![[Network] 하향식 접근 네트워크 - 4. Network Layer - (3) Internet Protocol](https://img1.daumcdn.net/thumb/R750x0/?scode=mtistory2&fname=https%3A%2F%2Fblog.kakaocdn.net%2Fdn%2FbU7Xqb%2FbtsplpWfTwD%2F8HsUWKm0pgP80XtakOg1OK%2Fimg.png)
이 글은 이화여자대학교 이미정 교수님의 2014년 2학기 컴퓨터 네트워크 강의를 기반으로 재구성한 것입니다. 삽화는 링크를 출처로, 저작권은 J.F Kurose and K.W. Ross에게 있다는 것을 밝힙니다.
network layer에서는 다음과 같은 내용들을 살펴본다.
- network layer principles
- virtual circuit, datagram network
- router의 내부
- IP
- datagram format
- IPv4 addressing
- ICMP
- IPv6
- routing algorithm
- link state
- distance vector
- hierarchical routing
- routing in the internet
- RIP
- OSPF
- BGP
- broadcast, multicast
IP, Internet Protocol
IP protocol은 크게 3가지 부분으로 나뉜다.
- IP : data 전송에 관련된 내용을 정의한다. (addressing convention, datagram format, packet handling convention)
- routing protocol : 경로 계산에 사용하는 정보를 주고받고, 결과를 forwarding table에 저장한다.
- ICMP : data 교환에 사용하는 protocol이 아니라 error나 signalling에 사용하는 protocol이다.
IP Datagram Format
IP header

- ver : IP protocol version을 기입한다. 현재는 IPv4를 사용한다.
- header length : header는 fixed size로 20 byte, 추가로 dynamic size가 있기 때문에 header length를 기입해야 한다.
- type of service : data가 포함하는 service type을 넣는 곳이지만, 현재는 사용하지 않는다.
- length : 전체 datagram의 길이를 의미한다. head length와 같이 사용해 payload가 어디서부터 시작하고 어디까지인지 특정할 수 있다.
- 16-bit identifier, flag, fragment offset : 바로 다음에 나오는 fragmentation에서 설명한다.
- time to live : packet이 몇 개의 router를 거칠 수 있는지에 대한 count이다. 하나의 router를 거칠 때마다 1 감소시키며, 0이면 버린다.
- upper layer : 어느 process에게 줄지 선택해야 하기 때문에 필요하며, transport layer가 TDP인지 UDP인지 정보이다.
- source/destination IP address : delivery를 위해 사용하는 정보이다.
- options : 필요 시 사용하며, 예시로 각 router가 자신의 IP address를 기록해 path를 확인하거나 timestamp를 사용해 언제 지나갔는지 등을 표기할 수 있다.
Fragmentation & Reassembly
network의 모든 link는 한 번에 보낼 수 있는 size인 MTU(Maximum Transfer Unit)이 정해져 있다. 만약 datagram size가 MTU면 여러 개로 쪼개어 보내야 하는데, 이를 fragmentation이라 한다.
fragmentation을 하면 header의 16-bit identifer로 fragmentation한 packet들을 식별하고, 마지막 packet의 flag를 1로 설정해 마지막 packet임을 식별할 수 있게 한다. offset은 data length / 8을 해서 몇 번째부터 시작하는 fragment인지 판별한다.
- fragmentation 결과로 생긴 packet들은 모두 독립적으로 처리하고, 각각을 destination host까지 보낸다.
reassemble은 destination host에 도착한 fragment들을 합치는 것을 말한다. 각각의 packet들은 모두 독립적으로 운송되며, destination host에서 받아 합친다.
internet은 복잡한 것을 전부 다 edge로 빼기 때문에, end system에서 합친다.
예시

위 예시는 MTU가 1500 byte인 상황에서 length가 4000인 datagram을 fragmentation하는 상황을 보여준다.
IP header가 20byte이므로, 각 packet payload는 1480byte까지 들어갈 수 있다. 때문에 가운데 packet offset이 1480/8 = 185, 마지막 packet offset을 370으로 설정한다.
또, frag ID는 모두 동일하게 설정해 같은 fragment를 식별하고, 마지막 packet의 fragflag만 0으로 설정해 마지막 packet임을 식별한다.
