![[Network] 하향식 접근 네트워크 - 4. Network Layer - (4) Routing Protocol](https://img1.daumcdn.net/thumb/R750x0/?scode=mtistory2&fname=https%3A%2F%2Fblog.kakaocdn.net%2Fdn%2FcQCflq%2FbtspxaJ1dbd%2FlZE1YGMBX7kgepXQToS7T1%2Fimg.png)
이 글은 이화여자대학교 이미정 교수님의 2014년 2학기 컴퓨터 네트워크 강의를 기반으로 재구성한 것입니다. 삽화는 링크를 출처로, 저작권은 J.F Kurose and K.W. Ross에게 있다는 것을 밝힙니다.
network layer에서는 다음과 같은 내용들을 살펴본다.
- network layer principles
- virtual circuit, datagram network
- router의 내부
- IP
- datagram format
- IPv4 addressing
- ICMP
- IPv6
- routing algorithm
- link state
- distance vector
- hierarchical routing
- routing in the internet
- RIP
- OSPF
- BGP
- broadcast, multicast
Routing Algorithm
Routing Protocol
routing protocol은 routing algorithm이 필요한 정보를 수집하는 것이 목적이다. 때문에 routing protocol은 routing algorithm와 매우 밀접한 관계를 가지고 있으며, routing protocol이 routing algorithm을 포함하고 있다.
Routing Algorithm
routing algorithm은 forwarding table을 만들어 packet이 적합한 output port로 나갈 수 있게 하는 것이 목적이다.
routing algorithm은 network의 router들을 vertex N으로, link를 edge E로 추출해 하나의 graph G = {N, E}로 바라보며, 여기서 path cost를 계산한다. 이 때 source host to destination host까지 least cost path를 찾는다.
Routing Algorith의 종류
사용하는 정보에 따라 분류한다.
- global (link state algorithm) : 각 router가 network 전체 정보를 안다는 가정 하에 least cost path를 찾는 방법. 이 경우 모든 router의 정보가 consistent해야 한다.
- decentralized (distance vector algorithm) : 각 router가 자신의 neighbor cost만 안다는 가정 하에 least cost path를 찾는 방법. 이 경우 neighbor에게 destination subnet cost가 담긴 distance vector가 얼만지 물어보면서 알고 있는 정보의 크기를 점점 늘려간다.
위 2개 말고도 다른 분류도 있다.
- static : link cost를 고정으로 설정하는 방법. internet의 경우 link cost를 고정해 사용한다. 자주 실행되지 않는다.
- dynamic : link cost가 변하게 설정하는 방법. congestion 등의 traffic 변화를 반영하기 위해 사용하는 방식이다. 자주 실행된다.
Link State Algorithm : Dijkstra
dijkstra algorithm 그 자체이다.
Dijkstra 알고리즘은 이 글에 포스팅했으므로, 설명은 생략한다.
Distance Vector Algorithm : Bellman-Ford
Bellman-Ford 알고리즘은 이 글에 포스팅했으므로, 설명은 생략한다.
distance vector algorithm은 bellman ford algorithm에 기반을 둔다.
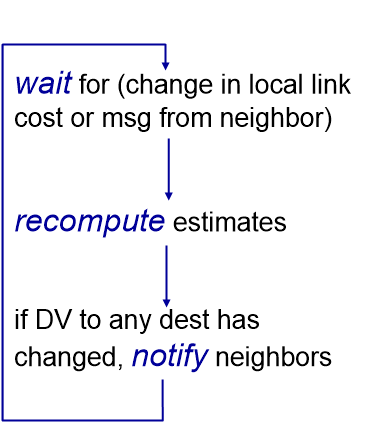
distance vector는 다음과 같은 로직으로 돌아간다.
- 각 router들은 초기에 자신과 neighbor들의 거리 정보를 담고 있는 distance vector를 가지고 있다.
- neighbor로부터 distance vector를 받으면 bellman ford를 사용해 자신의 distance vector를 갱신한다.
