![[OS] Synchronization - Lock, Condition Variable, Semaphore](https://img1.daumcdn.net/thumb/R750x0/?scode=mtistory2&fname=https%3A%2F%2Fblog.kakaocdn.net%2Fdn%2FdeYlnw%2FbtslR24dvzM%2F2qUCJXx5UoeefB31j0wC40%2Fimg.png)
이 글은 포스텍 박찬익 교수님의 운영체제(CSED312) 강의를 기반으로 재구성한 것입니다.
이 글에서는 synchronization의 개념에 대해 살펴본다.
딱 하나의 thread만 있는 경우 모든 instruction이 deterministric하기 때문에 아무런 문제가 없다. 그러나 multi thread 환경으로 concurrent 환경을 만들었을 경우, shared data에 대한 concurrent access가 race condition을 발생시키고, data inconsistency가 발생할 수 있다. 이 장에서는 이러한 현상을 어떻게 막을 수 있는지를 살핀다.
Atomic Operation
Race Condition
race condition은 shared data에 동시에 접근할 때, 접근/조작의 순서에 따라 다른 결과가 나올 수 있는 상태를 말한다.
이 때문에 multi thread를 관리하는 것이 어려워진다. 이를 막기 위해 각 thread의 shared data에 접근하는 operation을 atomic하게 만들어야 한다.


위 예시를 보자. thread A는 i++을 하고, thread B는 i--를 한다. 실행 순서가 왼쪽 그림처럼 될 경우 thread A가 실행 도중 thread B의 read i가 실행되어 thread B는 i가 0인 것으로 받아들이고 i의 결과는 -1이 된다. 그러나 실행 순서가 오른쪽 그림처럼 thread A의 실행이 끝난 후 thread B가 실행되면 i의 결과는 0이 된다. 이렇듯 shared data에 동시에 접근하고, 접근/조작의 순서에 따라 다른 결과가 나올 수 있기 때문에 이 상태는 race condition에 있는 상태다.
Atomic Operation
atomic operation은 작업 도중에는 interrupt되지 않고 해당 작업을 끝내거나 작업을 아예 하지 않는 operation을 말한다.
critical section(= atomic unit)은 오직 하나의 thread만이 실행하는 것이 보장되어야 하는 영역을 말한다. 둘 이상의 thread가 동시에 접근하면 안 되는, shared data에 접근하는 영역으로 이해해도 된다. 해당 영역의 instruction은 atomic하다.
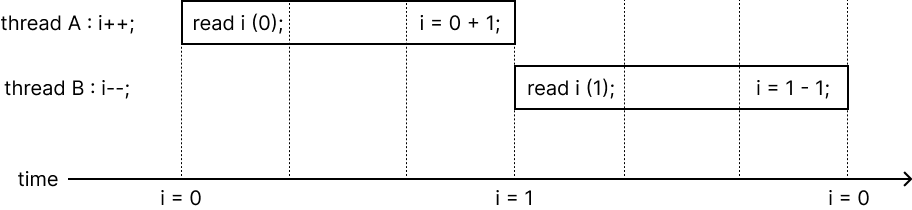
thread A와 thread B가 같은 critical section에 접근할 때, 하나의 thread가 먼저 실행된 후 다른 thread가 실행된다. - 즉, 실행 순서가 보장된다.
Atomic Operation의 필요성
- race condition을 해결해야 한다.
- thread scheduling은 어느 시점에서나 일어날 수 있기 때문에 shared data에 접근할 때는 모든 경우의 수를 고려해야 한다.
- instruction을 atomic하게 뒀더라도 하드웨어의 최적화 과정에서 instruction이 재배열될 수도 있다. 이러한 문제들을 해결하기 위해 memory barrier를 두어 특정 부분의 reordering만 막기도 한다.
Too Much Milk 문제
이 문제는 atomic operation 구현의 어려움을 보여주는 문제이다.
2개의 thread가 각각 우유를 하나씩 살 수 있다고 할 때, 단 하나의 우유만 사는 operation을 만들고 싶다. 어떻게 구현할까?
1. if문

위와 같이 코드를 짰다고 해 보자. 그러나 단순 if문 하나로는 critical section을 구현할 수 없다.
2. note와 2중 if

이 경우 1-2-3-4 순으로 실행되면 둘 다 우유를 사러 가지 않는 경우의 수가 존재한다. (starvation)
3. note와 while문

peterson solution이라고 불리는 하나의 해결 방법이며, 이 경우 잘 작동한다. 그러나 이렇게 짜면 너무 복잡하다. 여기서는 thread가 2개이지만 만약 thread가 10개이면 어떻게 되는가? 그만큼의 변수가 추가되어야 한다. 100개면? ... 또한, while문에서 CPU가 busy wait을 하기 때문에 성능도 나쁘다.
Lock
위에서 살펴봤듯 instruction들만으로 atomic operation을 구현하는 것은 매우 어렵다. 때문에 하드웨어 레벨에서 지원하는 lock을 이용해 아주 쉽게 atomic operation을 구현할 수 있다. lock을 가진 thread만이 operation을 실행할 수 있기 때문에 lock을 갖지 않은 다른 thread가 실행되는 것을 막아준다.

