![[Network] 1%의 네트워크 - 1. 웹 브라우저가 하는 일](https://img1.daumcdn.net/thumb/R750x0/?scode=mtistory2&fname=https%3A%2F%2Fblog.kakaocdn.net%2Fdn%2FRQkmb%2Fbtsn7q9PSDZ%2FYQaKKhplQaXwmEgSUBLSkk%2Fimg.png)
이 글은 성공과 실패를 결정하는 1%의 네트워크 원리 책(이도희 역)을 기반으로 재구성한 것입니다.
이 글에서는 client가 웹 브라우저에 URL을 입력했을 때 제일 처음으로 무슨 일이 벌어지는지 설명한다. 크게 다음 단계로 나뉜다.
- 웹 브라우저가 HTTP request message를 작성한다.
- 이후 OS에게 DNS server를 통해 name resolution을 맡긴다.
- 이후 OS protocol stack에게 request message를 보내달라고 한다.
keywords : browser, web server, URL, URI, HTTP, protocol, resolver, socket, DNS server, name resolution
HTTP Request Message 작성
사용자가 웹 브라우저에 URL을 입력하면 웹 브라우저는 URL을 해독하고 HTTP request message를 작성한다. URL이 무엇이고 어떤 과정을 거쳐 해독하는지, HTTP request message는 어떻게 작성하는지 살펴보자.
URL 해독
URL, User Resource Locator
URL은 네트워크에서 resource가 어디에 있는지 알려주는 규칙이다.
http, ftp, mailto 등 여러 종류의 protocol이 있다. http는 web server에 접근할 때, ftp는 파일 서버에 접근할 때 사용한다.
URL은 다음과 같이 구성되며, username, password, port number, file path는 생략 가능하다.
[protocol]//[username]:[password]@[domain]:[port number]/[file path]
예시)
http://user:password@hyelie.tistory.com:80/dir/file.html
file path를 작성할 때는 file 이름을 생략할 수 있다. 그러나 file 이름을 작성하지 않는 경우 어떤 file에 접근해야 하는지 모르기 때문에, file 이름을 생략할 때 어떤 파일에 접근할지 서버가 미리 설정해 둔다. file 이름을 생략하는 경우는 크게 아래 4가지가 있을 것이다.
- http://hyelie.tistory.com/dir/
- /dir/의 다음에 file 이름이 와야 하는데 생략된 경우이다. 서버가 /dir/에 대한 default file을 index.html로 설정해 둔 경우 /dir/index.html에 접근한다.
- http://hyelie.tistory.com/
- 위와 같은 경우로, / 다음에 file 이름이 와야 하는데 생략된 경우이다. 서버가 /에 대한 default file을 index.html로 설정해 둔 경우 /index.html에 접근한다.
- http://hyelie.tistory.com
- 이번에는 root directory인 첫 /까지 생략되어 있다. file path가 아예 없는 경우 root directory인 /의 default file을 가져온다.
- http://hyelie.tistory.com/temp
- 이 경우 /temp라는 file이 있으면 해당 file에 접근하고, 없으면 temp를 directory로 본다.
URI, URN
URI는 Uniform Resource Identifier의 약자로, resource의 식별자이다.
URN은 Uniform Resource Name의 약자로, resource의 이름이다. URN은 resource의 위치에 영향을 받지 않는 고유한 이름을 가지고 있다. 대부분 사용하지 않으므로 신경쓰지 않고 넘겨도 된다.
URL ⊂ URI이다.
URN은 resource의 이름이라는 개념으로 쉽게 받아들일 수 있는데, URI와 URL의 차이는 조금 이해하기 힘들다. URL는 resource의 위치를, URI는 resource의 식별자를 의미한다. 주소를 알고 있으면 식별할 수 있는 게 아닌가?...
아래 예시를 보자.
- http://hyelie.tistory.com/index.html?page=1&id=1
- http://hyelie.tistory.com/index.html?page=2&id=2
URL은 resource index.html의 위치인 http://hyelie.tistory.com/index.html을 가리킨다. 따라서 같은 URL이다. 그러나 뒤에 붙은 query string에 따라 다른 resource가 출력된다. 따라서 다른 URI이다.