IPv4 Addressing
IP address
IP address는 host와 router에 있는 network interface의 ID로, 32bit 숫자이다. 표기할 때는 8bit씩 4개로 나누고 각 숫자를 .으로 구분한다.
interface는 host/router와 physical link 사이의 connection을 의미한다.
일반적으로 router는 여러 개의 interface를 가지고, host는 1-2개의 interface를 가진다.
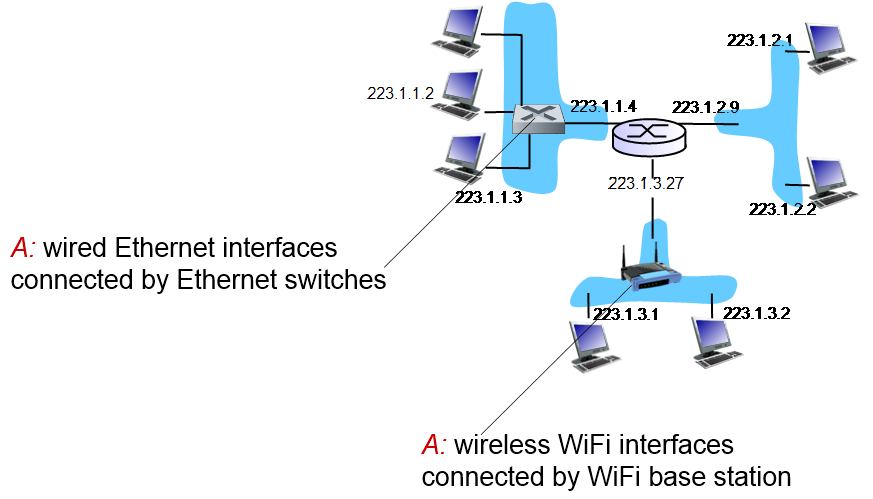
ethernet switch나 WiFi access point들은 link layer까지만 있기 때문에 IP address가 할당되어 있지 않다. 때문에, 실제 end system들은 ethernet switch나 WiFi access point를 거쳐 router에 연결되지만, 이 장에서는 이들이 없다는 가정 하에 설명한다.
Subnet
subnet은 router 없이 통신할 수 있는, 서로 연결되어 있는 device interface들의 집합을 말한다.
IP address는 subnet part와 host part로 나뉘는데, subnet part로 subnet을 식별하고 host part로 subnet에 있는 host를 식별한다.


연결되어 있는 network에서 router를 삭제하면 고립된 subgraph가 나오는데, 이 각각을 subnet으로 보면 된다. 왼쪽 예시에서는 router를 지우면 3개의 subnet이 생기고, 오른쪽 예시에서는 router를 지우면 총 6개의 subgraph가 생긴다.
IP Addressing : CIDR
CIDR는 Classless InterDomain Routing의 약자로, IP address 할당 방식 중 하나이다. subnet size를 IP address 뒤에 적어, subnet size를 필요한 만큼 할당하는 방식이기 때문에 효율적으로 IP address를 할당할 수 있다.
예시로, 223.1.3.0/24의 경우 총 32bit의 IP address 중 24bit를 subnet address로, 나머지를 host address로 표기하겠다는 것이다.
기존 방식은 IP address의 class를 3개로 나누어 subnet이 차지하는 bit를 정해둔 방식이었다. class A는 subnet이 8bit, class B는 16 bit, class C는 24 bit였다. 따라서 class A는 host 개수가 2$^{16}$, class B는 2$^{12}$, 2$^{8}$이었다. 이 경우 host를 사용하지 않는 IP address가 많아 많이 낭비되었다. 또한 internet이 성장함에 따라 IP address가 많이 부족해지게 되어 CIDR이 고안되었다.
IP Addressing : Host
host는 어떻게 IP를 할당받을까? 크게 2가지 방식이 있다.
- IP address를 system file에 하드코드하는 방식
- DHCP, Dynamic Host Configuration Protocol을 사용하는 방식 : DHCP는 application layer에 있는 protocol로, network에 연결할 때마다 IP address를 할당받는다.
DHCP, Dynamic Host Configuration Protocol
DHCP는 host가 network에 join할 때 IP address를 할당하고, leave하면 그 IP address를 free한다. 때문에 IP address를 재사용할 수 있어 효율적이다.
DHCP에서 사용하는 message는 크게 4가지가 있다. discover, offer의 경우 optional이다.
