![[OS] Concurrency & Thread](https://img1.daumcdn.net/thumb/R750x0/?scode=mtistory2&fname=https%3A%2F%2Fblog.kakaocdn.net%2Fdn%2FrWc2e%2FbtslMWhEING%2FBQOow8YJsW7X1mRN5AF7hK%2Fimg.png)
이 글은 포스텍 박찬익 교수님의 운영체제(CSED312) 강의를 기반으로 재구성한 것입니다.
이 글은 OS의 concurrency와 thread를 다룬다.
한 프로그램은 여러 개의 이벤트를 동시에 처리해야 할 수 있어야 한다. 앞에서 살펴본 내용으로는 process가 concurrency를 지원하기 때문에 여러 개의 process를 사용하면 concurrency를 처리할 수 있을 것이다. 그러나 process의 생성 cost가 클 뿐아니라 process끼리는 독립된 자원을 사용하기 때문에 상호작용도 어렵다. 이를 해결하기 위해 나온 것이 thread이다.
Thread
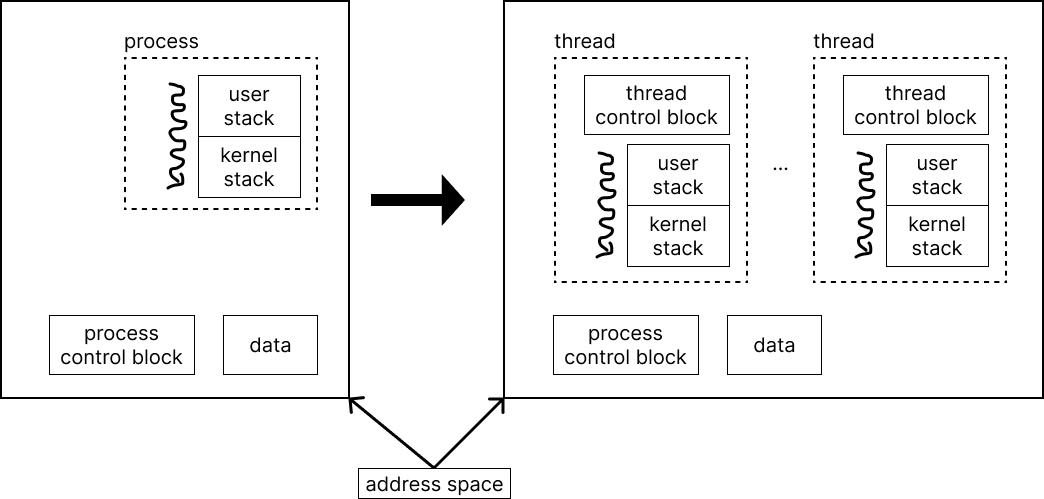
위에서 문제삼은 내용을 해결하기 위해 process를 thread와 address space 2개로 나눈다.
- thread : process 내에서 실행되는 실행 단위. concurrency를 encapsulate한다.
- address space : 해당 프로그램이 접근할 수 있는 모든 주소. thread들은 따로 실행되기에 실행에 필요한 stack과 register만 따로 가지고 있고 heap, data, code는 공유한다. protection을 encapsulate한다.
이렇게 바꾸면 thread는 process보다 더 적은 공간을 사용하기에 생성 cost가 더 적고, context switch에 필요한 cost도 더 적다. 또한 thread는 heap, data, code를 공유하기에 thread 간의 자원 공유가 훨씬 쉽다.
Thread Concurrency Abstraction
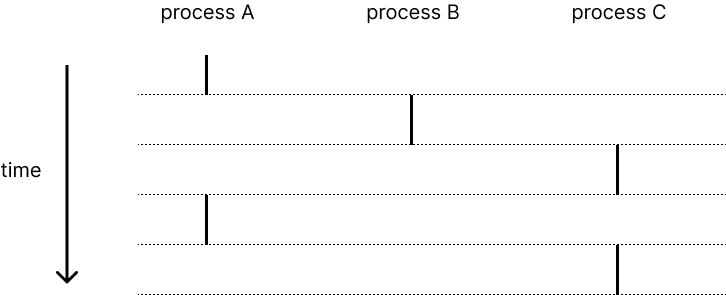
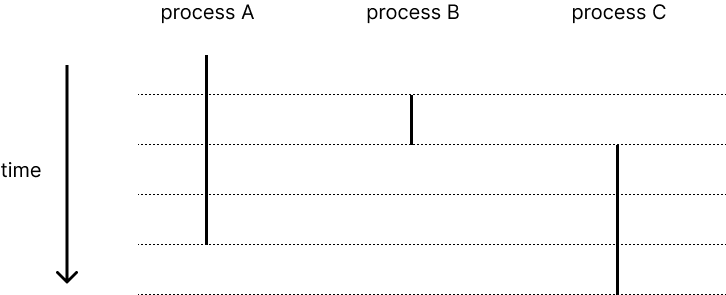
Exception Control Flow & Process 포스팅에서 [실제로는 각 process의 instruction을 조금씩 수행하지만(concurrent) 사용자는 각 process가 parallel하게 작동하는 것처럼 본다]고 했다. thread도 이와 동일하다.
