![[OS] Multiprocessor Synchronization & Deadlock](https://img1.daumcdn.net/thumb/R750x0/?scode=mtistory2&fname=https%3A%2F%2Fblog.kakaocdn.net%2Fdn%2FDycdz%2FbtsmteIEadm%2FBkaXZi9hGVl9G2Z39E8vJ0%2Fimg.png)
이 글은 포스텍 박찬익 교수님의 운영체제(CSED312) 강의를 기반으로 재구성한 것입니다.
지난 포스팅에서 lock 등을 사용해 synchronization을 사용하는 방법을 알아보았다. 그러나 이 방법은 lock을 사용하기 때문에 multi processor에서는 효율이 나쁘다. 이 글에서는 어떻게 이를 해결하는지, 그리고 resource의 요청이 꼬였을 때 발생하는 deadlock에 대해 알아본다.
Multiprocessor Synchronization
multi processor 환경에서 많은 thread를 가진 프로그램은 효율이 좋지 않다.
- lock contention : 한 번에 단 하나의 thread만 lock을 가질 수 있기 때문이다.
- cache ping : lock에 의해 보호받는 shared object의 cache가 여러 process를 왕복하기 때문에 cache 효율이 나쁘다.
- false share : 공유되지 않는 데이터들도 processor 간에 통신한다.
Multiprocessor Cache Coherence
cache coherence는 각 processor의 cache가 일관성있게 유지되는 것을 말한다. memory data의 cache가 단 하나만 있는 것처럼 행동하기 때문에 cache를 매번 초기화할 필요가 없어지며, multi processor synchronization 효율을 높일 수 있다.
- 데이터를 읽을 때는 값이 변하지 않기 때문에 사본을 계속 만들어도 된다.
- 데이터를 수정할 때는 수정한 cache만 유효하다.
Cache State Machine

각 process의 cache 상태 및 transition를 나타낸 그림이다.
- peer write : 다른 peer가 값을 수정한 경우. read-only인 cache는 값이 변했기 때문에 invalid가 되고, write-only였던 cache 또한 값이 변했기 때문에 invalid가 된다.
- peer read : 다른 peer가 값을 읽은 경우, write-only였던 cache는 다른 peer가 그 값을 보고 있기 때문에 더 이상 수정할 수 없다. 따라서 read-only가 된다.
이 cache들의 상태를 알아내고 어디에 있는지 어떻게 알까? 이는 하드웨어가 계속 관리해 준다.
- read miss인 경우 : write-only가 있다면 그 값의 사본을 가져오고, 다른 read-only인 모든 사본을 invalid로 바꾼다.
- write-miss인 경우 : 모든 사본을 invalid로 바꾼다.
Reducing Lock Contention : 새로운 lock 구현
cache도 성능에 영향을 끼지치만, lock contention 또한 큰 영향을 미친다. 크게 아래 3가지 방법이 있다.
- fine-grained locking : shared object를 나누고 나눈 부분에 각각 lock을 적용하는 방법.
- per-processor data structure : 모든 접근이 하나의 processor에서만 가능하도록 만드는 방법.
- ownership/staged architecture : MCS lock. 한 번에 하나의 thread만 shared data에 접근할 수 있다. queue로 lock을 관리한다.
이러한 방법을 적용했는데도 lock contention이 계속 발생한다면 다음과 같은 방법을 취한다. 이 두 방법은 atomic intruction인 read-modify-write를 사용한다.
- MCS lock : lock 구현 최적화
- Read-Copy-Update : 읽기가 대부분인 상황에서 사용하는 동기화 방법. writer는 reader가 끝난 후에만 값을 변경할 수 있다.
Test-And-Set의 문제점