위 예시에서 볼 수 있듯 URL은 resource를 identify할 수도 있고, 아닐 수도 있다. 그러면 URL ⊂ URI라는 것이 확실해진다. 즉 resource를 식별할 수 있으면 URI이고, resource의 위치를 나타내면 URL이다. URL만으로 resource를 identify할 수 있으면 URL이자 URI이다.
HTTP Request Message 작성
HTTP, HyperText Transfer Protocol
HTTP는 client와 server의 통신 protocol으로, 주고받는 메시지의 내용과 순서를 정한 것이다.
웹 브라우저가 URL을 해독하면 HTTP를 사용해 web server에 접근한다. HTTP는 크게 2가지 단계로 나뉜다.

- client가 server에게 method와 URI가 담긴 request message를 보낸다.
- server가 request message를 받으면 server는 method와 URI를 분석하고 결과와 status code를 response message에 담아 보낸다.

request message와 response message는 위 그림과 같이 생겼다.
둘 모두 첫 줄에는 간단한 요약 정보, 그 다음 줄부터 개행까지는 header, 그 이후에 body가 온다.
참고로 request message가 GET을 사용하는 경우 method와 URI로만 동작을 결정하므로 body에는 아무것도 오지 않는다.
HTTP method
HTTP method는 client가 어떤 동작을 하고 싶은지를 의미한다. web back-end를 해 봤다면 많이 사용하는 그 코드들이며 GET, POST, PUT, PATCH, DELETE를 주로 사용한다. HTTP request method 목록
| method | HTTP 1.0 | HTTP 1.1 | 의미 |
| GET | O | O | client가 server에게 데이터 요청 |
| POST | O | O | client에서 server로 데이터 송신 |
| PUT | O | resource 치환 (전체 변경) | |
| PATCH | O | resource 갱신 (일부 변경) | |
| DELETE | O | resource 삭제 |
Status Code
status code는 server가 client에게 응답할 때 응답 상태를 의미한다. 200번대는 응답이 성공적일 때, 400번대는 잘못된 요청을, 500번대는 서버 오류가 발생했을 때를 의미한다. HTTP response status code 목록
Message Header
message header는 message에 붙이는 추가적인 정보이다. Date(작성 날짜), Connection(연결 지속 여부), Authorization(인증), Content-Language(언어), Expires(유효 기간) 등의 정보를 작성한다. 필요할 때 모든 내용을 작성한다. HTTP header 목록
DNS 서버에 IP를 조회
HTTP request message를 만들면 웹 브라우저는 OS에게 request message를 server에게 보내달라는 요청을 한다. 이 때 송신 시 domain이 아니라 IP로 목적지 주소를 식별하기 때문에 URI 안에 있는 domain을 이용해 IP를 얻어와야 한다.
패킷 운반 과정 개략적 설명
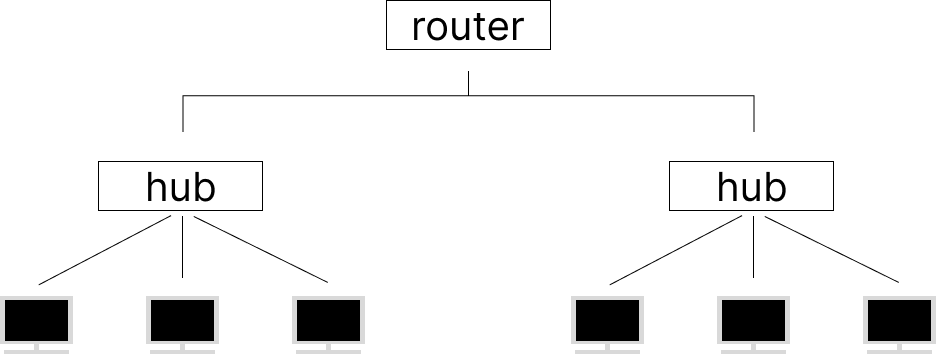
인터넷은 위 그림처럼 [1개 이상의 컴퓨터가 접속된 hub], subnet과 subnet이 접속된 router들의 연결을 말한다.
