![[컴퓨터 SW] Dynamic Memory Allocation](https://img1.daumcdn.net/thumb/R750x0/?scode=mtistory2&fname=https%3A%2F%2Fblog.kakaocdn.net%2Fdn%2FzGuF2%2FbtslbxXhIHw%2FL04zCVKw6tT3cmcVIfK5b1%2Fimg.png)
이 글은 포스텍 김종 교수님의 컴퓨터SW시스템개론(CSED211) 강의를 기반으로 재구성한 것입니다.
이 글에서는 dynamic memory allocation에 대해 알아본다. (java의 object나 C의 malloc, C++의 new 등 heap에 data 할당하는 것들)
Dynamic Memory Allocation
C의 mmap과 같이 직접 메모리를 할당할 수 있지만 이 경우 메모리의 할당 주소를 직접 지정해 주고 잊지않고 할당한 메모리를 해제하는 등의 작업이 필요하다. 이를 해결한 것이 dynamic memory allocation이다. dynamic memory allocatior는 heap에 필요한 만큼 메모리를 자동으로 할당해 준다. 또한 모든 프로그램의 data structure는 runtime마다 달라지고 실행시키기 전에는 해당 data structure의 크기를 정확하게 알 수 없기 때문에 dynamic하게 크기가 바뀔 수 있어야 한다는 필요성도 있다.
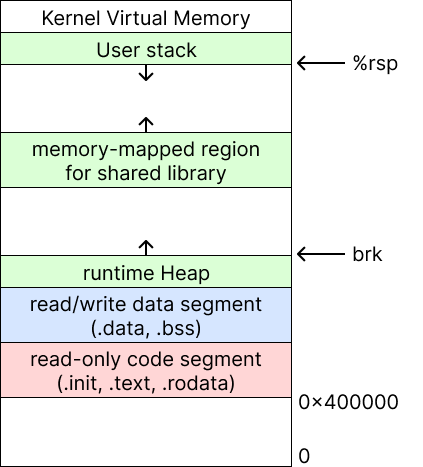
실제 프로그램이 구동되면서 생기는 memory의 구조는 위 그림과 같다. 이 때 dynamic memory들은 모두 heap에 할당되며 dynamic memory allocator는 heap memory를 관리한다. 이 때 heap이 끝나는 주소를 brk라고 한다.
allocator들은 block 단위의 메모리를 할당하거나 해제하는 역할을 한다. allocator는 크게 2종류가 있다.
- explicit allocator : C의 malloc같이 할당받은 메모리를 explicit하게 free해야 한다.
- implicit allocator : Java의 garbage collection같이 할당받은 메모리를 explicit하게 free하지 않아도 된다.
C의 malloc과 free
void *malloc(size_t size);
void *sbrk(intprt_t incr);
void free(void *ptr);C에서 사용하는 메모리 할당/해제 함수는 위와 같다.
- malloc() : size만큼의 block을 heap에 할당하고, 해당 block의 시작 address를 리턴한다.
- sbrk() : kernel의 brk pointer에 incr만큼을 더해 heap을 늘인다. 성공하면 이전 brk의 값을, 실패하면 -1을 리턴한다.
- free() : ptr부터 시작하는, 할당받은 block을 해제한다.
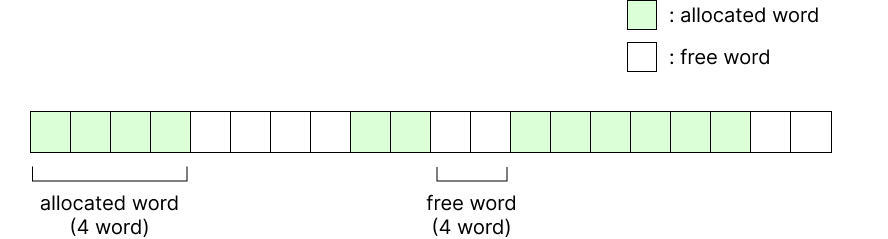
8byte word를 한 block으로 표현했을 때 메모리가 할당되는 모습을 그림으로 나타내 보면 위와 같다.