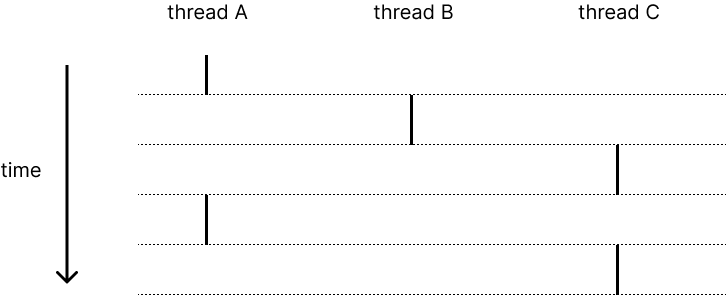
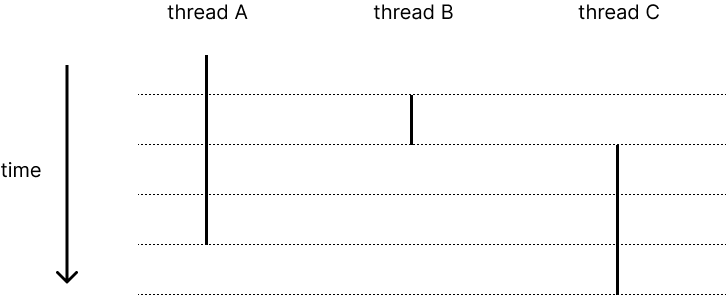
각 thread는 자신이 CPU를 독점하고 있는 것처럼 작동한다. 그러나 실제로는 thread 간의 context switching이 일어나면서 CPU가 각 thread를 번갈아 실행하지만 thread는 이 사실을 모른다. 이것이 thread abstraction이다.
Thread Control Block
Process 포스팅에서 process context를 저장하기 위해 process control block을 사용했던 것처럼 thread context를 저장하기 위해 thread control block, TCB를 사용한다. 저장하는 정보는 다음과 같다.
- stack information & stack
- register
- thread metadata : thread의 정보 요약. thread ID, scheduling priority, thread status, program counter 등
앞에서 언급했듯 thread는 실행에 필요한 stack과 register만 따로 가지고 있고 heap, data, code는 process의 것을 공유하므로 PCB보다는 훨씬 가볍다.
Thread Lifecycle
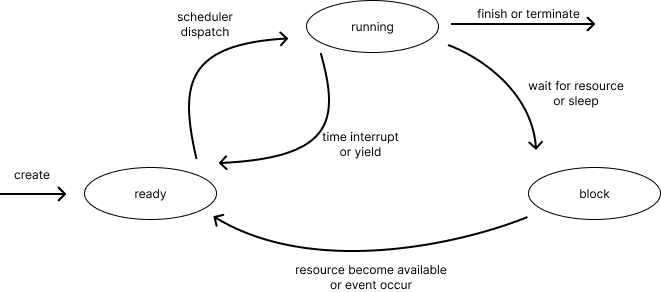
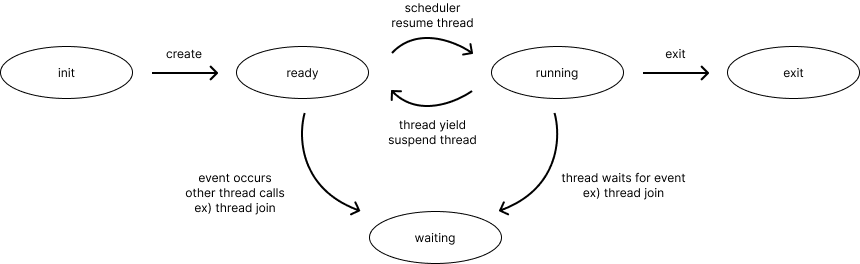
process와 thread가 유사한 개념이기에 lifecycle transition 또한 매우 유사한 것을 확인할 수 있다.