어떤 client가 송신한 message는 해당 subnet을 관리하는 hub가 받고, hub는 제일 가까운 router로 간다. router는 IP 주소를 보고 다음 router를 판단하고 그쪽으로 넘기는 방식으로 전달된다.
IP address
IP address는 네트워크의 주소이며, 네트워크 번호와 호스트 번호로 구성되어 있다. 네트워크 번호는 hub에 해당하는 주소, 호스트 번호는 hub 안의 컴퓨터에 해당하는 주소이다.
네트워크 번호를 OO동, 호스트 번호를 OO번지라고 생각하면 이해하기 쉽다.
IP address는 32bit로 표시하며, 8bit씩 쪼개어 각 8bit를 255 이하의 음수가 아닌 정수로 표시하며, .으로 구분한다. host 번호에 해당하는 bit가 모두 0이거나 1인 경우에는 특별한 정보를 의미한다.
- 호스트 번호가 모두 0인 경우 : subnet 자체를 의미한다.
- 호스트 번호가 모두 1인 경우 : subnet 전체에게 broadcast를 의미한다.
이 때 네트워크 번호와 호스트 번호를 구분하기 위해 netmask를 사용한다.
netmask는 IP address처럼 32bit이며, 111...11000...00과 같이 [1이 연속된 부분]과 [0이 연속된 부분]으로 이루어져 있다. [1이 연속된 부분]에 해당하는 부분, 즉 IP address & netmask의 결과물이 네트워크 번호로, [0이 연속된 부분] - IP address & !netmask의 결과물이 호스트 번호가 되는 것이다.
netmask는 IP address와 같은 방식으로 표기할 수도 있고, 네트워크 번호의 bit 수로 표현할 수도 있다.
예시)
10.11.12.13/255.255.255.0
- 네트워크 번호는 10.11.12, 호스트 번호는 13
10.11.12.13/24
- 마찬가지
domain과 IP address를 구분해 사용하는 이유
실제로는 IP address로 수신할 상대를 결정하지만, 앞에서는 domain을 이용해 http request message를 만들었다.
그러나 IP address는 외우기 어렵기 때문에 사람에게 친숙한, 문자열을 사용하는 domain을 이용한다. 그러나 IP address는 4byte인 반면 domain은 최대 255byte까지 늘어날 수 있기 때문에 domain으로 수신측을 찾기에는 네트워크의 부하가 너무 많이 실린다. 때문에 domain과 IP address를 매핑시킨 DNS, domain naming system을 사용한다.
사람은 domain(문자열)을 사용하고 router는 IP address를 사용한다.
IP address 찾기 : resolver 사용
DNS server에 질의해서 domain에 해당하는 IP address를 찾을 수 있다.
즉슨 DNS server에게 request message를 보내고 response message를 받는 것인데, 이 때 DNS server에게 request를 날리는 부분을 DNS resolver라고 부르며, 이 과정을 name resolution이라 부른다. 참고로 DNS server에게 request를 날릴 때도 DNS server의 IP address가 필요한데, 이는 컴퓨터에 내장되어 있는 값을 사용한다.
resolver는 socket library에 내장되어 있으며 gethostbyname()을 호출해 부른다.
application이 gethostbyname()을 호출해 resolver를 부르면, resolver는 내부적으로 DNS 서버에 request를 날리고 response를 받는다. 이 때 message를 보내고 받는 과정 OS 내부의 protocol stack이 처리한다. 대충 flow를 그리면 아래와 같다.
// application
main(){
// ...
host = gethostbyname("hyelie.tistory.com");
// ...
}// socket library
gethostbyname(){
msg = makeMessage(); // 1. DNS server에게 보낼 request message 만듬
sendMessage(msg); // 2. DNS server에게 request message 보냄
result = receiveMessage(); // 3. DNS server로부터 response message 받음
return result; // 4. return
}// protocol stack in OS
sendMessage(){
// ... 송신
}
receiveMessage(){
// ... 수신
}
DNS request message
DNS request message는 크게 아래 3가지 정보가 있다.