- link cost가 변하거나, neighbor의 distance vector가 변하는 경우 neighbor distance vector를 받는다.
- 자신의 distance vector가 변하면 neighbor들에게 다시 알린다.
이러한 과정을 거쳐 점점 더 멀리에 있는 router까지 cost를 알게 된다.
Link Cost Change : Positive
link cost가 줄었다고 가정하자. cost가 줄었기 때문에 destination까지 cost가 줄게 된다.
- 변경된 link를 가진 router가 distance vector를 재계산하고 neighbor router에게 자신의 갱신된 distance vector를 보낸다.
- distance vector를 보낸 neighbor가 distance vector를 갱신하고, 변경 시 neighbor에게 발송한다.
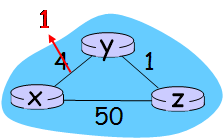
예시로, X-Y cost가 1로 줄었다고 가정하자.
- X, Y는 자신이 가지고 있는 link의 cost가 바뀌었으므로 distance vector를 재계산한다.
- Y가 X, Z에게 알린다. X는 불변, Z만 갱신한다.
- X가 Y, Z에게 알린다. Y는 불변, Z만 갱신한다.
- Z가 갱신한 후 distance vector를 X, Y에게 알린다. X, Y는 불변이다.
Link Cost Change : Negative
반면, link cost가 늘었다고 하자. 이 경우에는 문제가 발생한다.
- 변경된 link를 가진 router가 distance vector를 재계산하고 neighbor router에게 자신의 갱신된 distance vector를 보낸다.
- distance vector를 보낸 neighbor가 distance vector를 갱신하고, 변경 시 neighbor에게 발송한다.
분명 로직은 위와 동일하다. 그러나 아래 예시를 보자.
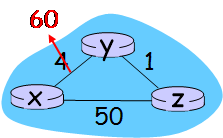
X-Y cost가 4에서 60으로 늘었다고 하자.
- Y는 자신이 가지고 있는 link cost가 바뀌었으므로 distance vector를 재계산한다. 이 때, Y가 가지고 있는 Z의 distance vector를 보았을 때, Y-Z-X로 하면 5만큼에 갈 수 있다는 정보를 바탕으로 계산하고 distance vector를 발송한다.
- Z는 이 정보를 받는다. Y-X가 5만큼에 갈 수 있다는 정보를 바탕으로 Z-Y-X로 가면 6만큼에 갈 수 있다. distance vector를 갱신하고 발송한다.
- ... 이 과정이 계속 반복된다. (예시의 경우 44번)
이렇듯 distance vector algorithm은 path가 자기 자신을 거치는지 모르기 때문에 distance vector의 갱신이 계속 이루어지는데, 이 상황을 count to infinity라고 한다.
이를 해결하기 위해서는 poisoned reverse라는 기법을 사용하는데, link cost가 변했을 때 해당 link에 대한 정보를 INF로 설정해 보내는 것이다.
- 위 예시에서는 Y가 Y-X를 INF로 설정해서 보낸다.
- Z는 갱신하는데, Y-X가 INF이므로 이를 보고 Z-X를 50으로 갱신하고, Y에게 발송한다.
- Y는 Z-X가 50이라는 이 정보를 받고 Y-X를 51로 갱신한다.
그러나 이는 근본적인 해결 방법이 아니다. 위 예시에서는 cycle에 있는 vertex가 2개였기 때문에 해결되었지만 cycle에 있는 vertex가 3개 이상이라면 문제가 생긴다.
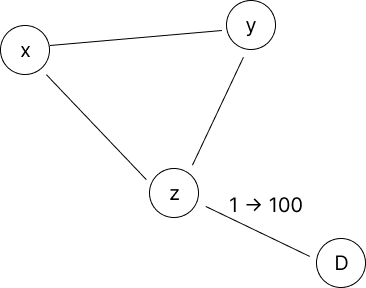
위 예시를 보자. Z-D link cost가 변한 상황이다. 이 때 Z는 X에게 Z-D cost를 INF로 설정해 보내지만 X가 X-Y-Z-D 순서로 path 계산해 버리면 똑같이 count to infinity 문제가 발생한다.