Memory Alignment

dynamic memory allocation 시 memory는 align을 한다. 일반적으로 double-word align을 하기에 위 그림과 같다. p2와 p3의 경우 하나의 word가 비지만 align때문에 비워둔 것을 볼 수 있다.
Dynamic Memory Allocation Object
크게 2가지의 목표가 있다.
- throughput maximize : 할당과 해제 작업을 빠르게 하면 할수록 좋다.
- memory utilization : 메모리 크기는 한정되어 있기 때문에 최대한 적은 메모리로 할당 작업을 처리할수록 좋다.
Fragmentation
fragmentation, 파편화. memory utilization을 최적화하기 위해 조심해야 하는 현상이며, 아래 2가지 종류가 있다.
- internal fragmentation : 할당된 block이 data보다 클 때를 의미한다. 보통 자주 발생하며, alignment로 인한 padding 등 다양한 원인으로 인해 발생하며 측정하기 쉽다.
- external fragmentation : heap memory에는 충분한 공간이 있지만 큰 하나의 free block이 없어 메모리를 할당할 수 없는 상황을 의미한다.
예시

internal fragmentation은 위에서 언급된 것처럼 [실제 메모리가 할당된 부분, payload]보다 할당받은 block이 많을 때를 의미한다.

위 그림을 보자. p4를 alloc할 때 분명 남는 word는 8개이지만 size 7짜리 연속된 공간이 없어 p4를 할당하지 못한다. 이처럼 external fragmentation은 전체로 봤을 땐 충분한 공간이 있지만 하나의 연속된 free space가 없어 메모리를 할당하지 못하는 상황을 의미한다.
Memory Allocation 구현
구현 시 신경써야 할 점들은 다음과 같다.
- 어떤 pointer가 주어졌을 때, 해당 pointer부터 얼마만큼의 block을 free해야 하는지 어떻게 알까?
- free block들을 어떻게 알고 있을까?
- 많은 free block 중 어디에 할당해야 할까?
이를 해결하기 위해 일반적으로 allocation block 바로 앞에 header를 붙인다. header는 word size이며 해당 block의 크기가 얼마난지를 가지고 있다. 이를 통해 해당 pointer부터 얼만큼의 block을 free해야하는지 알 수 있다.
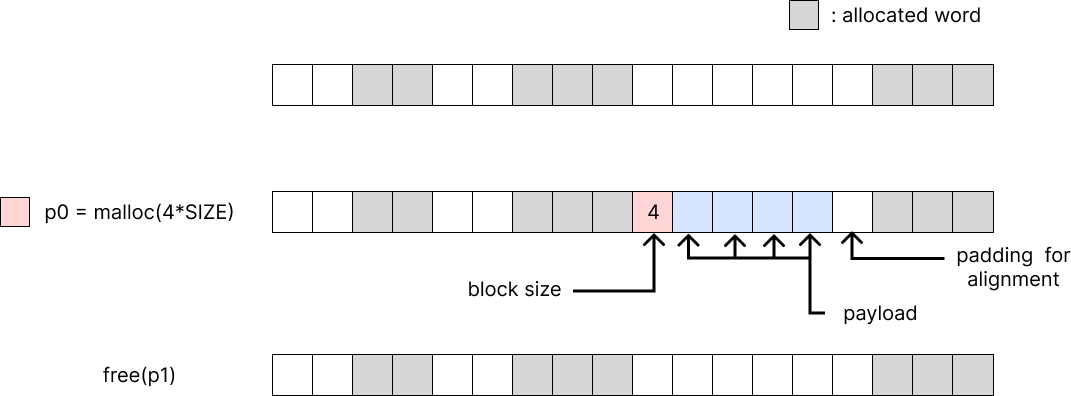
위 예시를 보자. p0를 할당했다. p0는 총 4개의 word를 사용한다는 것을 의미하기 위해 header에 4라는 값을 넣었고, payload 이후에는 alignment를 위한 padding이 하나 들어갔다. 이런식으로 header를 사용한다.
free block 관리
크게 4가지 방법이 있다.