- ready → running : scheduler가 해당 thread를 실행시키기로 했을 때
- running → ready : yield했을 때
- running → block / running → waiting : event나 resource를 기다리기 위해 대기할 때
- block / waiting → ready : event가 발생하거나 해당 process/thread가 호출되었을 때
Thread Operations in Kernel
크게 아래 4가지가 있다. 여기서는 kernel thread operation만 살펴보는데, thread의 생성 및 관리는 privileged operation이기 때문이다.
- thread_create(thread, func, args) : argv로 받은 parameter를 func 함수에 넣어 thread로 실행한다.
- thread_yield() : 자발적으로 실행 순서를 양보한다.
- thread_join(thread) : parent thread인 경우 forked thread, 즉 child thread가 exit하길 기다린 후 리턴한다.
- thread_exit(exit_code) : thread를 삭제하고 자원을 정리한다. joiner가 있다면 exit_code를 전달한다.
예제
#define NTHREADS 10
thread_t threads[NTHREADS];
void go(int n){
printf("Hello from thread %d\n", n);
thread_exit(100 + n);
}
int main(){
for(int i = 0; i<NTHREADS; i++)
thread_create(&threads[i], &go, i);
for(int i = 0; i<NTHREADS; i++){
exitValue = thread_join(threads[i]);
printf("Thread %d returned with %ld\n", i, exitValue);
}
printf("Main Thread Done.");
}위 코드의 실행결과를 예측해 보자.
Hello from thread 0
Hello from thread 1
Thread 0 returned 100
Hello from thread 3
Hello from thread 4
Thread 1 returned 101
Hello from thread 5
Hello from thread 2
Hello from thread 6
Hello from thread 8
Hello from thread 7
Hello from thread 9
Thread 2 returned 102
Thread 3 returned 103
Thread 4 returned 104
Thread 5 returned 105
Thread 6 returned 106
Thread 7 returned 107
Thread 8 returned 108
Thread 9 returned 109
Main Thread Done위와 같은 결과가 나온다.
- hello from thread문은 무작위로 출력된다. thread들은 동시에 실행되며 실행 순서는 scheduler가 결정하기 때문이다.
- 반면 thread returned문은 순서대로 출력된다. main()에서 thread_join을 순서대로 호출하기 때문이다.
Fork-Join Concurrency
thread의 아주 중요한 특징 중 하나. process와 유사하게 thread 또한 create()로 child를 생성하고 join()으로 child thread가 완료되길 기다린다.
이 때 thread가 공유하는 정보인 heap, data, code를 thread fork 전과 join 후에만 수정할 수 있다는 것이 바로 fork-join concurrency이다. read는 언제든 가능하다!
모든 thread가 heap, data, code를 공유하기에 어떤 thread A가 해당 영역을 수정해버린다면 A와 동시에 실행중인 다른 thread들이 영향을 받는다. 이 때 다른 thread들의 실행 시점이 A가 해당 영역을 수정하기 전후에 따라 실행 결과가 달라지기 때문에 이러한 규칙이 필요하다.
Thread Create Implementation
Pseudo Code
// func : 실행할 procedure의 pointer
// arg : 해당 procedure의 argument
void thread_create(thread_t *thread, void (*func)(int), int arg) {
// 1. TCB 할당
TCB *tcb = new TCB();
thread->tcb = tcb;
// 2. stack 할당
tcb->stack_size = INITIAL_STACK_SIZE;
tcb->stack = new Stack(INITIAL_STACK_SIZE);
// 3. stub에서 실행할 수 있게 register 값 조절
tcb->sp = tcb->stack + INITIAL_STACK_SIZE;
tcb->pc = stub;
// 4. stack frame 생성 : func, arg를 stack에 넣음
*(tcb->sp) = arg; tcb->sp--;
*(tcb->sp) = func; tcb->sp--;
// * thread_switch가 제대로 작동하기 위해 dummySwitchFrame() 호출
thread_dummySwitchFrame(tcb);
// 5. ready list에 thread push
tcb->state = #\readyThreadState#;
readyList.add(tcb);
}
// thread가 종료될 때 exit()을 무조건 호출하게 func(arg) 대신 stub()을 사용한다.
void stub(void (*func)(int), int arg) {
(*func)(arg); // func() 실행
thread_exit(0); // func()에서 exit call을 하지 않을 경우를 위해 여기서 exit call
}
// thread_create()는 stack의 top에 dummy frame을 무조건 얹어여 햔다.