- 너무 많은 cache traffic : 위 예시는 test-and-set을 multi processor에서 사용했을 때 cache에서 일어나는 일이다. test-and-set은 항상 cache write를 하기 때문에 다른 processor의 모든 cache를 invalidate한다. 위 예시에서 모든 test-and-set에서 cache invalidate를 하는 것을 볼 수 있다.
- lock의 FIFO ordering을 보장하지 않음 : lock의 FIFO ordering을 보장하지 않기 때문에 특정 processor가 lock을 얻지 못한다면 너무 오래 기다려야 할 수도 있다. (starvation)
Test-&-test-and-set
기존 test-and-set에 lock이 busy인지 여부를 검증하는 로직만 추가한 방법이다. 이 방법은 lock을 먼저 확인한 후 test-and-set을 실행하기 때문에 cache coherence traffic은 막아주지만 여전히 FIFO ordering은 보장하지 않는다.
Ticket Lock

bakery algorithm와 유사한 알고리즘이다. 여기서 fetch_and_increment는 ticket의 원래 값을 리턴하고 인자로 1 더해주는 atomic instruction이다.
- lock : 현재 tiket이 자신의 ticket일 때까지 wait한다.
- unlock: now_serving++한다.
ticket lock을 적용하면 cache coherence traffic도 줄고, FIFO ordering을 보장한다. 단, 각 processor가 shared variable now_serving을 사용하기 때문에 lock을 얻는 시간이 O(processor 개수)이다.
MCS lock
ticket lock의 단점인 lock을 얻는 시간을 해결하기 위해 MCS lock을 사용한다. MCS lock은 lock을 기다리는 thread list(queue)를 사용하는 방법이다.
TCB에 local variable인 neetToWait 변수를 추가하고 이 변수가 true이면 wait하고, 그렇지 않다면 lock을 얻는 방식으로 구현한다. lock release할 때 queue.front()에 있는 thread의 neetToWait를 false로 설정하는 방식이다.
RCU (Read-Copy-Update)
아예 다른 접근방식으로, 읽기가 대부분인 상황에서 사용하면 좋은 동기화 방법. writer는 reader가 끝난 후에만 값을 변경할 수 있다. reader에게 더 높은 우선순위를 주어 같은 조건에서 read를 먼저 실행하는 방법이다.
write는 lock을 얻어야 쓸 수 있지만 read는 lock을 얻지 않고도 접근할 수 있다.

위 그림은 RCU lock의 예시이다.
- 1번 시점 : write가 값을 쓰려고 한다. 그렇지만 write가 끝나기 전까지는 read operation들은 lock을 기다리지 않고 바로 읽는다. 때문에 3번 시점 전에 read operation을 수행한 thread 1, thread 2의 값은 'old'이다.
- 1번 시점 ~ 2번 시점 : write를 시작했지만 아직 끝나지 않은 상태이다. 이 때 thread 3, thread 4의 read operation도 lock을 기다리지 않고 바로 읽는다. 그렇지만 old를 읽을지 new를 읽을지는 구현에 의존한다.
- 2번 시점~ : write가 끝난 시점이다. 이 때 write operation은 lock을 얻고 수행한다. 이후의 모든 read operation은 new인 것이 보장된다.
- 3번 시점 : write가 끝나기 전에 read한 operation이 끝나는 지점이다. 여기서부터는 더 이상의 pending read가 없는 것 + write가 끝난 것이 보장된다. 때문에 원래 있던 old를 삭제한다.
위 그림에서 grace period라는 것이 있다. [write operation이 끝나는 시점 - grace period는 write operation이 시작되었을 때부터 끝나기 전에 수행된 read operation이 끝나는 시점]의 구간을 말하며, 이 때 read는 old copy를 읽을 수도 있고 new copy를 읽을 수도 있기 때문에 scheduler가 잘 관리해 주어야 한다.
Deadlock
deadlock은 2개 이상의 작업이 resource를 할당받기 위해 circular waiting을 하고 있는 상황이다. 서로의 작업이 끝나기만을 기다리지만 각자의 작업이 끝나지 않기 때문에 무한루프에 걸린 것처럼 계속 기다린다.
- resource : thread가 작업을 하기 위해 필요한 모든 것. CPU, disk 공간, memory, lock 등. 아래 2가지 종류가 있다.
- preemptable : OS에 의해 해당 resource가 free될 수 있다.
- non preemptable : 해당 resource를 가진 thread가 자원을 직접 놓아야 해당 resource가 free된다.
- starvation : thread가 무한히 기다리는 상태. scheduling할 때 계속 새치기를 당하는 경우가 한 예시이다.
deadlock은 starvation이지만, starvation은 deadlock이 아니다.
예시

위 예시를 보자. 두 thread의 첫 번째 줄이 실행되고 thread A가 lock1을, thread B가 lock2를 가져갔다고 가정하자. 이 때 thread A는 lock2를 기다리고, thread B는 lock1을 기다린다. thread A와 thread B 모두 자신이 가진 lock을 해제하지 않기 때문에 무한히 기다리는 deadlock에 걸린다.
Dining Philosophers Problem
문제는 다음과 같다.