- 이름 : domain name
- class : 현재는 internet만 사용하므로 무조건 IN을 사용한다.
- type : A 또는 MX를 사용한다. A는 IP address, MX는 mail을 지원한다.
DNS의 작동
DNS의 구성
DNS server에는 DNS request message에서 사용하는 3가지 정보에 추가로 resource record가 들어가서 [이름, class, type, resource record]로 총 4가지 정보가 들어가 있다. DNS server는 [이름, class, type]으로 resource record를 식별하고, DNS request message가 왔을 때 resource record를 response로 보낸다.
Domain Hierarchy & DNS Server Hierarchy
하나의 DNS server에 모든 domain을 넣기에는 domain이 너무 많기 때문에 여러 개의 DNS server로 hierarchy를 만든다. (tree 구조를 생각하면 된다.) 때문에 domain도 hierarchy로 나뉘며, .으로 구분한다. 뒤에 있는 domain이 더 큰 domain이다.
추가로 모든 domain의 최상위에 root domain이 있다.
hyelie.tistory.com라는 domain name을 생각해 보자.
제일 상위에는 com, 그 아래 tistory, 그 아래 hyelie라는 domain이 온다.

DNS server 또한 hierarchy가 있다. 제일 위에는 root domain이 있고, 그 아래로는 [자신이 가지고 있는 domain의 바로 아래 계층에 있는 domain에 해당하는 DNS server]을 가지며, 이것이 계속 반복되며 tree 구조를 만든다. 이 때 [바로 아래 계층에 있는 domain에 해당하는 DNS server IP address]를 해당 domain에 저장한다. parent DNS server가 child DNS server의 IP를 가지고 있기 때문에 root domain부터 아래로 내려가면 원하는 domain에 해당하는 IP를 찾을 수 있는 구조이다.
참고로 root domain은 모든 DNS server에 등록되어 있다!
hyelie.tistory.com라는 DNS server hierarchy를 예로 들자.
