![[Network] 1%의 네트워크 - 5. Firewall, Proxy, Load Balance](https://img1.daumcdn.net/thumb/R750x0/?scode=mtistory2&fname=https%3A%2F%2Fblog.kakaocdn.net%2Fdn%2FC6C2i%2Fbtsoyp3RVLd%2FBU1ArFJ0FCmUSt1QZWDF40%2Fimg.png)
이 글은 성공과 실패를 결정하는 1%의 네트워크 원리 책(이도희 역)을 기반으로 재구성한 것입니다.
이전 포스팅에서 인터넷 내부로 들어간 packet이 access 회선과 provider의 PoP/NOC를 거쳐 목적지로 도달했다. packet은 server 앞에 있는 방화벽/cache server/load balancer를 거친다. 이 장에서는 방화벽, cache server, load balancer를 설명한다.
keywords : 방화벽, packet filtering, load balancer, proxy, cache server, redirect
web server 설치 장소
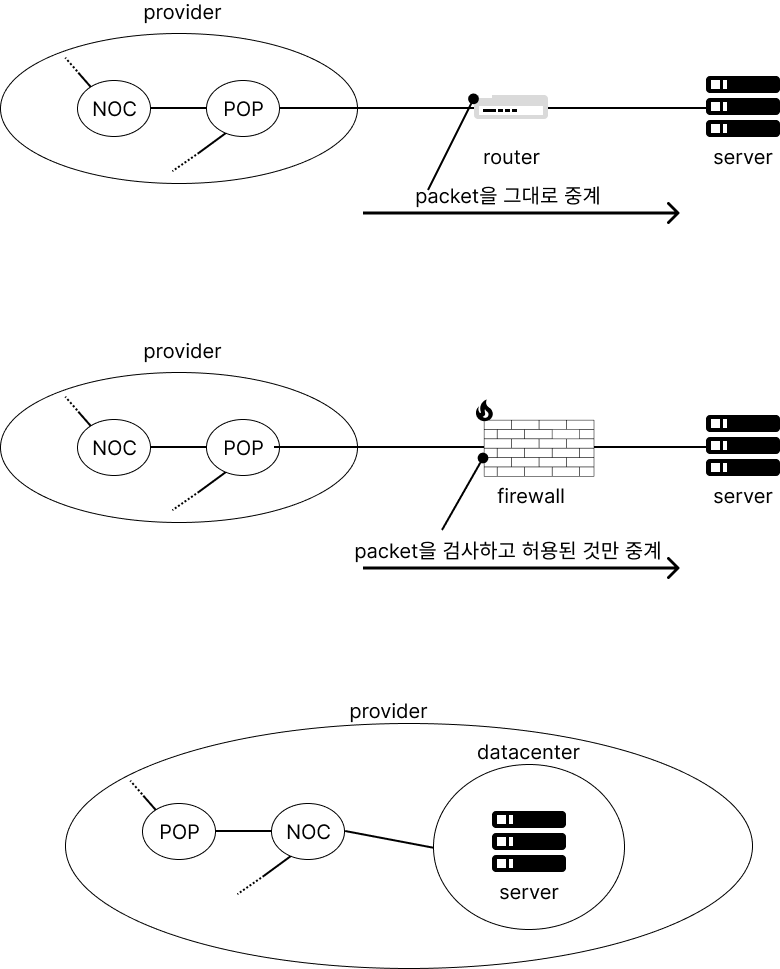
server를 설치하는 위치는 크게 3가지이다.
- 사내 LAN에 server를 설치하고 인터넷에서 직접 access하는 경우
- 이 경우 PoP의 router, access 회선, server router를 경유해서 서버에 도착한다.
- client에도 global IP address를 할당해야 해서 IP address가 부족한 지금은 선택하지 않는다.
- server에 packet이 바로 도착하기 때문에 보안상의 이유로 하지 않는다.
- 사내 LAN에 server를 설치하고 방화벽으로 분리하는 경우
- 방화벽은 특정 서버에서 동작하는 특정 APP에 접근하는 packet만 통과시킨다. (그러나 완전히 안전한 것은 아님)
- 통신회사의 datacenter에 설치하는 경우
- provider의 datacenter 안에, 또는 provider server를 빌리는 경우이다. provider의 중심부에 있는 NOC와 직접 연결되거나 IX에 연결되기 때문에 빠르고 재난 등에 안전하다.
방화벽
방화벽은 특정 server와 해당 server의 특정 app에 접근하는 packet만 통과시키며, 주로 packet filtering을 쓴다.
packet을 거르는 방법
packet에는 여러 종류의 header가 있고, 각각의 header에는 많은 정보가 있다.
- MAC header (송신처 MAC address)
- IP header (송/수신처 IP address, protocol 번호)
- TCP/UDP header (송/수신처 port, TCP control bit, fragement)
이 때 위 3개 header에 있는 정보를 사용해 filtering한다.