- DHCP discover : host가 DHCP server를 찾기 위해 subnet에 broadcast하는 message
- DHCP offer : DHCP가 자신을 알리면서, 동시에 쓸 수 있는 IP address를 알리는 message
- DHCP request : host가 IP address를 사용하겠다고 알리는 message
- DHCP ack : request에 대한 수신 확인 message
DHCP 과정
DHCP는 application layer protocol에 있기 때문에 host가 subnet에 연결하면, DHCP client program이 알아서 실행하고 message를 만든다. (applicatoin layer에서 message를 만들고 UDP로 server에 전송하고, 응답받는다.)

- discover
- src는 0.0.0.0을 사용하는데, 아직 IP address를 모르기 때문에 쓴다.
- destination은 255.255.255.255를 쓰는데, 이는 subnet에 broadcast하는 것을 의미한다.
- yiaddr : client를 위해 할당하는 IP address인데, 이 단계에서는 아직 IP address를 할당받지 못했기 때문에 0.0.0.0이다.
- transaction ID : 이 ID를 사용해 message의 request, response pair를 맞춘다.
- offer
- yiaddr에 client를 위해 IP address를 할당하고 이를 알린다.
- request
- yiaddr에 있는 값을 사용하겠다고 보낸다.
- ack
- request에 대한 수신 확인을 보내면서, 연결을 확정짓는다.
DHCP가 알리는 정보들
DHCP는 사용할 수 있는 IP address 뿐만 아니라, network에 연결하기 위한 추가적인 정보들을 더 준다.
- first hop router address : end system network layer는 router network layer보다 기능이 약하기 때문에 end system의 모든 packet은 subnet에 있는 first hop router로 packet을 전송해야 한다. 때문에 해당 router의 address를 알려줘야 한다.
- local DNS server IP address : domain name의 IP address를 얻기 위해 필요하다.
- network mask
IP Addressing : Subnet
DHCP를 사용해 host가 IP address를 할당받는 과정을 살펴봤다. 그러면 subnet는 어떨까?
subnet은 ISP로부터 address space를 할당받는다.

위 예시를 보자. ISP가 가지고 있는 address space는 200.23.16.0/20이다. 만약 8개로 나눈다고 하면, netmask에 3개의 bit를 더 사용해서 총 8개의 subnet을 만들 수 있고, 이를 subnet에 핼당한다.
Route Aggregation
forwarding table을 만들기 위해서는 모든 router들이 IP address를 알고 있어야 한다. 그러나 range of addresses를 설명할 때 말했듯 모든 IP address를 router에 넣을 수는 없다. 때문에 IP address hierarchy를 만든다.
그리고 각 ISP들은 특정 IP address로 시작하는 요청들을 자신에게 보내라는 advertise를 한다. 이 때 어떤 subnet이 ISP를 변경하면 어떻게 될까? 자신이 가지고 있는 모든 IP address를 변경해야 할까? 아니다. 바꾼 ISP가 해당 subnet의 IP를 추가로 advertise하면 된다. 때문에, routing table에서 IP address로 목적지를 찾아갈 때는 netmask가 더 긴 것을 우선적으로 선택한다. (바로 아래의 longest prefix matching에서도 설명한다.)


위쪽 그림에서, ISP A는 IP address가 200.16.16.0/20로 시작하면 A에게, ISP B는 IP address가 199.31.0.0/16로 시작하면 B에게 오라는 advertise를 한다.
이 때, organization 1이 ISP를 1에서 2로 바꿨다고 하자. organization 1은 자신이 가지고 있는 모든 network 기기들의 IP address를 변경할 필요가 없다. organization 1의 IP address를 ISP가 추가적으로 알리기만 하면 되기 때문이다. 위 예시에서는 ISP B는 IP address가 199.31.0.0/16으로 시작하거나, 200.23.18.0/23으로 시작하면 자신에게 packet을 보내라고 advertise하게 된다.
Longest Prefix Matching
internet의 IP address matching은 longest prefix matching으로 진행한다. 무슨 말이냐? routing table의 IP address를 비교할 때, 일치하는 부분이 더 긴 쪽으로 packet을 보낸다는 뜻이다.
1%의 네트워크 - 3. Cable, Hub, Router 포스팅의 routing 동작 부분에서 다음과 같이 설명했다. 이에 대한 자세한 설명이다.
router는 IP header의 값을 routing table에 대조하고 어디로 보낼지 판단한다.