때문에, path vector routing이라는 기법을 써서 해결해야만 한다. path가 자기 자신을 거치는지 모르는 것이 근본적인 문제이기 때문에, 이를 해결하기 위해 path를 계산할 때 경로도 같이 저장한다. 단, 이 경우는 route에 대한 path를 모두 저장해야 하므로 overhead도 크고, routing protocol에서 data를 교환할 때도 overhead가 크다.
Link State vs Distance Vector
총 3가지 측면에서 비교해 볼 수 있다.
- message 복잡성
- link state의 경우 O(N*E)만큼의 message 교환이 필요하다.
- distance vector의 경우 neighbor에 대한 정보만 변경하면 되므로 O(N)만큼의 message 교환이 필요하다.
- convergence 속도 : router들이 consistent해지는 속도
- link state의 경우, dijkstra의 시간복잡도인 O(nlogn)만큼이 걸린다.
- distance vector의 경우 count to infinity 등의 routing loop로 인해 오래 걸린다.
- robustness : router가 고장났을 경우
- link state의 경우 dijkstra이므로 문제난 router 주변에만 문제가 발생한다.
- distance vector의 경우, distance vector가 계속 갱신되므로 전체의 distance vector가 잘못된다.
Route Oscillation
dynamic routing algorithm의 경우 cost가 계속 변하기 때문에 routing algorithm이 여러번 수행된다. 이 경우 route가 계속 바뀌게 되는데, 이를 route oscillation이라 한다.
route oscillation이 발생하면 TCP packet 도착 순서가 맞지 않아 application layer에서 문제가 생길 수도 있고, packet의 TTL이 초과되어 packet loss가 발생할 수 있다는 문제점이 있다.
Hierarchical Routing
위에서 본 routing algorithm들은 network를 flat하게 보았다. 이 경우 link state이든 distance vector든 network가 너무 커지면 계산 시간과 저장할 공간이 부족하며, routing table 크기도 너무 커지게 된다. 또, 실제 network는 provider가 다르기 때문에 서로 정보를 다 공개하지 않으려 한다.
이러한 문제 때문에 실제로는 link state나 distance vector 하나만 사용하는 것이 아니라, hierarchy를 만들어 사용한다.
hierarchical routing은 network를 autonomous system으로 나누어 사용하는 방식이다. 이 때 autonomous system은 하나의 provider가 관리하는 router set이다.
때문에 autonomous system 내부에서는 intra AS routing (앞에서 살펴본 link state나 distance vector)을 사용하고, autonomous system끼리는 inter AS routing을 사용한다.
autonomous system끼리는 각 autonomous system의 edge에 있는 gateway router끼리 연결하는 방식으로 연결한다.
forwarding table을 계산하는 방법 또한 2가지로 나뉜다.
- subnet prefix가 autonomous system 내부에 있는 subnet의 경우 : intra AS routing algorithm을 사용한다.
- subnet prefix가 autonomous system 바깥에 있는 subnet의 경우 : inter AS routing algorithm와 intra AS routing algorithm을 혼합해 사용한다.
Inter AS Task
각 autonomous system들은 아래 2가지를 행한다.
- inter AS routing protocol을 사용해 autonomous system의 gateway들끼리 통신하고, 서로의 reachable subnet을 공유한다.
- reachable subnet을 autonomous system의 내부에 알린다. (propagation)
예시
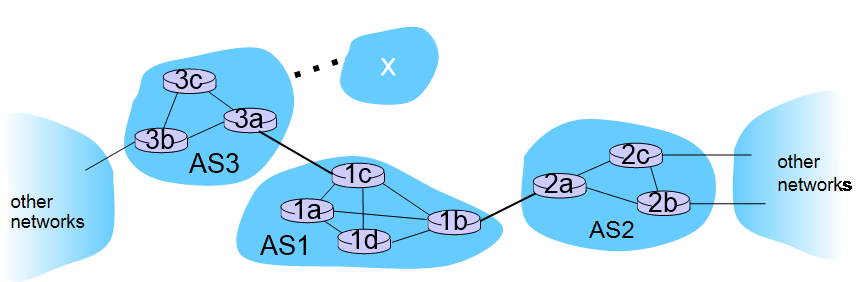
위 예시에서 AS1은 AS2, AS3와 gateway로 연결되어 있으므로 AS2, AS3가 어느 subnet에 reachable한지 알아야 한다. 각 AS의 gateway들이 inter AS routing procol로 서로의 reachable subnet을 공유한다.