root DNS server 안에 com DNS server의 IP address가 있고,
com DNS server에 tistory DNS server IP address가 있고,
tistory DNS server에 hyelie DNS server IP address가 있다.
Name Resolution 과정
이런 hierarchy를 가진 DNS server에서 resolution 과정은 아래와 같다.
예시로 hyelie.tistory.com의 name resolution 과정을 살펴보자.
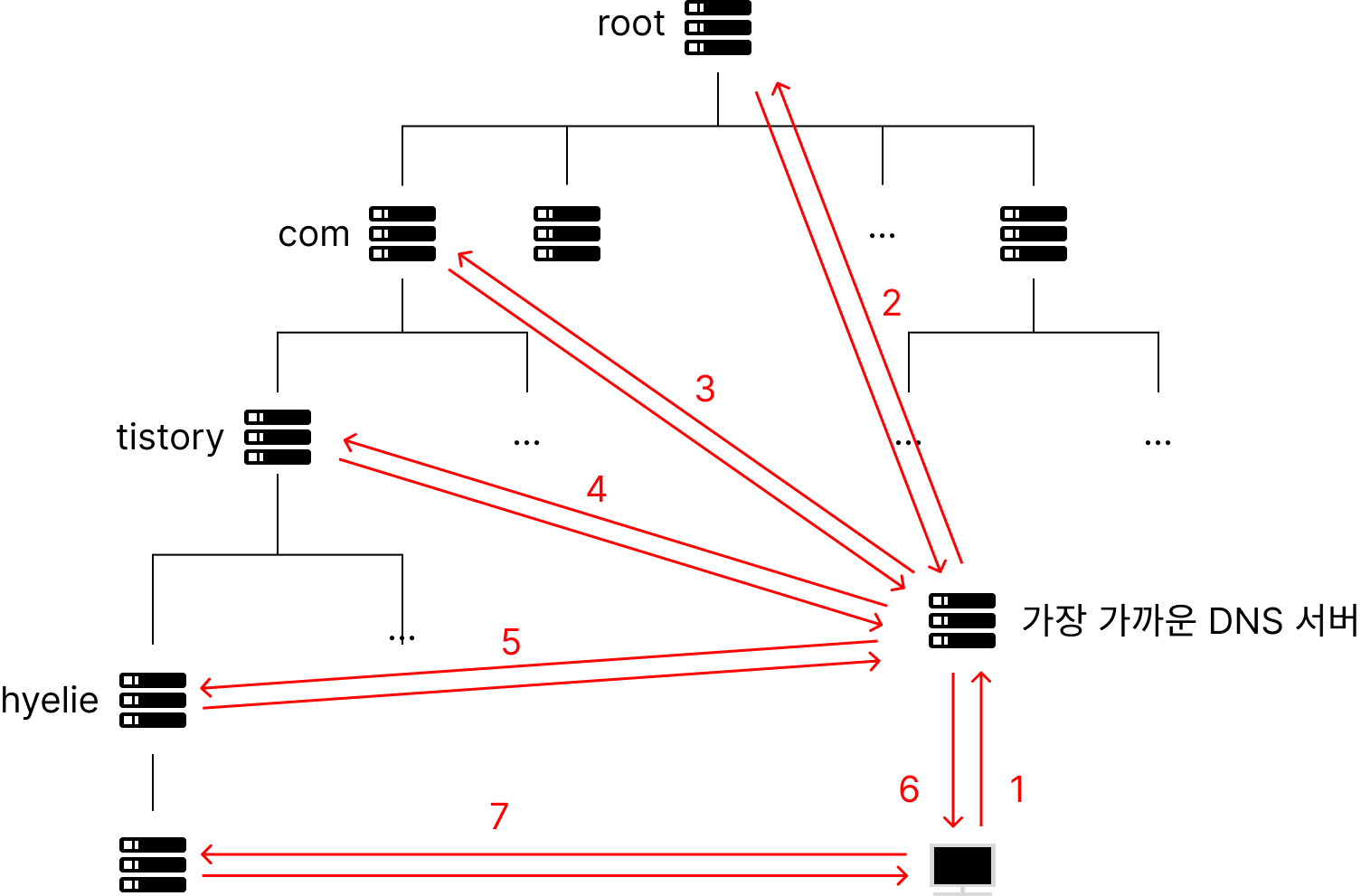
- DNS request message를 만들면 컴퓨터에 있는 DNS server에게 request를 날린다. 이 DNS server는 가장 가까운 DNS server이다. 편의상 C라고 하자.
- 모든 DNS server에는 root DNS server IP address가 있다. C는 root DNS server에 DNS request message를 보낸다.
- root DNS는 하위 domain의 DNS server IP address가 있다는 것을 알고 있다. (위 예시에서는 com) 해당 DNS server IP address를 return한다.
- C가 com DNS server IP address를 받았다. 2번처럼 com DNS server에 DNS request message를 보낸다.
- com DNS server는 tistory domain의 DNS server IP address를 알고 있다. 해당 DNS server IP address를 리턴한다.
- ... 이를 반복해 최종 목적지의 IP address를 얻어낸다.
이러한 과정을 거쳐 목적지로 하는 hyelie.tistory.com에 해당하는 IP address를 알아내며, 이 과정을 name resolution이라 한다.
Name Resoultion : Reality
위 예시에서는 하나의 DNS server가 하나의 domain만 가지는 것으로 예시를 들었다. 그러나 실제로는 하나의 DNS server가 domain이 여러 개 있을 수도 있고, 여러 계층의 domain을 하나의 DNS server에 등록하는 경우도 있다. (이 경우 name resolution은 하나의 계층을 건너뛰게 된다.)