- 5명의 철학자가 있다. 철학자는 아무것도 하지 않거나, 먹거나 2가지 행동을 할 수 있다. 철학자는 원형 테이블에 앉아 있다.
- 각자의 앞에는 음식이 있다.
- 총 5개의 젓가락이 있다. 젓가락은 철학자들의 사이에 위치한다.
- 철학자는 먹기 위해 2개의 젓가락을 사용해야 하며, 한 번에 하나의 젓가락만 집거나 내려놓을 수 있다.
- 한 번에 한 사람의 철학자만 움직일 수 있으며,
이 때 모든 사람이 음식을 먹기 위해 자신의 왼쪽에 있는 젓가락을 집었다고 생각해 보자. 모든 사람이 음식을 먹기 위해 젓가락을 집고 있는 과정인데, 더 이상 남은 젓가락이 없다. 모든 사람은 다른 사람이 젓가락을 내려놓기만 기다리고 있지만, 동시에 모든 사람은 젓가락을 내려놓을 수 없다. deadlock이다.
Deadlock의 4가지 조건
deadlock은 아래 4가지 조건이 모두 달성되었을 때 발생한다. 하나라도 만족하지 않으면 deadlock은 발생하지 않는다.
- 한정된 resource : 만약 resource가 무한하다면 deadlock은 발생하지 않는다.
- non preemption : resource를 빼앗아 올 수 있다면 deadlock은 발생하지 않는다.
- hold and wait : 자신의 resource를 점유한 상태로 resoure를 기다린다.
- circular wait : hold and wait의 연장. resource를 기다리는 상태가 cycle을 이루고 있는 상태를 말한다.
Deadlock 처리
위 4가지 조건 중 하나라도 만족하지 않으면 deadlock은 발생하지 않기에 deadlock을 막기 위해서는 위 조건을 막으면 된다. 크게 아래 3가지가 있다.
- prevent : 조건 중 하나를 유효하지 않게 만든다. 발생 자체를 막는 방식이다.
- avoid : deadlock이 발생할 수 있지만, 적당히 순서를 조절해 deadlock이 발생하지 않게 한다.
- detect & cover : deadlock이 발생한 경우 정지한 후 복구한다.
Prevent
조건을 유효하지 않게 만드는 방법이다.
- 충분한 resource 제공 : 한정된 resource를 막기 위해 충분한 resource를 제공한다. 단 이 방법은 유효하지 않을 수도 있다.
- holding 중에는 wait 불가능하게 변경 : hold and wait를 바꾼다. resource를 가지고 있다면 wait하지 못하게 한다.
- circular waiting 제거
Avoid : Banker's Algorithm
deadlock이 발생할 수 있지만 적당히 순서를 조절해야 하기 때문에 예측해야만 한다. 이를 위해 많은 모델들을 사용한다.
System Model
system을 크게 2종류로 나눈다.
- Resource R$_1$, R$_2$, ... , R$_m$
- 각 resource R$_i$는 W$_i$개의 instance를 가진다.
- 모든 process는 resource에 대해 3가지 type을 가진다. Request, Acquire, Release가 그것이다.
- Request : process → resource edge. 아래 그림의 위쪽 2번째 edge가 예시이다.
- Acquire : resource → process edge. 아래 그림의 아래쪽 edge가 예시이다.
- Release : nothing
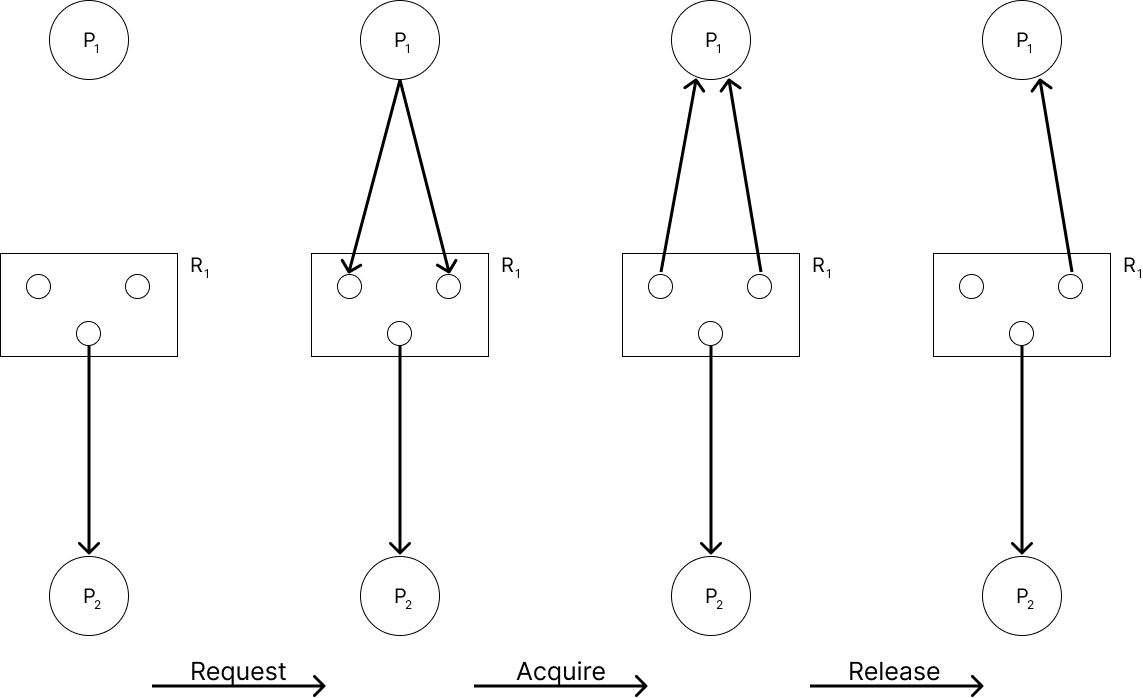
위 그림은 request - acquire - release 3가지 순서를 나타낸다. 2번째 그림에서 P$_1$이 R$_1$의 resource를 요청한다. 3번째 그림은 resource를 할당받은 모습을, 4번째 그림에서는 할당받은 resource 하나를 release한 모습을 나타낸다.
RAG, Resource Allocation Graph
위 모델을 이용해 graph를 그릴 수 있다. process와 resource를 vertex로, allocation type을 edge로 graph를 그릴 수 있다.
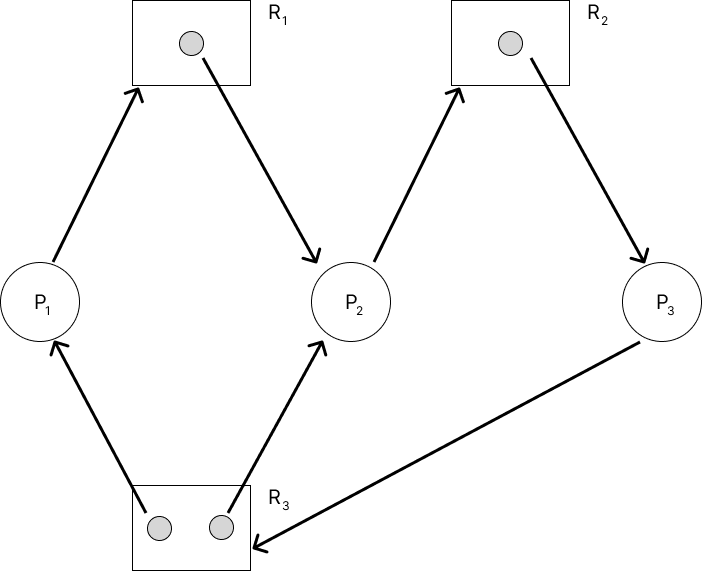
이 때 cycle의 여부에 따라 deadlock 여부를 볼 수 있다.
- cycle이 없는 경우 : deadlock이 없다.
- cycle이 있는 경우
- resource의 instance가 하나이면 deadlock이다.
- resource의 instance가 여러 개이면 deadlock일 수도 있고, 아닐 수도 있다.
즉, deadlock이 있다면 RAG cycle이 존재하지만 RAG cycle이 deadlock을 의미하는 것은 아니다.
Deadlock Detection Data Structure
deadlock을 감지하기 위해 하나의 자료구조를 만든다.
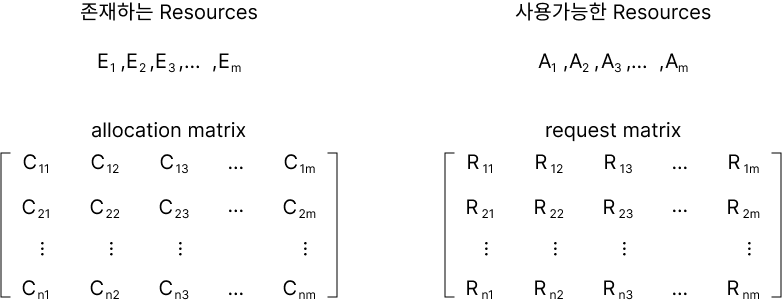
C$_{ij}$는 thread i가 현재 resource j를 할당받은 것을 의미하며, R$_{ij}$는 thread i가 필요한 resource가 resource j에 있다는 것을 의미한다.
Deadlock Dynamic