이후 AS1의 gateway router가 AS1의 모든 router들에게 이 정보를 알린다.
이 때, AS 3가 subnet x와 연결되어 있고 1d가 subnet x로 packet을 보내고 싶다고 하자.
- 3a가 1c에게 subnet x에 reachable하다고 알려준다.
- 1c가 AS1 전체의 router에게 x에 reachable하다고 알린다.
- 1d가 inter AS routing algorithm으로 1c에게 가는 route를 파악 후, 1c에게 packet을 보낸다.
- 이를 통해 1d는 x로 가기 위한 forwarding table을 만들 수 있다.
- 1d에서 1c로 가기 위한 forwarding table은 intra AS routing protocol을 사용해 이미 least cost path가 적용된 entry가 들어간 상태이다.
Hot Potato Routing
바로 위에서 외부 autonomous system을 거쳐 destination subnet에 어떻게 도착하는지 알아봤다. 이 때, destination subnet에 도착하는 외부 autonomous system을 거치는 path가 2개 이상일 때는 hot potato routing을 사용한다. hot potato routing도 inter AS routing에 포함된 동작이다!
외부 autonomous system으로 가기 위해서 같은 autonomous system 안에 있는 gateway router에 packet을 보내야 하는데, 이 gateway router가 2개 이상인 경우, least cost path에 해당하는 gateway router로 packet을 보내는 방식이 hot potato routing이다.
least cost path를 선택한다는 말은, 다른 autonomous system에서 cost는 신경쓰지 않고 자신의 resource만 신경쓰는 방식이다. 왜냐하면 이 방식이 해당 provider에게 이득이 되기 때문이다.
예시
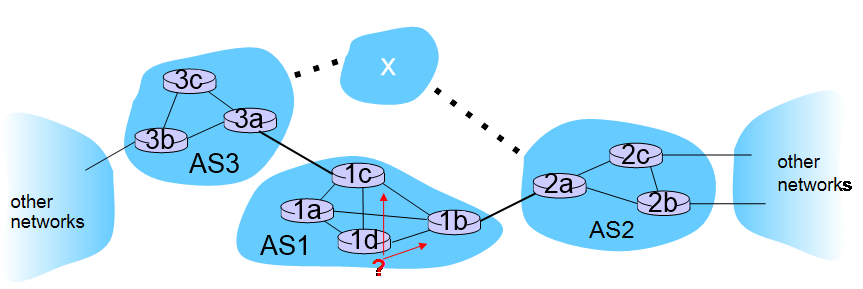
위 그림에서 destination subnet x에 도착하고 싶다고 하자. 이 때 AS3, AS2 모두 x에 연결되어 있으므로 다음 과정을 거쳐 x에 도착하기 위한 forward table entry를 채운다.
- 3a가 1c에게 subnet x에 reachable하다고 알린다. 2a가 1b에게 subnet x에 reachable하다고 알린다.
- 1c, 2a가 AS1 전체의 router에게 propagation(subnet x에 reachable)한다.
- inter AS routing protocol로 [1d-1c], [1d-1b]의 path, cost는 구할 수 있다. hot potato routing 방식인, 둘 중 least cost path에 해당하는 path로 forward table에 등록한다.
이렇듯 destination subnet이 autonomous system 외부에 있는 경우, inter AS routing protocol과 intra AS routing protocol을 같이 사용한다.
잘못된 내용이나 오탈자에 대한 지적, 질문 등은 언제나 환영합니다.