이러한 lock의 성질에 의해 atomic operation을 아주 간단하고, 오직 하나의 thread만 critical section에 접근함을 보장할 수 있으며(mutual exclusion), busy waiting도 없는 매우 좋은 해결 방법이다.
더 자세한 내용은 아래에서 살펴본다.
용어 정리
- race condition : shared data에 동시에 접근할 때, 접근/조작의 순서에 따라 다른 결과가 나올 수 있는 상태.
- atomic operation : 작업 도중에는 interrupt되지 않고 해당 작업을 끝내거나 작업을 아예 하지 않는 operation.
- critical section( = atomic unit) : 오직 하나의 thread만이 실행하는 것이 보장되어야 하는 영역을 말한다. 둘 이상의 thread가 동시에 접근하면 안 되는, shared data에 접근하는 영역이라 봐도 무방하다.
- mutual exclusion : 오직 하나의 thread만이 critical section에 접근함을 보장하는 것.
- synchronization : atomic operation을 이용해 multi thread로 인해 발생하는 data inconsistency와 race condition을 막는 것.
- lock : critical section에 들어가기 전에 lock acquire하고, critical section이 끝났을 때 lock release해 mutual exclusion을 보장하는 기법.
Synchronization - Shared Object 구현
multi thread에서 사용하는 shared data를 프로그래머가 직접 관리하는 것은 어렵고 위험부담이 많기 때문에 shared data를 모듈화한 shared object로 발전했다. shared object는 atomic하게 구현되어 있기 때문에 multi thread 환경에서 race condition이나 data inconsistency를 고려하지 않아도 되는 object이다. 여기부터는 shared object의 구현에 대해 살펴본다.

이러한 방법에서 multi thread program을 thread와 shared object로 나눌 수 있으며, shared object의 구현을 위해 detail인 state variable과 synchronization variable을 숨기고 깔끔한 public interface method를 제공하게 만들 것이다.
Big Picture

shared object는 위와 같이 크게 3가지 layer로 이루어져 있으며, 위의 layer가 더 추상화된 layer이다.
- shared object layer : 모든 shared object들은 single thread program와 같은 인터페이스를 제공한다.
- synchronization variable layer : synchronization variable은 shared state에 대한 동시 접근을 처리하는 데 사용하는 자료구조이다.
- atomic instruction layer : synchronization variable이 사용하는 하드웨어 레벨 instruction.
Lock
lock은 아래 2개의 operation이 있다.
- acquire() : lock이 free될 때까지 기다리며, free가 되면 lock을 가져온다.
- release() : lock release하고 lock을 기다리는 thread를 깨운다.
Lock의 특징
- safe & mutual exclusion : 어떤 thread가 lock을 가지고 있다면 다른 thread는 lock을 가지고 있지 않기 때문에 해당 thread가 release하기 전까지는 해당 thread만 실행하는 것을 보장한다. 또한 2개의 thread가 동시에 lock acquire를 하더라도 오직 하나의 thread만이 lock을 acquire한다.
- progress : lock을 아무도 가지고 있지 않다면 acquire()로 바로 lock을 얻을 수 있다.
- bounded wait : acquire()했을 때 해당 thread보다 priority가 높은 thread가 없고, lock free라면 해당 thread는 lock을 얻는다.
사용 방법
lock.acquire();
// critical section. 이 critical sectoin은 lock에 의해 mutal exclusion을 보장받는다.
lock.release();위 코드처럼 shared data에 접근하기 전에 acquire()하고, shared data에 접근한 후에 release()하면 된다.
예시 : synchronized queue