- 수신처 항목의 netmask를 이용해 network 번호만 비교한다.
- 여러개가 찾아지면 network 번호 수가 가장 긴 것을 찾는다. network 번호가 크다는 것은 host 번호가 작다는 것이고, 즉슨 subnet이 좀 더 작은 것이기 때문에 좀 더 적은 경우의 수로 접근할 수 있기 때문이다.
IP Addressing : ISP
앞서, subnet은 ISP로부터 address space를 할당받는다고 했다. 그러면 ISP는 누구로부터 address space를 할당받을까? 바로 ICANN, Internet Corporation for Assigned로부터 할당받는다. 한국의 경우, 한국인터넷정보센터에서 할당한다.
이 기관은 단순히 IP address를 할당하는 것 뿐만 아니라 address 할당, DNS 관리, domain name 소유권 분쟁 중재 등도 맡는다.
NAT : Network Address Translation
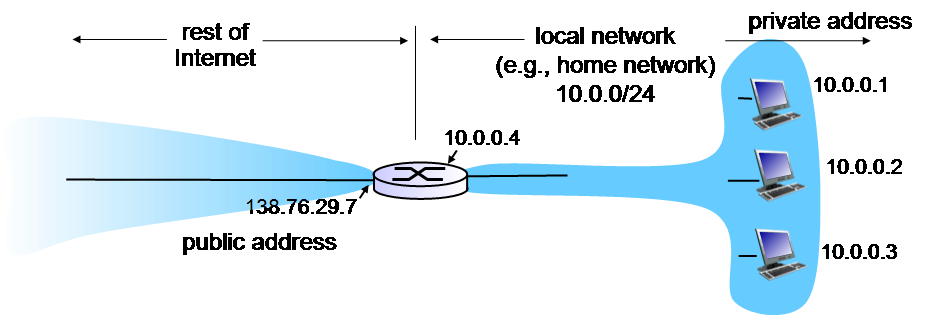
NAT는 IP address를 효율적으로 사용하기 위해 고안된 방법으로, subnet 전체가 하나의 IP address를 사용하는 방식이다.
local subnet에서 임의의 prefix와 netmask를 사용해 subnet의 모든 end system에 IP address를 할당하며, 이 IP address를 private IP address라고 한다. (인터넷 쪽으로 연결된) NAT를 수행하는 router는 하나의 IP address가 할당되어 있는데 이 IP address를 public, 또는 global IP address라고 한다. NAT를 수행하는 router는 public address와 private address를 변환한다.
1%의 네트워크 - 3. Cable, Hub, Router 포스팅에서 [router의 부가 기능 - 주소 변환]에 대해 설명했는데, 이와 동일한 내용이다.
NAT의 구현
subnet에서 internet으로 나가는 모든 packet은 NAT router를 경유하는데, 이 때 다음과 같은 일을 수행한다.
- outgoing datagram : [source IP address (private IP address), source port]를 [global IP address, new port]로 변경하고 외부로 내보낸다. 이 때 port는 사용하지 않는 값을 임의로 할당한다.
- remember : 변경한 mapping을 translation table에 저장한다. translation table은 [source IP address (private IP address), source port]와 [global IP address, new port]의 mapping이 저장되어 있다.
- incoming datagram : subnet 외부에서는, 받은 packet이 NAT에서 발송한 것으로 인식하므로 NAT로 응답 packet을 보낸다. NAT는 해당 packet을 받으면 translation table을 보고, 해당하는 private IP address로 변경한 후 해당 기기로 packet을 전송한다.
예시

global address가 138.76.29.7일 때, 10.0.0.1이 128.119.40.186:80으로 packet을 전송할 때 NAT에서 무슨 일이 일어나는지 보자.
- subnet 내의 source는 10.0.0.1:3345, destination은 128.119.40.186:8이다.
- 이 packet이 NAT router에 도착하면 address translation이 일어난다. 사용하지 않는 port를 임의로 할당하고(여기선 5001), sender IP address를 global address로 변경한다. 추가적으로 translation table에도 이 mapping을 저장한다.
- server에 응답이 도착한다. server는 138.76.29.7:5001에서 packet을 보낸 것으로 간주하고 응답을 보낸다. 이 주소는 NAT router의 주소이기 때문에 packet이 NAT router에 도착한다.