safe state는 어떤 request sequence도 deadlock이 일어나지 않는 상태를, unsafe state는 어떠한 resource request의 순서가 deadlock을 발생시킬 수 있는 상태를 의미한다.
이로부터 아래 2가지 성질을 끌어낸다.
- safe state에 있는 시스템은 deadlock이 발생하지 않는다.
- safe state에서 delay를 해도 unsafe state로 가지 않는다.
이를 이용해 avoid algorithm을 짠다. 만약 현재 state로부터 request를 할당받았는데 unsafe state로 갈 경우 해당 request를 delay하고, 그렇지 않는 경우 계속 request를 한다.
Banker's Algorithm
n은 process 개수, m은 resource type 개수일 때 아래와 같은 4가지 변수를 둔다.
- available : length m array. avail[j] = k는 R$_j$에서 k개의 instance가 사용가능하다는 것을 의미한다.
- max : n by m matrix. max[i][j] = k는 process P$_i$가 resource type R$_j$의 instance를 최대 k개 요청한다는 것을 의미한다.
- allocation : n by m matrix. alloc[i][j] = k는 process P$_i$가 resource type R$_j$의 instance를 현재 k개 가지고 있다는 것을 의미한다.
- need : n by m matrix. need[i][j] = k는 process P$_i$가 resource type R$_j$의 instance를 k개 필요로 한다는 것을 의미한다.
- need[i][j] = max[i][j] - alloc[i][j]

