![[OS] File System & Directory](https://img1.daumcdn.net/thumb/R750x0/?scode=mtistory2&fname=https%3A%2F%2Fblog.kakaocdn.net%2Fdn%2FCijzU%2FbtsnGOQfTTk%2FMzxGnhg2aF0EOICFzJtUXk%2Fimg.png)
이 글은 포스텍 박찬익 교수님의 운영체제(CSED312) 강의를 기반으로 재구성한 것입니다.
이 글에서는 file, file system, directory에 대해 살펴본다. 이전에 작성한 System Level I/O 포스팅에서도 비슷한 내용을 다루었으니 필요 시 참고하면 될 것 같다.
File
file은 nonvolatile storage device에 저장된 data의 집합이다. OS는 이 정보를 더 쉽게 다루기 위해 file을 연속된 byte의 나열로 보기도 한다.
file의 정보는 크게 metadata와 file data 2가지로 나뉜다.
- metadata : data에 대한 data. 정보의 요약본.
- 이름, 식별자, type, location, size, protection, time, date, user identification 등
- file data : file의 정보.
File System
file system은 file에 관련된 작업을 수행하고 자원을 관리하는 software이며 아래 기능들을 담당한다.
- file의 생성/삭제/읽기/쓰기/수정/이동
- file의 접근 권한을 관리
- file이 사용하는 resource를 관리
대부분의 file은 모두 작다. 그러나 몇몇 큰 file은 nonvoltile storage에 저장되어 있기에 가져오기 위해 I/O time이 필요하다.
File System Abstraction
file system은 다음과 같은 abstraction을 사용자에게 제공한다.
- byte oriented : 실제로 file은 nonvolatile storage에 저장되기에 block 단위로 저장된다. 그러나 file system은 이를 byte 단위로 바꾸어 사용자에게 제공한다.
- symbolic name : 실제로 file은 sector에 저장되지만 file system은 사용자가 접근하기 위해 symbolic name으로 제공한다.
- protected : 실제로는 nonvolatile storage의 해당 위치를 보면 누구나 알 수 있지만 file system은 권한 있는 사용자만 해당 파일에 접근할 수 있게 한다.
- directory : file system에서 index는 directory로 주어진다. directory와 file name을 조합해 indexing을 할 수 있다.
- path : file이나 directory를 uniquely identify하는 문자열이다.
- link
- hard link : filename에서 metadata location으로의 연결.
- symbolic(soft) link : filename에서 alternate name으로의 연결.
- mount : 하나의 file system과 다른 file system을 이어주는 매핑.
indexing이란 symbolic name으로 physical location을 찾는 과정을 말한다.
Logical View

사용자가 file에 접근할 때 위와 같은 과정을 거친다. 실제로 file은 physical block의 연속이지만 file system은 byte sequence로 사용자에게 abstraction해 준다.
- directory와 filename으로 metadata를 찾는다. 사용자는 단 하나의 file로 본다.
- file system에서 file은 byte sequence이다.
- file metadata가 어떤 file data에 접근하는지 보고, physical block을 찾는다. 이 때 block은 memory에 올라와 있으므로 없으면 disk에서 정보를 가져온다.
- 실제 file의 위치를 찾는다.
요약
요약하면, 각각의 layer에서 file은 다음과 같다.
- User View : persistent data structure
- Application View : sequence of byte
- System View : seqence of physical block
File System 구성
disk는 하나 이상의 partition으로 나뉜다. 이 partition은 file system, swap file, raw 등 여러 가지 상태로 사용할 수 있다. 이 때 file system으로 사용하는 partition을 volume이라 한다. 각 volume은 file에 대한 정보를 포함하고 있다.

위 예시에서 왼쪽 그림은 disk 1개, partition 2개인 상태를 보여준다. 오른쪽 그림은 disk 2개가 partition 1개로 합쳐진 것을 보여준다.
File System Mounting
바로 위에서 disk에 file system이 있다는 것을 봤다. disk에 file system이 있다고 바로 적용되는 것이 아니라 mounting을 통해 OS와 연결해야 한다. 새로 사용하고 싶은 file system을 OS의 특정 directory인 mount point에 연결해야 그때부터 그 file system을 사용할 수 있다.