synchronized queue, 즉 여러 thread에서 사용할 수 있는 queue를 구현한다고 해 보자.
여기서 shared data는 queue이므로 queue에 접근하는 부분이 critical section이다. 따라서 queue에 접근하기 전에 lock acquire하고, queue에 접근한 후에 release하면 된다.
Condition Variable
lock을 가지고 있는 도중에는 sleep할 수 없다. 이를 해결하기 위해 conditional variable이 만들어졌다. condition variable은 critical section 내부에서 waiting하고 있는 thread queue이다.
아래 3개의 operation이 있다. condition variable은 shared data의 synchronization을 위한 것이기 때문에 wait(), signal(), broadcast()를 호출할 때는 항상 lock을 acquire한 상태여야 한다.
- wait() : [lock release + sleep]한 후, 누군가가 깨우면 lock을 다시 얻는다.
- 이 때 [lock release + sleep]는 하나의 atomic operation이다. (sleep + release면 lock을 가진 채로 sleep하기 때문)
- signal() : waiting thread가 있다면 깨운다. 없다면 아무 것도 하지 않는다.
- broadcast() : 모든 waiting thread를 깨운다.
추가로, condition variable은 memoryless이기 때문에 이전에 signal()이 왔든 안왔든 상관없이 wait()가 호출되면 무조건 sleep해야 하고, signal()이 온 경우 waiter는 무조건 깨어나야 한다. (내부에 저장되는 정보가 없으므로 현재의 상태에만 영향을 받는다)
Mesa Style / Hoare Style
만약 어떤 thread Caller가 signal()로 다른 thread Callee를 깨웠다고 가정해 보자. 이 때, Caller가 계속 실행될지, Callee가 계속 실행될지에 따라 Mesa style인지 Hoare style인지 나눈다.
- mesa style : caller가 계속 실행된다. waiter를 ready list에 넣고 caller가 lock을 가지고 있기에 계속 실행된다.
- hoare style : callee가 실행된다. waiter에게 lock과 processor를 준다.
이렇게 나누는 이유는 둘 중 어떤 방법을 사용하냐에 따라 wait()에 while을 사용하냐 마냐가 결정되기 때문이다. 아래에서 서술하겠지만 mesa style의 경우 watier가 ready list에 들어가기 때문에 ready list에 들어간 시점부터 thread 실행시점까지 wait condition이 달라질 수도 있기 때문에 while을 사용해야 한다.
반면 hoare style의 경우 waiter가 바로 실행되기 때문에 wait condition이 무조건 만족된 상태이기 때문에 while을 사용할 필요가 없다. (if만 써도 된다.)
여기서는, 그리고 대부분은 mesa style을 사용한다.
Squrious Wakeup
signal()을 받아 sleep하던 thread가 깨어났음에도 기다리고 있던 조건이 충족되지 않은 것을 squrious wakeup이라고 한다.
condition variable을 사용할 때, wait()를 호출했다면 다른 thread로부터 signal()을 받기 전까지 계속 sleep한다. 이 때 wait()를 호출한 thread가 signal()을 받아 깨어났더라도 해당 thread가 바로 실행되는 것이 아니라 ready list에 들어가기 때문에 [ready list에 들어간 순간 ~ 해당 thread의 실행 시점]에 다른 thread가 lock을 얻는 등의 이유로 접근하고자 했던 shared data에 변화가 생겼을 수도 있다. 이 상태가 squirous wakeup이며, 이를 막기 위해 wait()를 while문 안에 넣는 것을 권장한다.
예시 : synchronized queue

- AddToQueue()의 condition.signal()은 해당 condition을 기다리고 있는 waiter가 있는 thread를 깨운다. 즉, queue에 무언가가 들어갔다는 것을 알린다.
- RemoveFromeQueue()의 condition.wait()는 lock을 release하고 sleep한다. 이후 signal()에 의해 다시 깨어났을 경우 lock을 다시 acquire해야만 critical section에 접근할 수 있다는 것을 기억해야 한다.
- condition.wait()를 쓴 부분을 보면 while문을 쓴 것을 볼 수 있다. signal()을 받지 않았음에도 scheduler에 의해 thread가 깨어나는 squrious wakeup을 막기 위함이다. 위 예시에서 while문을 사용하지 않았다면 wait()가 끝나 빈 queue에서 pop()을 하는 오류가 생길 수 있다.
정리
- concurrent하게 접근되는 object를 찾고, 그 object에 접근하기 전/후에 lock acquire(), release()를 작성해야 한다. + lock release인 상태거나 waiting일 때는 그 object에 접근하지 않아야 한다.
- 만약 condition wait를 해야 한다면, while(waitCondition()) { conditiona.wait(); }와 같이 조건문이 걸린 while문으로 작성해야 한다.
- wait()에 의해 sleep 중인 thread를 깨우고 싶다면 signal()을 사용한다.
- condition variable을 사용할 때는 언제나 lock acquire한 상태여야 한다.
Semaphore
semaphore는 일반화된 lock이며, 아래 2개의 atomic operation과 하나의 음수가 아닌 정수로 구성되어 있다.
- P() : semaphore 값이 양수가 될때까지 기다리며, 양수가 되면 1을 빼는 atomic operation이다. wait()와 유사하다.
- V() : semaphore 값에 1을 더하고 P()를 호출한 thread가 있다면 깨운다. signal()과 유사하다.
Semaphore 구현
semaphore는 아래 2가지로 구현되어 있다.
- semaphore는 같은 semaphore에 대해 P()와 V()를 동시에 실행할 수 없어야만 한다. 따라서 P(), V()는 critical section에 와야 한다.
- critical section에서 busy waiting을 한다. 따라서 busy waiting이 괜찮을 정도로 critical section의 접근이 적어야 한다.
따라서 critical section에 오래 있는 프로그램이라면 좋은 해결책이 아니다는 것을 명심해야 한다.
Semaphore 용도
lock과 다르게 어떤 값으로 초기화되냐에 따라 2가지 용도로 사용된다.