// ready list에 들어간 후 처음으로 switch를 하면 popad를 하는데, 처음에는 stack에 정보가 없기 때문이다.
// 이를 대비하기 위해 stack의 제일 처음에 stub()의 주소를 넣는다.
void thread_dummySwitchFrame (TCB* tcb) {
*(tcb->sp) = stub; // stub()으로 return address 지정
tcb->sp--;
tcb->sp -= SizeOf(Popad); // popad만큼 stack 추가
}
thread create는 아래 과정을 거친다.
- TCB 할당
- stack 할당
- register 값 조절 : stub이 실행되게 한다.
- stack frame build : func, arg를 stack에 push
- dummy switch frame을 stack에 push
- ready list에 thread push
thread가 인자로 받은 func()을 바로 실행하는 것이 아니라, stub()을 호출하는 방식을 취한다. 이는 func()이 thread_exit()을 호출하는지 여부를 모르기 때문이다. func()은 일반 함수일 수도 있기 때문에 해당 함수가 thread에서 실행될 것을 안다면 exit()을 호출하겠지만, 모른다면 exit()을 호출하지 않을 것이고 그러면 thread가 계속 남아있게 된다. 이러한 상황을 막기 위해 exit()이 무조건 호출되도록 func() 대신 stub()을 사용한다.
Dummy Switch Frame
thread가 ready list에 들어간 후 처음 switch를 하면 popad를 호출해 stack에서 return address를 뽑아온다. 그러나 thread_create()로 처음 생성되어 아무것도 없는 stack에는 해당 thread로의 return address와 register 값이 들어있지 않기 때문에 처음 생성된 후 곧바로 thread_switch()가 호출되면 잘못된 주소로 return address가 지정되어 segmentation fault를 일으킬 것이다. 이를 막기 위해 dummy switch frame을 stack에 넣어두며, 꼭 필요한 과정이다!
switch는 바로 아래에서 알아볼 것이다.
Thread Context Switch
thread context는 양보를 하는지 아닌지에 따라 대분류가 나뉘고, 그 안에서도 몇 가지가 나뉜다.
- voluntary
- thread_yield()
- thread_join()
- involuntary
- interrupt
- exception
- 다른 thread의 priority가 더 높아 waiting 상태로 전환
Voluntary의 경우
다음 과정을 거쳐 thread context switch가 일어난다.
- stack에 register 값 저장
- 바꿀 thread의 stack으로 이동
- 바꿀 thread의 stack에서 저장되어 있는 register 값 복구
- return
Involuntary의 경우
다음 과정을 거쳐 thread context switch가 일어난다.
- 현재 실행중인 thread state 저장
- kernel의 interrupt나 exception handler 작동
- 다음으로 실행할 thread state 복구
이 때 interrupt handler 또는 exception handler의 마지막에 switch()를 호출하는 방식으로 구현한다.
Thread Switch Implementation
Pseudo Code
// oldThread로 진입하지만 newThread를 리턴한다.
// newThread의 register와 stack을 리턴한다.
void thread_switch (oldThreadTCB, newThreadTCB) {
// 1. old stack에 값 저장
pushad; // old stack에 register 값들을 push해 저장
oldThreadTCB->sp = %esp; // old thread의 stack pointer를 저장
// 2. new stack에서 값 빼옴
%esp = newThreadTCB->sp; // new stack으로 switch
popad; // new stack에서 register 값을을 pop해 가져옴
return;
}
thread switch는 아래 과정을 거친다.
- old thread 값 저장
- old thread의 stack에 현재 register 값들을 저장
- old thread의 stack pointer를 old TCB에 저장
- new stack으로 switch
- new stack에서 register 값들을 가져옴
Dummy Switch Frame : Re
calling convention 포스팅에서 제어권을 넘길 때 return address를 stack에 push한다고 했다.
위 pseudo code와 종합하면 switch를 한 후 popad를 해서 stack에서 register 값을 뽑아오고, 이후에 return address를 받아오는 방식이다. 그러나 앞에서 설명했듯 thread_create()로 처음 생성되어 아무것도 없는 stack에는 해당 thread로의 return address와 register 값이 들어있지 않기 때문에 처음 생성된 후 곧바로 thread_switch()가 호출되면 잘못된 주소로 return address가 지정되어 segmentation fault를 일으킬 것이다. 이를 막기 위해 dummy switch frame을 stack에 넣어둔다.