In-Memory File Data Structure
System Level I/O 포스팅을 참고하자. 같은 내용이 있다.

file system의 속도 향상을 위해 file descriptor(file metadata)를 memory에 올린다. 이 때 process는 metadata를 바로 쓰는 것이 아니라 open file table을 거쳐 사용한다.
- process-wide open file table : process마다 하나씩 존재한다. 현재 process가 어떤 file을 열고 있는지 가리킨다. 각각의 file에 file descriptor number를 부여한다.
- system-wide open file table : 모든 process가 공유하는 table이다. file position, reference count 등의 정보를 가지고 있다.
- file descriptor : file metadata이다.
file position이 file descriptor에 있지 않은 이유는 여러 process가 하나의 file에 접근할 수도 있기 때문이다. 만약 2개의 process가 하나의 file에 접근하면 system-wide open file table에 같은 metadata를 가리키는 element가 생긴다.
process가 같은 file을 2번 open했을 때, 각각의 file을 독립적으로 사용하기 위해 system-wide open file table이 필요하다.
File System API : UNIX
unix의 경우 다음과 같은 file system API를 제공한다.
- create, link, unlink, mkdir, rmdir, rename
- link : file에 대한 pathname을 새로 만든다.
- unlink : link를 삭제한다.
- mkdir : directory를 새로 만든다.
- rmdir : directory를 삭제한다.
- rename : 이름을 바꾼다.
- open, close, write, seek
- fsync : file의 수정 내용을 volatile memory에 buffer로 cache해 memory barrier처럼 변경 파일이 disk에 저장되도록 강제한다.
- stat : file metadata를 보여준다.
open()
- file을 찾는다.
- in-memory file data structure에 해당 file이 없다면 file descriptor를 올린다.
- system-wide open file table에 해당 file이 없다면 새 entry를 만들어 넣는다.
- PCB에 새 entry를 만들어 올린다.
- metadata에 link한다.
open()은 file descriptor number값인 fd를 리턴한다. 이를 사용해 나머지 모든 작업을 수행한다.
read()
- process-wide open file table에 fd에 해당하는 system-wide open file table element를 알아낸다.
- system-wide open file table element가 가리키는 file descriptor element(metadata)를 알아낸다.
- metadata 내에 physical location이 있기 때문에 이를 참고해 file block의 값을 읽는다.
- disk의 physical block을 buffer로 가져온다.
buffer는 disk와 memory 사이에 이동하는 data가 caching되는 공간이라 생각하면 된다.
write()
- process-wide open file table에 fd에 해당하는 system-wide open file table element를 알아낸다.
- system-wide open file table element가 가리키는 file descriptor element(metadata)를 알아낸다.
- metadata 내에 physical location이 있기 때문에 이를 참고해 file block의 값을 읽는다.
- buffer에 있는 값을 physical block에 덮어쓴다.
write의 경우 read()와 별 차이가 없다. 단, fsync()가 필요하다.
link()
old file과 new file을 link한다.
Directory & Link
directory는 모든 file에 대한 정보를 포함하는 node의 집합이다.
효율적인 directory 구조를 위해서는 다음과 같은 목표를 달성해야 한다.
- efficiency : 파일을 빨리 찾을 수 있어야 한다.
- naming : 사용자가 읽기 쉬워야 한다.
- grouping : 비슷한 file을 그룹으로 묶을 수 있어야 한다.
single level, two level, tree structure, acyclic graph, general graph 등 여러 구조가 있다. 그렇지만 여기서는 tree structure, acyclic graph만 살펴본다.