wouldBeSafe()는 요청이 있을 때 safe할 때까지 기다린 이후에 할당한다.

wouldBeSafe()의 구현 내용이다. wouldBeSafe()는 해당 request가 써도 되는지 검사하는 함수이며, request를 빼 보고 그 상태로 safe 여부를 판단하는 isSafe()를 호출해 안전한지 여부를 확인한다. 이후 원래대로 돌리고 리턴한다.
isSafe()의 finish는 검사여부를 의미한다. 즉, 검사하지 않은 resource가 있는 경우 + need가 avail보다 작은 resource가 있는 경우 한 번 할당해 보고, 할당 가능하다면 true를 리턴한다. 그렇지 않다면 false를 리턴한다.
Detect & Recover
deadlock의 발생을 허용하되, 발생 시 감지하고 그것을 해제하는 방식이다.
- graph scah
- cycle 감지
- fix cycle - process를 종료하거나 자원을 뺏는 방식으로 진행한다.
이 때 모든 연산을 transaction으로 두어 rollback할 수 있다.
잘못된 내용이나 오탈자에 대한 지적, 질문 등은 언제나 환영합니다.
'CS > OS' 카테고리의 다른 글
| [OS] Address Translation (0) | 2023.07.15 |
|---|---|
| [OS] Process Scheduling (0) | 2023.07.06 |
| [OS] Implementing Synchronization (0) | 2023.07.01 |
| [OS] Synchronization - Lock, Condition Variable, Semaphore (0) | 2023.07.01 |
| [OS] Concurrency & Thread (0) | 2023.06.29 |