![[OS] Storage Device](https://img1.daumcdn.net/thumb/R750x0/?scode=mtistory2&fname=https%3A%2F%2Fblog.kakaocdn.net%2Fdn%2FVK7XX%2FbtsnK8I42CP%2FvsKgN77dFR0nmT8aC5Akh0%2Fimg.png)
이 글은 포스텍 박찬익 교수님의 운영체제(CSED312) 강의를 기반으로 재구성한 것입니다.
이 글에서는 storage device에 대해 다룬다. Storage - RAM & Disk 포스팅에서와 유사한 부분이 많기에 비슷한 부분은 생략하거나 간단하게 적을 것이다.
요새 사용하는 storage는 크게 아래 2가지로 나뉜다.
- Hard Disk Drive (magnetic disk)
- reliable하다.
- 가격이 싸다.
- block level random access이다.
- sequential access의 성능이 좋다.
- Flash Memory (SSD)
- reliable하다.
- 가격이 비싸다.
- block level random access이다.
- read의 성능은 좋지만 random write의 성능이 나쁘다.
Disk Drive
Disk Controller Caching

disk와 connection의 사이는 위와 같이 controller가 붙어 있다. 이 때 외부 connection은 데이터가 DRAM cache에 있는지, disk에 있는지 모른다.
Disk의 구조

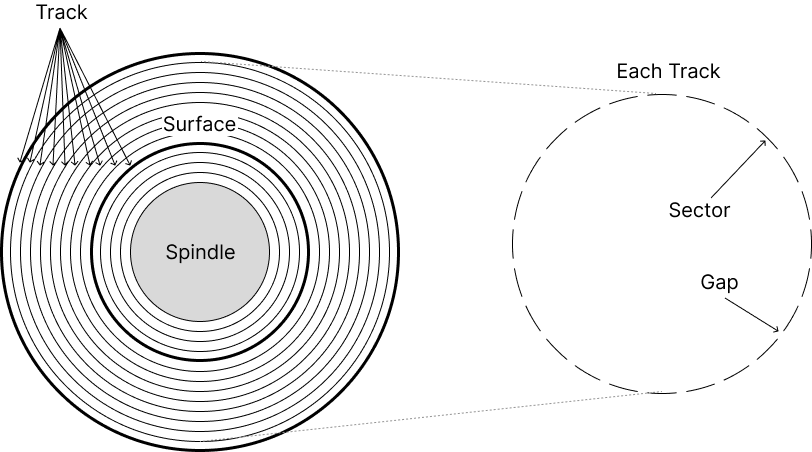
Storage - RAM & Disk 포스팅에서 surface, track, sector의 구조 그림을 그려 놨다.
추가적으로 알면 좋은 점은, track은 원이기 때문에 바깥에 더 많은 sector가 올라간다. 따라서 빈번하게 사용되는 정보를 바깥쪽에 두면 좋다.
Sector
sector에 문제가 생겨 해당 sector에 값을 읽고 쓸 수 없는 경우가 있다. 이 경우 다음과 같은 방법을 사용한다.
- sector sparing : 같은 surface에 있는 여분의 sector를 사용해 remapping한다.
- slip sparing : 모든 sector를 한 칸 당겨 mapping한다.
- 3번이 오류 난 경우, 4번을 3번으로, 5번을 4번으로, .. 한 칸씩 모두 당긴다.
이외에도 track의 sector를 같은 선상에 놓지 않고 offset을 조금 두어 sequential하게 읽힐 수 있게 만드는 track skewing이라는 기법이 있다.
Disk Performance
마찬가지로 Storage - RAM & Disk 포스팅에서 똑같은 내용을 작성했다.
- T$_{access}$ : 어떠한 sector를 읽는데 걸리는 시간 = T$_{avg seek}$ + T$_{avg rotation}$ + T$_{avg transfer}$
- T$_{avg seek}$ : 원하는 정보가 어떤 sector에 위치해 있는지 찾고 arm을 옮기는 데 걸리는 시간, 평균 3-9ms.
- T$_{avg rotation}$ : 현재 위치부터 해당 sector까지 disk가 회전할 때 걸리는 시간 = $\frac{1}{2} \times \frac{1}{RPM} \times \frac{60s}{1min}$
- T$_{avg transfer}$ : 해당 sector를 읽는 시간 = $\frac{1}{RPM} \times \frac{1}{\text{average number of sectors per track}} \times \frac{60s }{1min}$
- 여기서 RPM은 분당 회전수이다.
예제 1. random access
500 random disk read를 한다고 하자. 이 때 seek time은 10.5ms, rotation은 4.15ms, transfer는 5-10us가 걸린다고 하자. 총 얼마의 시간이 필요할까?
하나의 탐색에 걸리는 시간이 10.5 + 4.15 + 0.01이고, 총 500번의 access를 하므로 500 * (10.5 + 4.15 + 0.01)/1000 = 7.3s가 걸린다.
예제 2. sequential read
500 sequential disk read를 한다고 하자. 이 때 seek time은 10.5ms, rotation time은 4.15ms, transfer time은 500 sector * 512 byte / 128MB/s = 2ms라고 하자.
sequential이므로 첫 위치를 찾는 데 10.5 + 4.15ms가 걸리고, 거기서부터 2ms의 시간만에 500개의 sector를 읽을 수 있으므로 10.5 + 4.15 + 2 = 16.7ms가 걸린다.
Disk Scheduling
disk I/O가 많으면 요청이 쌓기게 되고, OS는 disk별로 request queue를 유지한다. 그러면 어떤 순서로 요청을 처리해야 할까?
FIFO
들어온 순서대로 처리하는 방식이다.
장단점
- fair하고 simple하다.