Tree Structred Directory
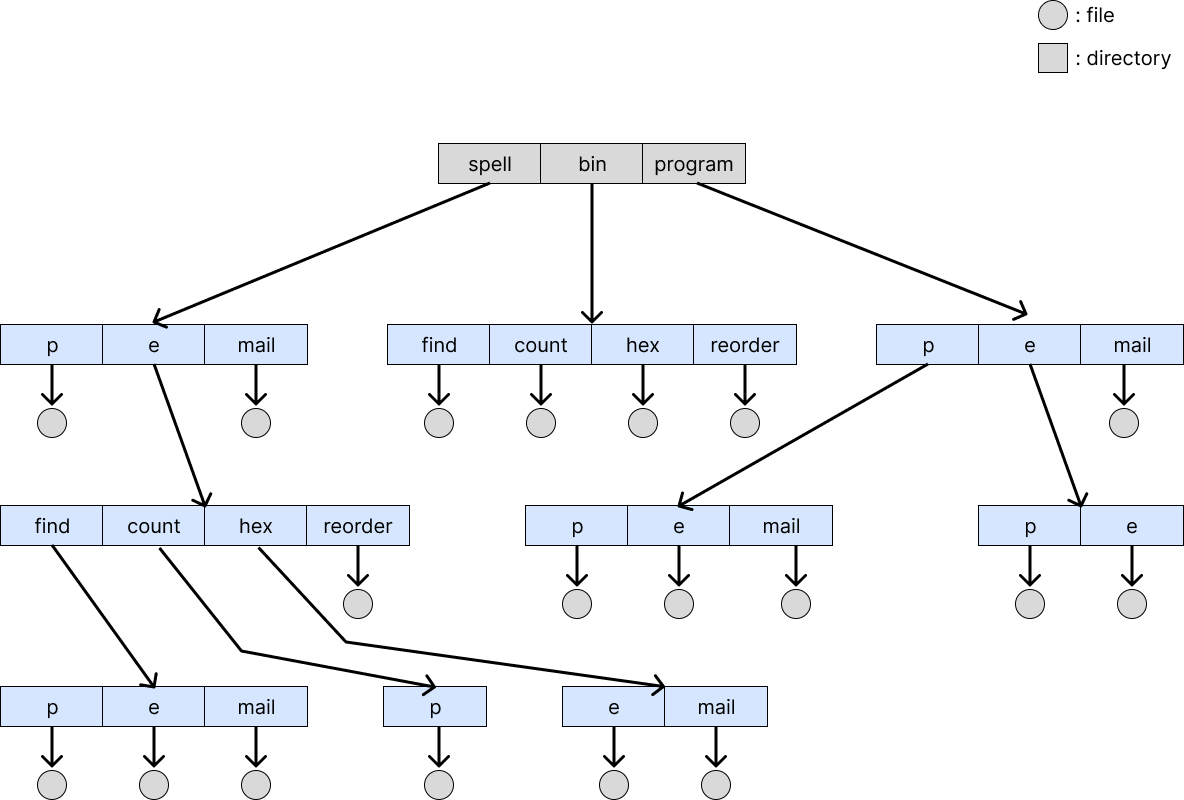
tree처럼 directory를 만드는 방법이다.
- absolute path : root부터 시작하는 path
- relative path : 현재 경로부터 시작하는 path
장단점
- 탐색이 빠르다.
- grouping을 할 수 있다.
- co-pointing 불가 : 하나의 file을 여러 개가 동시에 접근할 수 없다.
Acyclic Graph Directory
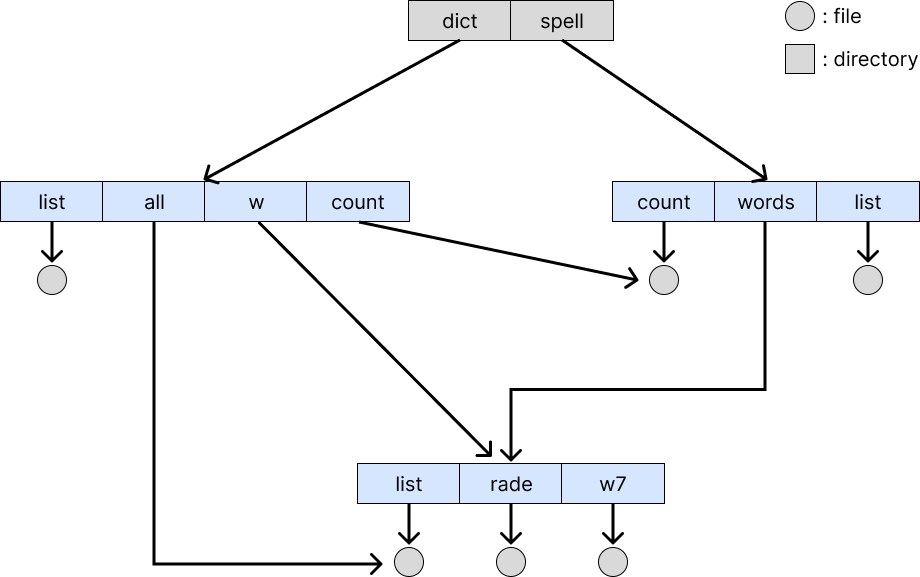
acyclic graph로 directory를 만드는 방법이다. (root부터 file까지 내려가는 형태.)