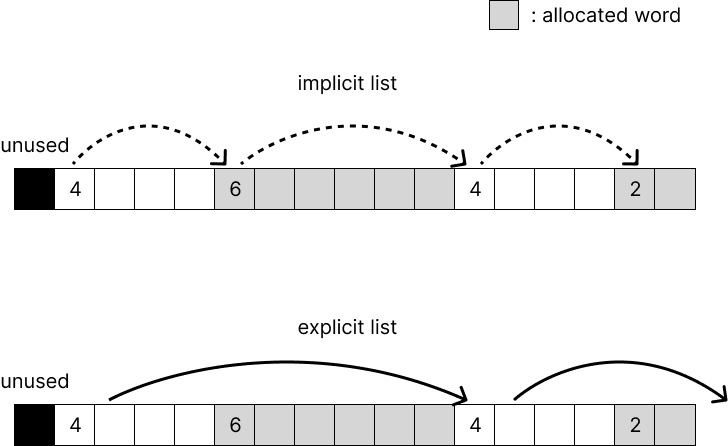
- implicit list : 모든 block을 연결하는 방법
- explicit list : free block만 연결하는 방법
- segregated free list : 크기가 다른 free block list들별로 묶는 방법
- blocks sorted by size : free block들끼리 length를 key로 가지는 balanced tree를 사용하는 방법
Implicit Free List

모든 allocated block과 free block을 위와 같이 나타낸다. header에는 size가 있고 추가로 bit 하나로 allocated인지 free인지 표기한다. payload에는 할당한 크기가 들어가고, padding은 필요 시 추가한다. 이 header와 함께라면 implicit free list를 구현할 수 있다.

위 예시를 보자. 제일 왼쪽부터 16/0은 총 size가 16byte(2 words, 2칸)이고 a=0이므로 free block, 32/1은 총 size가 32byte(4 words, 4칸)이고 a=1이므로 allocated block, ... 를 의미한다.
일반적으로 적용하는 double word alignment를 적용하면 block 크기는 항상 8이 된다. 따라서 size의 하위 3비트는 항상 0이다. 그래서 header & 0x1을 하면 allocated인지 여부를 알 수 있다. size를 가져올 때는 header & ~0x7을 하면 된다.
이렇게 모든 block의 size를 알기 있기 때문에 앞에서부터 block header를 만나면 다음 block으로 주소값을 움직여 모든 block을 순회할 수 있다.
적당한 free block 찾고 할당하기
allocator는 찾은 free block list에서 적당한 block을 선정해야 한다. 이 때 어떻게 '적당한' block을 선정하는가? 아래 3가지 알고리즘이 있다.
- first fit
- free block list를 처음부터 검색해서 할당할 block size보다 크기가 큰 첫 번째 free block에 할당한다.
- 시간복잡도는 모든 block의 개수에 linear이다.
- 보통 memory의 마지막에 큰 free block이 남겨지고, 앞부분에는 작은 free block이 남겨진다. 바로 위의 특성과 합해져 큰 free block을 찾는 경우 시간이 오래 걸린다.
- next fit
- first fit과 유사하지만 free block list를 처음부터 찾는 대신 이전에 검색이 종료된 지점부터 검색을 시작한다.
- first fit보다 빠르고 앞 부분의 external fragmentation이 많이 일어난 경우 더 빨라진다. 그렇지만 memory utilization은 최악이다.
- best fit
- 모든 free block을 검사해 할당할 block size보다 크기가 큰 block 중 제일 작은 free block에 할당한다.
- memory utilization이 제일 높지만 모든 heap을 검사해야 하기 때문에 시간은 제일 오래 걸린다.