- mutual exclusion : 1로 초기화
- 왼쪽 그림처럼 0으로 초기화하면 오직 하나의 thread만 해당 semaphore를 사용할 수 있다.
- coordination : 0으로 초기화 (순서 보장)
- 오른쪽 그림처럼 0으로 초기화하면 실행 순서를 보장하게 만들 수 있다.
- 위에서는 thread join과 finish를 예로 든다. thread join의 경우는 thread terminate가 될 때까지 기다려야 한다. semaphore 값을 0으로 초기화하면 P()를 호출한 thread join은 V()가 호출될 때까지 기다린다. 이 때 V()는 thread terminate에서 호출한다. 따라서 thread terminate 이후 thread join이 호출되는 것을 보장한다.
- 이처럼 scheduling 순서를 보장하는 것을 scheduling constraints라고 한다.

scheduling contraints 예시이다. 위 예시의 경우 무조건 T1 - T2 - T3 순서로 실행된다.
예시 : producer-consumer 문제
buffer에 값이 있다면 사용하는 consumer thread와 buffer에 값이 없다면 생성하는 producer thread가 있고, buffer가 shared data여서 오직 하나의 thread만 buffer에 접근할 수 있을 때 이를 semaphore만으로 어떻게 구현할지에 대한 문제이다.
문제를 다음 조건으로 나누면, 필요한 semaphore는 다음 3가지이다.
- producer는 buffer가 가득 차 있다면 consumer가 값을 사용할 때까지 기다려야 한다. scheduling constraint이므로 BUFFER_SIZE로 초기화된 canProduce semaphore를 사용한다. 0인 경우 buffer가 가득 찬 것이다.
- consumer는 buffer가 비어있다면 producer가 buffer에 값을 넣기까지 기다려야 한다. scheduling constraint이므로 0으로 초기화된 canConsume semaphore를 사용한다. 0인 경우 buffer가 빈 것이다.
- 오직 하나의 thread만 buffer에 접근할 수 있다. mutual exclusion이므로 1로 초기화된 mutex semaphore를 사용한다.

- buffer는 shared data이므로 critical section 내에 위치해야 한다. 앞서 설명했듯 semaphore로 mutual exclusion을 구현하기 위해서는 1로 초기화한 mutex semaphore를 사용하므로 mutex.P(), mutex.V() 2개 operation 사이에 critical section을 집어넣는다.
- Producer()
- canProduce semaphore는 0인 경우 buffer가 가득 찬 경우이다. 따라서 canProduce.P()를 호출해 빈 공간을 확인하고, 0이 아니라면(빈 공간이 있다면) 다음 명령어를 실행한다. 0인 경우 canProduce.V()가 올 때까지 기다린다.
- item 생성 이후에는 canConsume.V()로 "item을 생성했다"는 것을 conConsume에게 알린다.
- Consumer()
- canConsume semaphore는 0인 경우 buffer가 빈 경우이다. 따라서 canConsume.P()를 호출해 buffer에 값이 있는지 확인하고, 0이 아니라면(비어있지 않다면) 다음 명령어를 실행한다. 0인 경우 canConsume().V()가 올 때까지 기다린다.
- item 생성 이후에는 conProduce.V()로 "item을 소비했다"는 것을 canProduce에게 알린다.
잘못된 풀이는 아래와 같다.