DNS server는 cache를 두기 때문에 최근에 조회한 정보를 더 빨리 찾아낼 수 있다. 이 때 cache에 정보가 저장된 상태에서 DNS server가 가진 내용이 변경되거나 삭제된 경우 cache에 있는 값이 올바르지 않게 된다. 따라서 cache에 유효 기한을 설정하고, 응답할 때 cache로부터 가져온 것인지 DNS server로부터 가져온 것인지에 대한 정보도 알려준다.
Protocol Stack에 요청
name resoultion을 거쳐 server의 IP address를 얻어왔다면 application은 OS의 protocol stack에 request message를 보내달라고 한다. name resolution에서 socket을 사용했던 것과 마찬가지로 이 과정에서도 socket을 사용한다.
server와 client는 다음 과정을 통해 연결된다.
- server가 socket을 만들고 대기한다.
- client가 socket을 만든다.
- client가 server의 socket에 연결한다.
- client와 server가 socket을 통해 데이터를 주고받는다.
- socket 연결을 끊는다.
소스 코드로 표현하면 아래와 같다.
ip = gethostbyname("hyeile.tistory.com");
socket_desciptor = socket(); // ... socket 생성
connect(socket_desciptor, ip:port, ...); // 접속
write(socket_descriptor, ...); // 송신
result = read(socket_descriptor, ...): // 수신
close(socket_descriptor); // 연결 끊기- socket_desciptor는 socket의 식별자이다. socket이 여러 개 생길 수 있기 때문에 필요하다.
접속 : Port 번호
위에서 name resolution을 통해 server의 IP address를 얻어왔다. 그러나 IP만으로는 server의 어떤 process에 접속할지 정할 수 없다. 이를 위해 네트워크 서비스나 특정 process를 식별하는 번호인 port 번호를 추가해 사용한다.
port는 socket 통신에서 필요하기 때문에 client와 server 둘 다에서 필요하다.
server에 접속할 때 사용하는 port는 앱이나 protocol의 종류에 따라 약속된 값을 사용한다. 대표적으로 80은 htttp, 443은 https, RDP는 3389로 약속되어 있다.
반면 client의 port는 socket을 만들 때 OS의 protocol stack이 적당한 값을 골라서 할당하고, server에 접속할 때 이를 알린다.
데이터 송/수신
port를 이용해 socket이 연결 된 상태에서 write()를 호출하면 작성한 request message가 연결된 socket의 반대편인 server측으로 보내진다. (이 경우에는 HTTP request message가 server socket으로 보내질 것이다. 다른 protocol인 경우 해당 protocol request message가 보내질 것이다.) server측에서 이 message를 받으면 protocol stack의 수신 동작이 실행되고, 해당 응답에 대한 연산 결과값을 만들어 response message로 보낸다.
message를 수신하면 protocol stack은 receive buffer 안에 response message를 잠시 저장해 둔다. process가 scheduler에 의해 자신의 차례가 되거나 interrupt가 발생하면 receive buffer로부터 message를 꺼내 읽는다.
연결 끊기
close()를 호출하면 socket library가 연결을 끊는 protocol을 실행하고 연결이 종료된다.
일반적으로 web에서는 server가 close()를 호출해 연결을 끊으면, client는 연결되어 있는 socket을 통해 이 message를 읽고 socket 연결을 끊는 과정을 진행한다. 이 때 단순히 한 쪽에서 끊는 것이 아니라 "이제 연결을 종료하자. OK? OK."처럼 서로가 확인하는 과정을 거쳐 연결이 종료된다.
잘못된 내용이나 오탈자에 대한 지적, 질문 등은 언제나 환영합니다.
'CS > Network' 카테고리의 다른 글
| [Network] 1%의 네트워크 - 5. Firewall, Proxy, Load Balance (0) | 2023.07.24 |
|---|---|
| [Network] 1%의 네트워크 - 4. 인터넷 내부 (0) | 2023.07.24 |
| [Network] 1%의 네트워크 - 3. Cable, Hub, Router (1) | 2023.07.21 |
| [Network] 1%의 네트워크 - 2. OS Protocol Stack과 LAN Adapter (0) | 2023.07.20 |
| [Network] 1%의 네트워크 - 0. 서론 (0) | 2023.07.19 |