Free Block Split
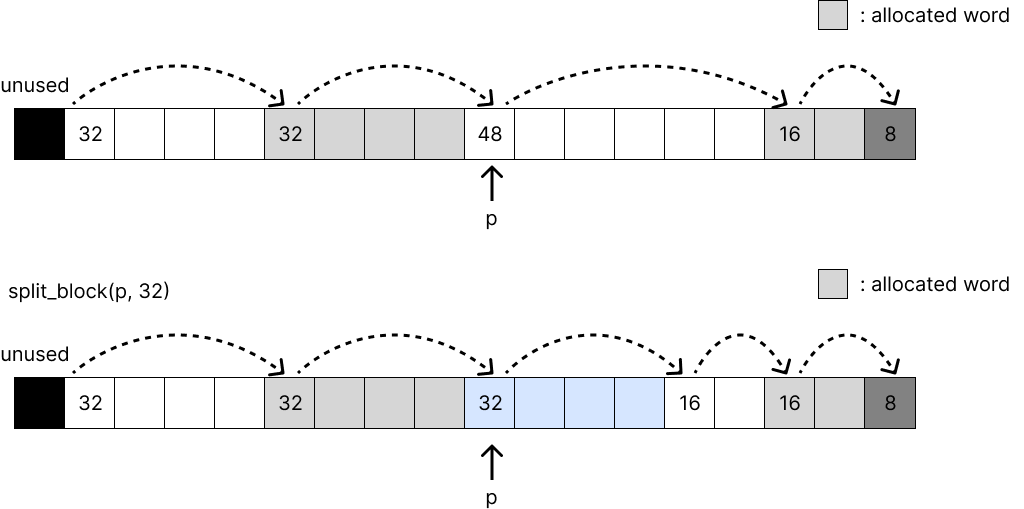
위 알고리즘으로 적당한 free block을 찾았을 때 만약 free block size가 할당할 block size보다 크다면 free block을 2개로 나눈다. 위 그림에서 32byte만큼의 block을 할당하는데 p 위치에 있는 48byte짜리 free block에 할당하는 경우, 48byte를 32byte와 16byte로 나누고 32byte에 할당한다.
할당 해제하기
Free Block Coalesce
위 예시처럼 48byte짜리 free block을 32byte와 16byte로 쪼갰다고 하자. 이 상황에서 free(p)를 하면 32byte의 free block과 16byte의 free block이 연속하게 된다. 이처럼 free block이 연속된 경우에는 큰 block을 할당할 수 없기 때문에 합친다.
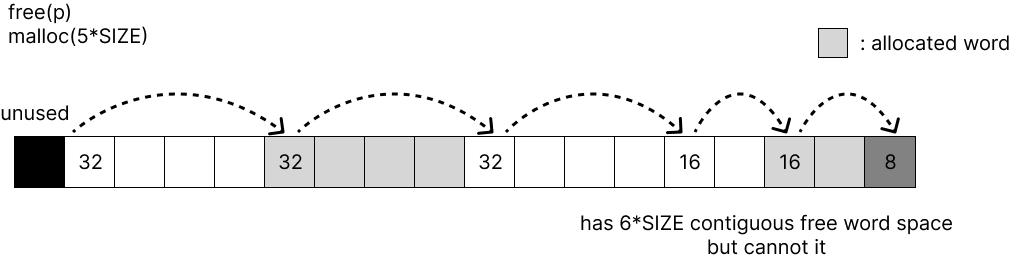
coalescing을 하는 타이밍에 따라 2가지 경우로 나뉜다.
- immediate coalescing : free가 불러지면 바로 coalescing.
- defered coalescing : coalescing이 필요할 때까지 대기했다가 필요하면 coalescing.
Boundary Tag
어떻게 합쳐야 할까? free block이 생긴 경우 그 전후에 있는 block을 살펴보면 된다. 그러나 지금까지 구현은 [자기 뒤에 있는 block]만 알 수 있다. 이런 상황을 해결하기 위해 allocated block 앞에 붙이는 header처럼 꼬리에 footer도 붙인다.