- disk의 여러 곳을 왔다갔다 할 수 있기 때문에 느리다. (wild swing)
SSTF : Shortest Seek Time First
쌓인 요청 중 제일 짧은 거리에 있는 것을 선택하는 방법이다.
장단점
- seek time이 최소이다.
- starvation이 일어날 수 있다.
- 처음 위치가 0인데, disk의 위치가 1, 2, 1, 2, 1, 2, 1, 10, 1, 2, 1, 2, 1, 2인 요청이 들어왔다고 생각해보자.
SCAN : Elevator Algorithm
양 끝점을 왔다갔다하면서 읽는 방식이다. (실제 구현은 끝점까지 가지는 않고, 제일 끝에 있는 request까지만 간다. 이를 LOOK이라고 불린다.) elevator와 유사해서 elevator algorithm이라고도 한다.
장단점
- 각 요청이 기다리는 시간이 한정되어 있다.
- 시작 위치의 반대편 끝에 있는 요청이 조금 오래 기다린다.
CSCAN : Circular Scan
SCAN을 조금 바꾼 방식으로, 한쪽 끝점을 찍으면 반대쪽 끝점으로 가서 읽는 방식이다. (마찬가지로 끝점으로 가는 게 아니라, 제일 끝에 있는 request로 간다.)
장단점
- 기다리는 시간이 일정하다.
- starvation이 일어나지 않는다.
- 끝점에서 다른 끝점으로 갈 때 아무것도 하지 않는다.
R-CSCAN
CSCAN이지만 물리적 거리가 가까운 것부터 처리하는 방식이다. 정의로는 track switch time < rotation time일 때 그것부터 탐색하는 방법이다. 아래 그림을 보자.
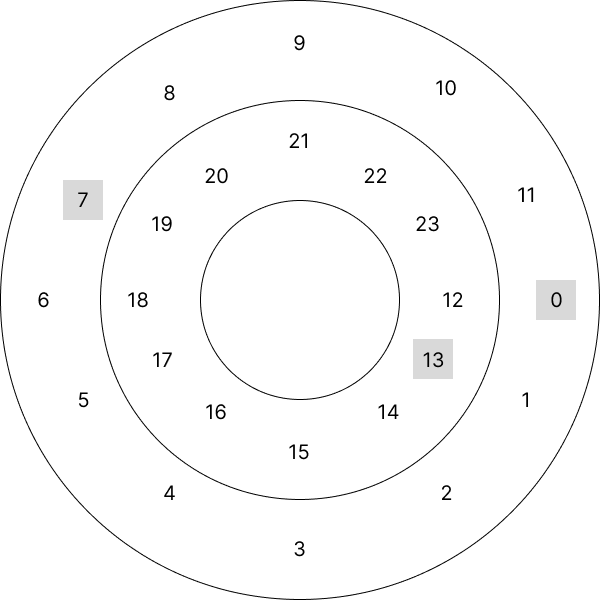
위와 같이 생긴 platter에서 0, 7, 13에 있는 sector를 읽는다고 하자. CSCAN은 같은 track에 있는 것을 우선적으로 읽기 때문에 0, 7, 13의 순서로 읽는다.
그러나 R-CSCAN은 track switch time과 rotation time을 비교한다. 위 예시에서 0-13으로 track을 바꾸는 시간이 rotation time보다 짧다면 0-13-7의 순서로 탐색하며, CSCAN보다 조금 더 더 빠르다.
기타
이외에도 linux에서는 anticipatory scheduling, completly fair queuing(CFQ) 등을 사용한다.
- anticipatory scheduling : 더 가까운 I/O가 올 때까지 기다리는 방식.
- Completly Fair Queuing, CFA : 실제 수행 시간을 바탕으로 fair하게 scheduling하는 방법. priority를 따르고 fair하며, starvation이 없다.
SSD
원판에 자기 정보를 저장하는 HDD 대신 반도체에 직접 정보를 저장하는 flash memory 기술이다.
read는 약 20us, write는 약 200us, erase는 2ms가 걸린다.
write할 때는 원래 있던 값을 삭제 후에 다시 써야 하며(따라서 시간이 2배 이상 걸린다.), 소재의 한계로 인해 write하는 회수가 정해져 있다.
장단점
- 이동하지 않기 때문에 seek time이나 rotation time이 없으며, 조용하다.
- latency가 빠르다.
- 삭제할 수 있는 회수가 정해져 있다.
- HDD보다 훨씬 비싸다.
Flash Translation Layer
외부의 입력을 SSD 내부에서 어떤 처리를 해야 하는지 번역해주는 layer가 필요하며, 이를 flash translation layer라 한다. flash translation layer는 logical page를 physical location으로 바꾸어 준다. 하는 일들은 다음과 같으며, 모두 abstraction되어 있다.
SSD의 경우 erase가 느리기 때문에 무언가를 쓸 때 미리 빈 page를 확보해 두고, 거기에 값을 쓴다. 원래 있던 page들은 나주에 따로 처리한다. 또한 삭제 회수가 정해져 있기 때문에 최대한 erase cycle이 동일하게 배분한다. 만약 page가 고장나거나 삭제 회수 초과 등으로 작동하지 않으면 해당 page를 작동하지 않게 한다. (위에서 살핀 sector sparing 등을 사용)
잘못된 내용이나 오탈자에 대한 지적, 질문 등은 언제나 환영합니다.
'CS > OS' 카테고리의 다른 글
| [OS] File System 구현 (0) | 2023.07.17 |
|---|---|
| [OS] File System & Directory (0) | 2023.07.16 |
| [OS] Demand Paging & Thrashing (0) | 2023.07.15 |
| [OS] Address Translation (0) | 2023.07.15 |
| [OS] Process Scheduling (0) | 2023.07.06 |