제일 처음에 Producer thread에서 mutex를 가진 상태로 canConsume.V()를 호출해 Consumer thread를 깨우는 경우를 생각해 보자. 그러나 Consumer thread는 mutex를 가지고 있지 않기 때문에 lock을 계속 기다리게 된다. 그러면 다시 Producer thread로 control flow가 넘어간다. 마찬가지로 canConsume.V()가 호출되어도 consumer thread는 mutex를 가지지 않으므로 계속 기다린다. ... 이게 반복되어 buffer가 가득 차게 되고, Producer thread가 canProduce.P()를 호출한다. 이러면 완벽한 deadlock이 걸린다. Consumer thread는 계속 mutex를 가지지 않기 때문에 canProduce.V()를 호출할 수 없고, Producer thread는 canProduce.P()에게 signal이 오기를 기다리는 상태가 되어 무한루프가 돌게 된다.
이처럼 2개 이상의 thread/process가 서로의 작업이 끝나기를 기다리는 상태인 deadlock이 걸린다.
Monitor
monitor는 하나의 lock과 0개 이상의 condition variable을 사용해 shared data에 대산 concurrent한 접근 관리를 위한, 높은 추상화를 가진 도구이다. shared object와 유사하지만 명시적으로 lock을 사용할 필요가 없어 더 쉽게 synchronization을 처리할 수 있다. lock은 mutual exclusion을 위해, condition variable은 scheduling을 위해 사용한다.
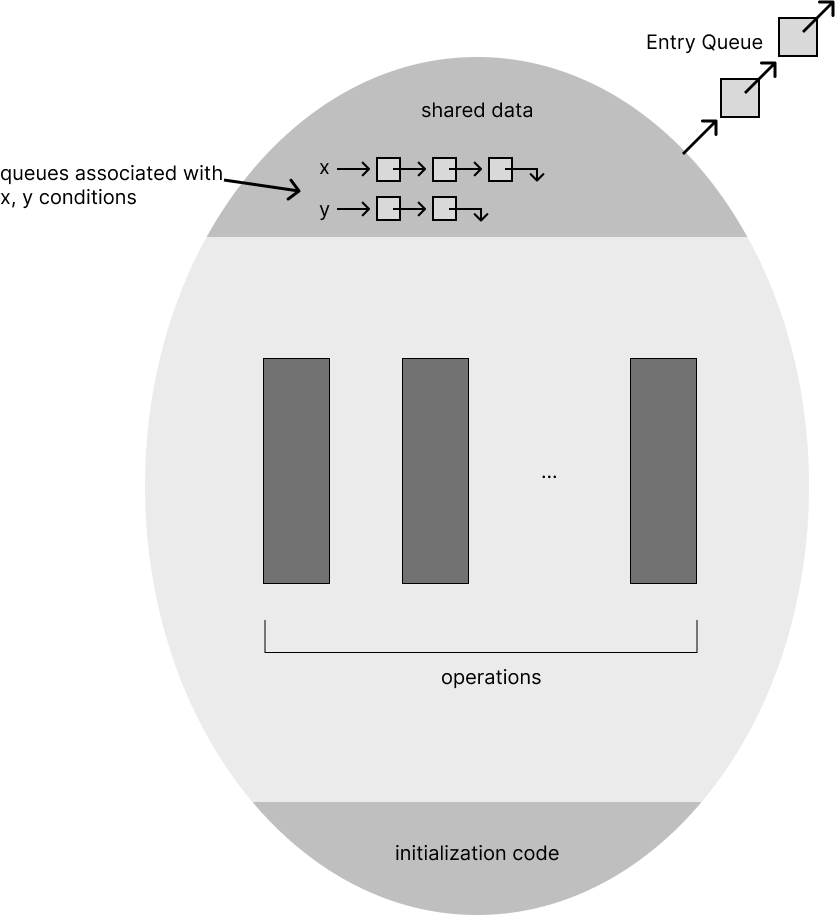
monitor는 위 그림과 같이 shared data, condition variables, operations, initialization code, entry queue(lock queue)로 이루어져 있다. 이 때 signal()로 다른 thread를 깨울 때 내부적으로 prioirty를 두어 해당 순위가 높은 것을 깨운다.
- 각 operation은 lock에 의해 mutual exclusion에 의해 실행된다.
- 다른 thread가 lock을 가지고 있다면 lock acquire까지 wait한다.
- operation을 실행하며 condition에 맞지 않는다면 기다린다.
잘못된 내용이나 오탈자에 대한 지적, 질문 등은 언제나 환영합니다.
'CS > OS' 카테고리의 다른 글
| [OS] Multiprocessor Synchronization & Deadlock (0) | 2023.07.04 |
|---|---|
| [OS] Implementing Synchronization (0) | 2023.07.01 |
| [OS] Concurrency & Thread (0) | 2023.06.29 |
| [OS] Process (0) | 2023.06.26 |
| [OS] Operating System Overview (0) | 2023.06.25 |