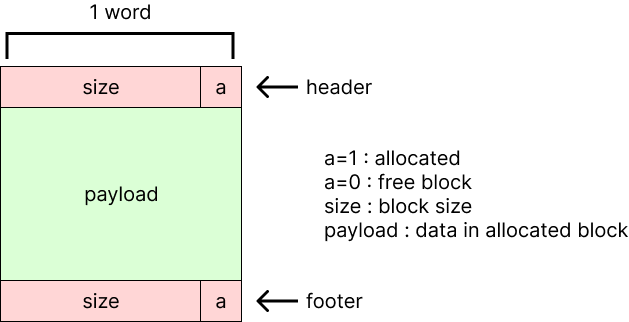
형식은 header와 동일하며 이를 boundary tag라고 한다. boundary tag로 인해 원래는 자기 뒤에 있는 block만 알 수 있었는데, 이제는 자기 앞의 block도 알 수 있다!
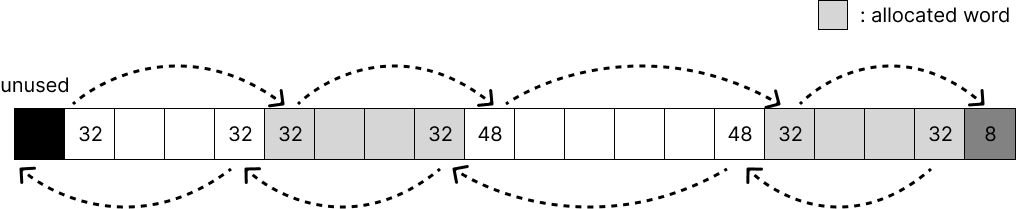
boundary tag를 반영한 모습이다.
다시 Coalescing
boundary tag가 반영된 상태에서 메모리가 free되었다면 다음과 같은 4가지 경우가 존재한다. 노란 칸은 막 free된 block이라고 생각하자.

- case 1의 경우에는 딱히 변하지 않는다.
- case 2의 경우에는 free된 block 다음에 free block이 오는 경우다. free된 block의 header + 이후의 free block footer를 합쳐 하나의 큰 free block을 만들면 된다.
- case 3의 경우에는 free된 block 이전에 free block이 오는 경우다. 이전 free block의 header + free된 block footer를 합쳐 하나의 큰 free block을 만들면 된다.
- case 4의 경우는 free된 block 전후에 모두 free block이 있는 경우다. 이전의 free block의 header + 이후의 free block footer를 합쳐서 하나의 큰 free block을 만들면 된다.
Heap 구조 + Boundary Tag

전체가 반영된 heap 구조는 위와 같다. heap의 시작과 끝에는 의도치 않은 coalescing을 막기 위해 prologue / epilogue block을 둔다. 둘 다 allocated된 상황을 위해 a bit를 1로 설정한다. prologue block의 경우에는 header/footer가 모두 있고, epilogue block의 경우에는 size를 0으로 두어 heap이 끝났다는 것을 표기한다.
Boundary Tag의 단점과 해결
header와 footer를 두어야 하기 때문에 항상 internal fragmentation이 발생한다. 이를 어떻게 줄일 수 없을까?
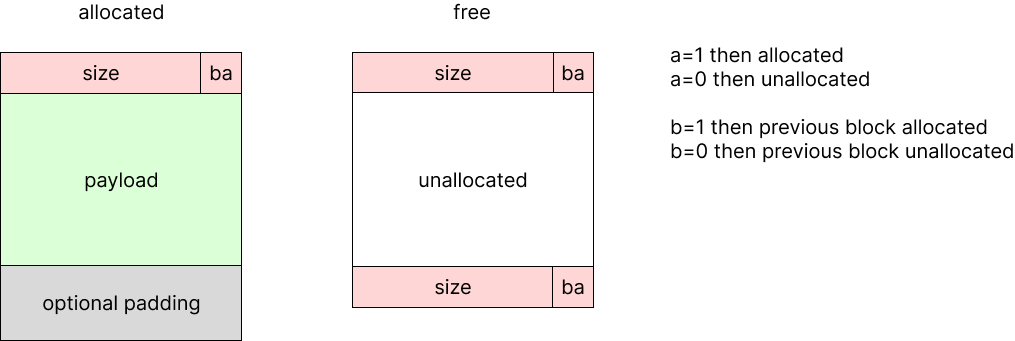
사실상 생각해 보면 boundary tag는 free block에만 필요하다. boundary tag는 coalescing을 위해 생긴 것이기 때문인데, 위와 같이 allocated block은 footer가 없는 경우를 생각해 보자.