단, dangling pointer 문제가 생길 수 있다. 이를 해결하기 위해 reference count를 사용해 count가 0일 때만 삭제할 수 있도록 해야 한다.
dangling pointer란 유효하지 않은 파일을 가리키는 현상이다.
위 그림에서 예를 들어 /dict/count가 가리키는 파일을 삭제하면 /spell/count는 없는 파일을 가리킨다.
- link : 존재하는 file에 새로운 이름을 부여하는 것이다.
- resolve : link를 따라가서 file을 찾는 과정을 말한다.
장단점
- co-pointing 가능 : 서로 다른 이름이 같은 file을 가리킬 수 있다.
- 위그림에서 예를 들어 /dict/count와 /spell/count가 같은 file을 가리킨다.
- file system을 탐색할 때 같은 file을 2번 탐색할 수 있기 때문에 overhead가 발생한다.
Hard Link
hard link란 filename로 직접적으로 연결되는 directory mapping을 말한다.
hard link를 사용한다는 것은 해당 file에 2개의 이름을 주는 것과 같다. 예를 들어 /a/b라는 file에 link를 사용해 /c/d라는 이름을 줬다고 가정하자. /a/b로 접근해 수정한 내용은 /c/d로 접근했을 때도 반영되어 있다.
같은 physical block에 접근하는 다른 이름을 만든다고 생각하면 된다.
Symbolic Link (Soft Link)
symbolic link는 다른 filename에 대한 directory mapping이다.
hard link는 partition이 같아야 하고, directory로의 link를 만들지 못한다. 이를 해결하기 위해 symbolic link를 사용한다. symbolic link는 file이 아니라 file 이름을 가리키는 link이며, 다음과 같은 과정으로 원래 file을 얻어낸다.
- symbolic link로 file을 연다.
- file로부터 target name을 얻는다.
- target name을 통해 target file을 연다.
symbolic link는 file을 가리키는 link이므로 hard link가 모두 삭제되면 원래 파일이 삭제된 것처럼 symbolic link는 유효하지 않은 link가 된다. file에 접근하는 다른 이름을 만든다고 생각하면 된다.
symbolic link를 window로 치면 바로가기와 같은 기능이다. window에서 파일 A와 A에 대한 바로가기를 만들고, 파일 A를 삭제한 후 바로가기를 열면 작동하지 않는 것을 생각하면 된다.
Hard Link vs Symbolic Link
- symbolic link와 원본 file은 type이 다르다. hard link는 type이 사본이기 때문에 type이 같다.
- symbolic link는 pointer이기 때문에 4byte이다.
- 원본 파일이 삭제된 경우 symbolic link는 동작하지 않지만 hard link는 동작한다.
잘못된 내용이나 오탈자에 대한 지적, 질문 등은 언제나 환영합니다.
'CS > OS' 카테고리의 다른 글
| [OS] Storage Device (0) | 2023.07.17 |
|---|---|
| [OS] File System 구현 (0) | 2023.07.17 |
| [OS] Demand Paging & Thrashing (0) | 2023.07.15 |
| [OS] Address Translation (0) | 2023.07.15 |
| [OS] Process Scheduling (0) | 2023.07.06 |