > OS' 카테고리의 다른 글
| [OS] Process Scheduling (0) | 2023.07.06 |
|---|---|
| [OS] Multiprocessor Synchronization & Deadlock (0) | 2023.07.04 |
| [OS] Synchronization - Lock, Condition Variable, Semaphore (0) | 2023.07.01 |
| [OS] Concurrency & Thread (0) | 2023.06.29 |
| [OS] Process (0) | 2023.06.26 |