할당할 때를 생각해 보면 free block을 찾기에 boundary tag가 없을 때처럼 똑같이 순회하면 된다. 어떤 block p를 해제할 때는 p block size를 가지고 있기 때문에 p 다음에 있는 block header의 a bit로 allocated 여부를 쉽게 알 수 있다. 따라서 coalescing을 위해서는 이전 block이 allocated인지만 알면 된다.
일반적으로 적용하는 double word alignment를 적용하면 block 크기는 항상 8이 된다. 따라서 size의 하위 3비트는 항상 0이다. 그래서 header & 0x1을 하면 allocated인지 여부를 알 수 있다. size를 가져올 때는 header & ~0x7을 하면 된다.
앞서 size bit의 1, 2, 3번째 자리가 비기 때문에 LSB를 a bit로 쓴다고 했다. 그래도 2개의 bit가 남는데, 2번째 LSB를 b bit로 두어 [이전 block의 allocated 여부]를 표기한다. 그러면 p 이전/이후에 있는 block의 allocated 여부를 알 수 있게 된다! 그러면 coalescing의 4가지 케이스에 따라 처리하면 된다.
요약
- 구현 쉬움
- allocate worst time complexity : linear
- free time complexity : constant
Explicit Free List
지금까지 살펴본 바에 따르면 free block을 찾는 것이 제일 중요하다. implicit free list의 경우 allocated/free block header에 size를 두어 크기를 유추하는 방식이었다. 반면 explicit free list는 모든 block 대신 free block만 관리하는 방법이다.
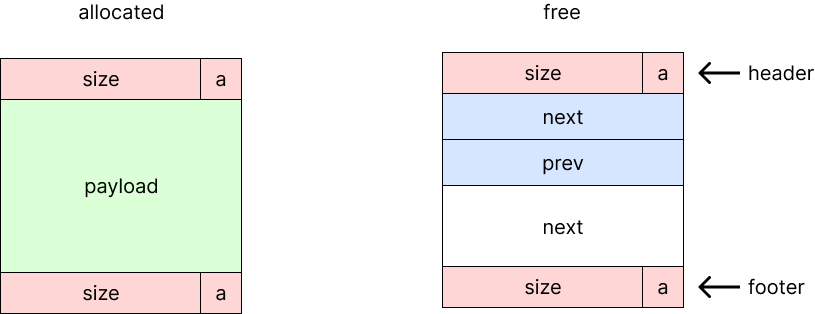
위와 같이 boundary tag를 두되 free block에는 prev와 next pointer를 두어 free block끼리 doubly linked list를 구성한다. 따라서 메모리에 연속적으로 오는 것이 아니라 메모리의 어떤 위치에 있더라도 free block을 가리킬 수 있기 때문에 allocation time을 O(free block 개수)로 줄일 수 있다.
단, free time은 알고리즘에 따라 차이가 난다.
- 순서 없이 관리
- LIFO : free한 block을 free list의 처음에 넣는 방법.
- FIFO : free한 block을 free list의 마지막에 넣는 방법.
- 이 방법은 쉽고 간단하며, 삽입/삭제에 O(c)만큼이 걸린다. 그렇지만 fragmentation이 주소로 정렬하는 방식보다 더 많이 발생한다.
- 주소로 정렬해서 관리
- free list를 주소순으로 관리하는 것이다. 이 경우 삽입할 때 탐색 시간이 필요하지만 fragmentation이 덜 발생한다는 연구 결과가 있었다.