- 먼저 송/수신처 IP address에 따라 시점/종점을 판단한다. 위 그림에서는 internet에서 web server로 packet이 흘러오는데, 이는 수신처 IP address로 판단할 수 있다.
- 해당 packet이 어떤 app에 사용되는지 port로 판단한다. port는 network service나 process를 특정할 때 사용하므로, 어떤 app에게 들어가는 packet인지 검사할 수 있다.
- TCP를 사용하는 경우 internet과 web server 양방향으로 packet이 흐르기 때문에 access 방향을 판단해야 한다. 이 때 TCP header의 control bit를 사용한다.
이외에도 다른 값들을 사용해 filtering할 수 있다.
그렇지만 실제로는 filter할 것을 완벽하게 고를 수는 없는데, DNS server access가 그 예시이다. DNS server access의 경우엔 UDP를 사용하는데, UDP는 TCP와 달리 접속 과정이 없기 때문에 access 방향을 판별할 수 없다. 이렇듯 UDP는 packet 차단이 힘들다. 이 경우 위험을 감수하고 packet을 통과시키거나, app 차단시키는 방향을 선택해야 한다.
주소 변환
packet filtering 방식으로 작동하는 방화벽은 주소 변환도 할 수 있다. (internet과 server를 왕복하는 packet은 주소 변환을 해야 한다.) packet filtering처럼 packet의 시점/종점을 조건으로 지정한 후 주소 변환이 필요할 때 주소 변환한다. router의 주소 변환과 동일하게 internet에서 독립망으로 접속할 수 없다.
로그
packet을 차단시키면 방화벽은 log를 남긴다. 통과시키는 경우에는 router와 동일하게 packet을 중계한다.
막을 수 없는 공격
packet 내부는 확인하지 않으므로 악의적인 packet data가 들어오면 못 막는다. 따라서 web server 자체의 보안도 신경써야 한다.
Load Balancing
server access 회수가 너무 많을 때는 서버를 고성능으로 만들거나 서버 1대당 처리량을 낮추는 방법(분산처리)가 있다. 분산처리의 가장 간단한 방법은 여러 개의 web server를 설치한 후 1/n으로 부하를 분산시키는 방법이다.
DNS server에서 분배
- DNS server에 여러 IP address를 등록해 주면 조회 시 차례대로(round robin) return한다.
- 예를 들어 127.0.0.1, 127.0.0.2, 127.0.0.3을 DNS server에 등록해 두면 첫 조회에는 127.0.0.1을, 다음 조회는 127.0.0.2를, 다음에는 127.0.0.3을, 다음에는 127.0.0.1을, ... 리턴한다.
- 단점으로는 DNS server는 작동을 멈춘 web server를 확인할 수 없기 때문에, server의 상태에 상관없이 그대로 IP address를 리턴한다. 또한 복수의 page와 연속해 대화해야 할 때, 끊길 수도 있다.
Load Balancer 사용
DNS server에서 분배하는 방식의 단점을 보완하기 위해 load balancer를 사용한다.

load balancer를 DNS에 등록하면, client는 load balancer로 요청을 보내게 된다. load balancer는 내부적인 로직에 따라 어떤 web server에 request를 날릴지 판단하고 해당 web server에 request를 분배한다. 이에 대한 판단 근거로는 다음 몇 가지가 있다.
- 복수 page에 걸치는지 - HTTP는 매번 request가 별개로 동작하기 때문에 전후 관계를 알기 위해 HTTP header에 cookie를 추가한다.
- CPU/memory 사용률
cache server를 이용한 부하 분산
cache server는 proxy를 사용해 data를 cache에 저장하는 server이다.
proxy는 web server에 대한 접근을 중개하는데, 이 때 web server의 data를 저장해 두고 web server 대신 client에 반송한다. (일종의 cache)
web server는 url 점검, access 권한 확인, 등 시간이 걸리지만 cache server는 data 송신만 하므로 빠르다. 이 때 cache는 데이터를 저장만 하기 때문에 업데이트 시 server에 직접 반영해야 한다.
cache server의 동작

- cache server는 load balancer처럼 cache server를 DNS server에 등록한다.
- client는 cache server에 요청을 보내고, cache server는 request message를 조사한 후 자신에게 data가 있는지 본다.
- 이 때 data가 없는 경우 동작은 다음과 같다. (cold miss)
- cache server를 경유한 것을 나타내는 via header field를 추가해 web server에 request를 날린다.
- 만약 server가 여러 대이면 URI를 기반으로 directory를 선택하는 등의 방법으로 server를 선택한다.
- server로 request를 날리고, 돌아오면 그 값을 cache에 저장함과 동시에 client에게 응답한다.
- data가 있는 경우 동작은 다음과 같다. (cache hit)
- web server에서 data가 수정되었는지 알기 위해 if-modified-since header field를 추가해 web server에 request를 날린다.
- 변경이 없다면 cache에 있는 값을 바로 리턴하고, 변경이 있다면 cache를 갱신하고 client에게 응답한다.