Thread Yield Implementation
Pseudo Code
void thread_yield() {
TCB *chosenTCB, *finishedTCB;
// switch 중간에 interrupt가 일어나는 것을 막기 위해 interrupt 멈춤
disableInterrupts();
// ready list에서 TCB를 꺼냄
chosenTCB = readyList.getNextThread();
if (chosenTCB == NULL) {
// ready list가 비어있다면 원래 것을 계속 돌림
} else {
// 그렇지 않다면 현재 thread를 ready list에 넣음
runningThread->state = #\readyThreadState#;
readyList.add(runningThread);
thread_switch(runningThread, chosenTCB); // Switch
runningThread->state = #\runningThreadState#;
}
// finished list의 모든 thread 삭제
while ((finishedTCB = finishedList->getNextThread()) != NULL) {
delete finishedTCB->stack;
delete finishedTCB;
}
enableInterrupts();
}
thread yield는 아래 과정을 거친다.
- interrupt 멈춤
- ready list가 비어있다면 원래 것을 계속 돌린다.
- 그렇지 않다면, yield()를 호출한 thread를 ready list에 넣고, 다음으로 실행할 thread와 switch한다.
Thread in User Process
위에서 살펴본 방식은 모두 kernel에서 수행되는 multi thread 방식이었다. 그러나 user process도 multi thread를 사용하면 더 좋은 성능을 낼 수 있을 것이다.
User Process Multi Thread 구현 - 1. System Call 사용
system call을 사용해 kernel thread처럼 user thread를 만드는 방법이다. thread fork, join, exit, 등등의 thread 관련 operation을 user process에서 실행하면 kernel이 해당 system call을 받아 thread를 생성한다.
그러나 이 방법은 모든 thread operation이 system call이기 때문에 user mode와 kernel mode의 전환이 많이 일어나 성능이 나쁘다는 단점이 있다.
User Process Multi Thread 구현 - 2. Kernel 없이 User Library 사용
kernel 없이 user library가 thread를 만들고 context switch를 하는 방식이다.
그러나 이 방법은 OS가 user thread를 관리하지 않기 때문에 system call 등의 interrupt가 발생했을 때 thread 간의 transition이 일어나지 않는다.
User Process Multi Thread 구현 - 3. Kernel의 도움 thread 구현
kernel과 user library가 같이 thread를 만드는 방법이다. 바로 앞의 방식 user library가 모든 thread operation을 관리했지만 이 방식은 context switch와 scheduler만 구현하는 방식이다.
kernel이 thread_create() 등의 operation을 관리하기에 OS가 multi thread임을 알고 있다. 따라서 system call 등의 kernel event가 발생했을 때 kernel이 해당 scheduler에게 event를 전달해 준다.
Thread Implement Issues
multi thread는 동시에 실행되기 떄문에 몇 가지를 신경써서 봐야 한다.
- fork()와 exec() : fork()나 exec()가 호출되었을 때 processor의 관점으로 모든 thread를 복사할지, 하니면 호출한 thread만 복사할지 고민해봐야 한다. 여기서는 fork() 후 바로 exec()를 호출하면 호출한 thread에 대해서만 적용하고, 그렇지 않다면 모든 thread에 대해 적용하는 것이 일반적이다.
- signal handling : handling을 synchronous하게 구현해야 할지, asynchronous하게 구현해야 할지 고민해봐야 한다.
- thread cancellation : thread가 동작을 완료하기 전 중지시킬 때 asynchronous하게 바로 중지시켜야 할까? 아니면 해당 thread에게 중지시켜도 되는지 물어보고 중지시켜야 할까? 전자의 경우 data consistency 측면에서 문제가 생길 수 있고, 후자의 경우에는 구현 내용이 많아진다.
잘못된 내용이나 지적, 오탈자 등은 언제나 환영합니다.
'CS > OS' 카테고리의 다른 글
| [OS] Implementing Synchronization (0) | 2023.07.01 |
|---|---|
| [OS] Synchronization - Lock, Condition Variable, Semaphore (0) | 2023.07.01 |
| [OS] Process (0) | 2023.06.26 |
| [OS] Operating System Overview (0) | 2023.06.25 |
| [컴퓨터 SW] Dynamic Memory Allocation (0) | 2023.06.24 |