Implicit Free List와 비교
explicit free list의 경우 implicit free list에 비해 allocation이 훨씬 빠르다는 장점이 있다. 단점으로는 free block size가 4word(header, footer, pointer 2개) 필요하기 때문에 internal fragmentation이 발생한다는 것이다.
이러한 단점을 극복하기 위해 linked list 형태의 free list는 segregated free list형태로 사용한다.
Segregated Free List
여러 개의 free list의 array를 유지하되, 각 free list는 거의 비슷한 크기의 free block들만 관리하는 것이다.

위 그림은 segregated free list의 예시이다. 제일 위의 free list는 block size 1~2인 block들만 관리하고, 그 아래 free list는 block size 3인 free block만 관리한다.
allocation 시에는 free list array에서 allocation 크기보다 큰 free block을 찾는다. 있다면 block split 이후 남는 free block을 적당한 free block에 붙여넣는다.(따라서 optimal이다.) 만약 없다면 sbrk()를 호출해 heap을 늘리는 방식을 가진다.
free 시에는 coalescing을 한 후 free list에 집어넣는다.
장단점
장점은 allocation / free가 O(c)이기 때문에 throughput이 높으며, 낭비되는 block이 거의 없기 때문에 memory utilization 또한 높다. segregated free list에서 first fit 방식은 best fit에 근사하기 때문이다.
단점으로는 external fragmentation에 취약하다. 예를 들어 첫 번째 free list size를 allocate/free하고, 두 번째 free list size를 allocate/free하고, ... 이를 반복하면 어느 순간 coalescing이 일어나지 않으며, 이러한 패턴이 몇 존재한다. 이러한 극단적인 패턴에서 external fragmentation이 발생한다.
Garbage Collection
application이 직접 free하지 않고 사용하지 않는 dynamic allocated space를 자동적으로 free해주는 기법이다. 대표적으로 Mark&Sweep collection, Referencing count, Copying collection, Generational collector 방식이 있다.
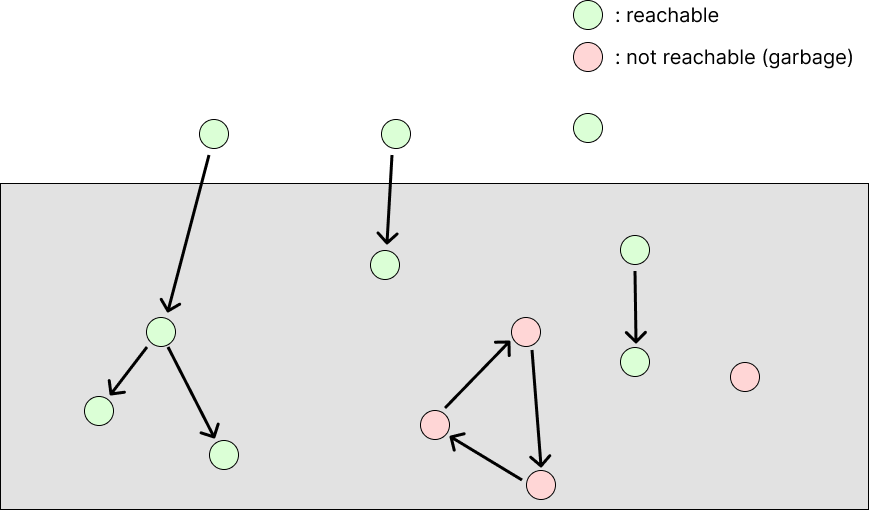
사용하지 않는 allocated memory임을 어떻게 알 수 있을까? 바로 해당 memory를 가리키는 pointer가 없을 때이다. heap에 있지 않지만 heap 영역을 가리키는 pointer를 root라고 하자. memory와 pointer를 하나의 graph로 보아 root로부터 reachable한 것은 아직 사용중인 allocated block이고, unreachable한 것은 더 이상 사용하지 않는 garbage로 보아 이러한 block들을 free한다.