- 이 때 변경이 있다면 cache를 갱신함과 동시에 via header field를 추가해 client에게 response한다.
이 방식을 reverse proxy라고도 한다.
Proxy
forward proxy
forward proxy는 client에 cache server를 두는 방법이다. forward proxy가 proxy의 원형이며, 초기에는 cache server와 동시에 방화벽의 역할을 수행해 외부로부터 부정 침입을 막는 역할을 했다.
방화벽의 경우 packet을 모두 차단시키는데, 이 경우 internet access도 멈춘다. 이를 해결하기 위해 client request를 proxy에서 잠시 받고, proxy가 server에 access하는 방식을 취했으며, 동시에 cache의 역하을 해 더 빠르게 접속할 수 있다.
forward proxy를 사용하지 않은 경우 입력한 DNS에서 web server를 찾아내지만 forward proxy를 사용하는 경우 forward proxy가 web server에 request를 보내고 받은 후, response를 client에게 돌려주는 방식이다.
reverse proxy
forward proxy의 경우, browser의 proxy 설정이 잘못된 경우에는 장애의 원인이 되기도 한다. 때문에 server 측에 설치하는 cache server에 proxy를 두는 방식을 reverse proxy라고 한다.
transparent proxy
request message packet header를 찾아 access할 web server를 찾을 수 있다. cache server에서 access할 web server를 찾는 방식을 transparent proxy라고 한다.
이 경우 forward proxy처럼 client에서 proxy를 등록하지않아도 되고, 전송 대상을 cache server에 설정하지 않아도 된다. 즉, forward proxy와 reverse proxy의 좋은 점을 모은 형태이다.
그러나 DNS에 등록하지 않기 때문에 web server로 request message가 흘러가는 길목에 transparent proxy를 설치해 해당 message를 가로채고, transparent proxy가 web server와 통신한다.
Content Delivery Service
cache server의 위치

- server에 cache를 두는 경우 web server의 부하를 줄일 수는 있지만 internet traffic은 동일하다.
- client에 cache를 두는 경우 web server의 부하를 줄일 수는 없지만 internet traffic은 줄어든다.
- internet 주위에 cache를 두면 internet traffic도 줄일 수 있고 server 관리자가 cache server를 관리할 수 있기 때문에 web server의 부하도 줄일 수 있다.
이 때 web server 운영자가 직접 cache server를 설치하는 것은 어려운 일인데, 이를 해결하기 위해 provider가 server 운영자에게 cache server를 빌려주는 것을 content delivery service라고 한다.
content delivery service 사용 시 internet에 여러 cache server가 설치되므로 client는 가까운 cache server에 접근하는 구조가 필요한데, 그 구조 중 몇가지를 소개한다.
가까운 cache server 사용
- DNS server가 분배하는 방법. 이 경우 client와 cache server의 거리를 계산한 후 제일 가까운 cache server IP address를 알려준다. 이 때 cache server의 router에서 routing table을 모아 두는데, 이를 보고 client까지 거리를 계산할 수 있다. (정확하진 않지만 근사한다.)
redirect 사용
HTTP header 중 Location header가 있는데, 이를 사용해 access 대상을 다른 server로 돌릴 수 있다. 이를 redirect라고 하며, 이를 사용해 cache server를 분배하는 과정은 다음과 같다.
- DNS server엔 redirect용 server를 등록한다.
- DNS 요청 시 redirect server로 간다.
- redirect server엔 router의 routing table이 있다. 이걸 이용해 location header를 붙여 응답을 보내면 그곳으로 access한다.
이 경우 redirect하는 만큼 overhead가 존재하지만 그러나 IP address를 바탕으로 거리를 계산하므로 정밀도가 높다.
location header 뿐만 아니라 packet 왕복시간으로도 시간을 계산할 수 있다.
cache 비용 갱신
cache의 사본이 여러 개 있는 content delivery service에서는 항상 cache coherence를 심각하게 따져야 한다. 이를 신경쓰기 위해 web server에서 data가 갱신된 경우 cache server에 즉시 등록해야 하는 과정을 거쳐야 한다. 따라서 동적 data는 cache server에 저장하지 않는 편이 더 낫다.
잘못된 내용이나 오탈자에 대한 지적, 질문 등은 언제나 환영합니다.
'CS > Network' 카테고리의 다른 글
| [Network] 하향식 접근 네트워크 - 1. Introduction (0) | 2023.07.26 |
|---|---|
| [Network] 1%의 네트워크 - 6. 마무리 : Web Server Response (0) | 2023.07.24 |
| [Network] 1%의 네트워크 - 4. 인터넷 내부 (0) | 2023.07.24 |
| [Network] 1%의 네트워크 - 3. Cable, Hub, Router (1) | 2023.07.21 |
| [Network] 1%의 네트워크 - 2. OS Protocol Stack과 LAN Adapter (0) | 2023.07.20 |