Mark & Sweep
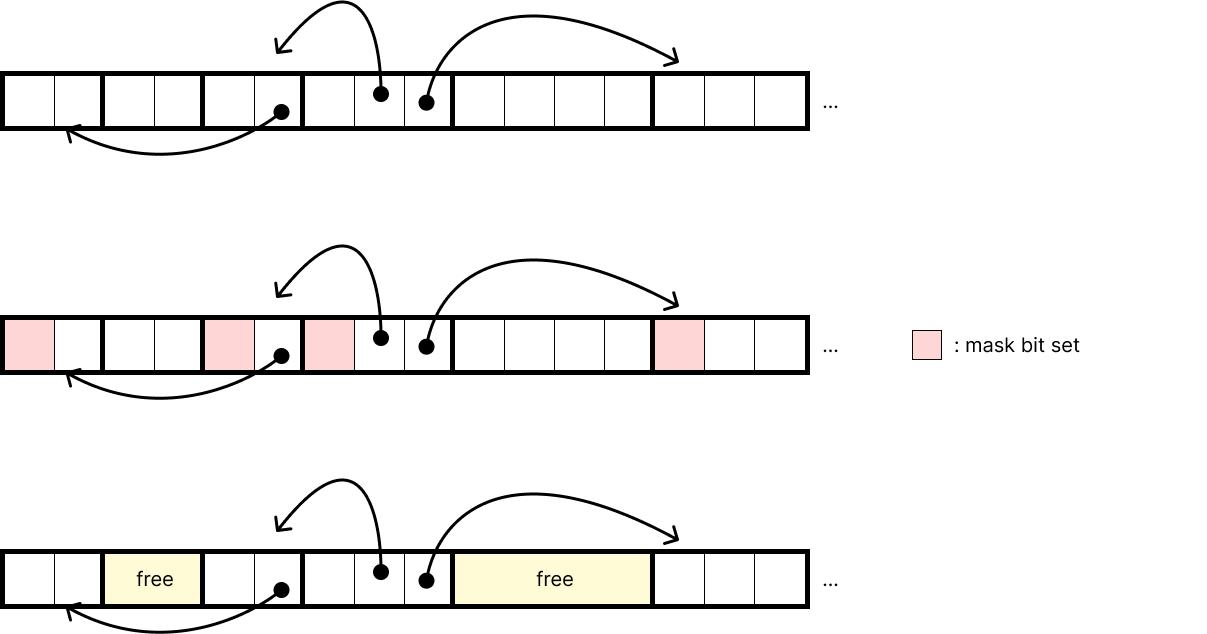
Mark&Sweep은 이를 구현한 대표적인 방식이다. 각 header의 LSB 3개는 사용해도 되는 bit인데, a와 b bit를 사용하더라도 하나가 남는다. 이렇게 남는 bit를 mark bit로 사용한다.
- root와 root에서 reachable한 모든 block에 mark bit를 1로 설정한다.
- mark bit가 0인 모든 allocated block을 free한다.
단, 모든 block을 순회하기 때문에 시간이 많이 걸린다. 따라서 더 이상 allocate할 수 없는 run out of memory 등의 에러가 발생했을 때 Mark & Sweep 알고리즘을 작동한다.
주의해야하는 memory referencing in C
C의 경우 주소값으로 메모리에 직접 접근하기 때문에 항상 유의해야 한다.
- bad pointer dereferencing
- 초기화되지 않은 pointer 참조
- 잘못된 memory size 접근 (out of index)
- buffer overflow
- 잘못된 pointer 연산 (연산 순서 유의)
- 여러 번 free
- free한 pointer 참조
- memory leak (free하지 않은 경우)
잘못된 내용이나 지적, 오탈자 등은 언제나 환영합니다.
'CS > OS' 카테고리의 다른 글
| [OS] Process (0) | 2023.06.26 |
|---|---|
| [OS] Operating System Overview (0) | 2023.06.25 |
| [컴퓨터 SW] Virtual Memory (0) | 2023.06.21 |
| [컴퓨터 SW] System Level I/O (0) | 2023.06.20 |
| [컴퓨터 SW] Exceptional Control Flow & Process (0) | 2023.06.19 |