- NAT router는 translation table을 살피고 private address와 port에 해당하는 host에게 packet을 전달한다.
NAT에서 Port를 사용하는 이유
port를 사용하지 않는 경우, 만약 2개의 client host가 같은 server에 접속한다고 생각하자. server로 도착은 잘 될 것이다. 이후 server가 응답을 보내면 NAT로 도착한다. 이 때, 어떤 client에게 packet을 전송해야 할까? 모른다!
이렇듯 IP address의 변경만으로는 sender host를 식별할 수 없기 때문에 port도 사용해야 한다. 이 때 하나의 public IP address에 사용하지 않는 port 개수만큼 private IP address를 할당할 수 있다. port는 2$^{16}$개이기 때문에 약 6만 정도의 크기를 가지는 subnet을 만들 수 있게 된다.
NAT의 장단점
- subnet 전체가 하나의 public address만 사용하면 되므로 효율적이다.
- subnet 내부에서 IP address의 변경이 자유롭다.
- ISP가 변경되어도 local network 내부에는 영향이 전혀 없기 때문에 관리하기 쉽다.
- local network 장치가 바깥에서 보이지 않기 때문에 보안 측면에서 이점이 있다.
- NAT subnet에 server가 있는 경우 별도의 조치를 취해야 한다. 바로 아래에 NAT traversal problem으로 후술한다.
NAT Traversal Problem
[NAT subnet과 internet]을 연결하기 위해서 translation table이 있어야 하는데, translation table은 outgoing datagram에 대해서만 값을 작성한다. 만약 NAT subnet에 client만 있는 경우에는 상관없이 address translation이 잘 일어난다.
그러나 NAT subnet에 server가 있는 경우는 어떻게 해야 할까? server는 client의 요청을 받기만 하기 때문에, server의 packet이 먼저 NAT를 나가는 일은 없으며, 따라서 translation table에도 값이 쓰이지 않는다. 즉, server는 외부에서 보이지 않기 때문에 외부의 client가 NAT subnet 내의 server에 접속할 수 없다.
이를 해결하기 위해 2가지 방법이 있다.
- server process를 수동으로 translation table에 직접 입력하는 방법
- UPnP를 사용하는 방법
UPnP, Univeral Plug and Play
UPnP는 server process를 translation table에 입력하는 과정을 자동화시키는 방법이다. NAT subnet 내의 server process가 생성되면 다음 과정을 거친다.
- UPnP로 public IP address를 배우고
- NAT router에게 server process의 IP address, port를 알려 translation mapping을 일정 시간동안 만들어 달라는 요청을 보낸다.
ICMP, Internet Control Message Protocol
ICMP는 host-host 연결, 또는 host-router 연결에서 error report나 echo(서로 살았나 식별) 등 network layer에서 제어 정보를 교환하기 위한 protocol이다.
ICMP는 [type, code, 문제가 된 IP datagram의 첫 8byte]를 담고 있다. ICMP type과 code ID
- type이 3인 경우 destination에 도착하지 못한 경우를 말한다. code에 따라 host unreachable인지, protocol unreachable인지, port unreachable인지 등 정보를 포함한다.
- type이 8인 경우 ping, 0인 경우 pong으로 서로 살아있는지 확인하기 위해 사용한다.
- type이 9나 10인 경우 route를 결정하기 위해 사용한다.
- type이 11인 경우 TTL expired를 의미한다.
- type이 12인 경우 IP header가 잘못된 경우를 의미한다.
이러한 ICMP는 network layer를 가지고 있는 router, 또는 host가 발송한다.

IP와 ICMP는 같은 network layer이지만, 실제로는 ICMP가 더 상위의 layer이다. 따라서, ICMP message는 IP에 의해 encapsulate되어 발송된다.
예시 : traceroute
traceroute는 source부터 destination까지 network 경로를 확인하는 명령어이다. ICMP를 이용해 구현되었으며, 로직은 아래와 같다.
- source host는 destination host로 가는 UDP segment set을 만든다. 이 때, port는 destination host가 사용하지 않는 값으로 설정하고, TTL을 1, 2, ... 이런 식으로 1씩 늘려가면서 계속 UDP segment를 보낸다.
- 그러면 i번째 router에서 TTL expired segment가 발생한 경우, i번째 router는 ICMP를 발송하고 packet을 버린다.
- ICMP message에는 router 이름, IP address 등이 기재되어 있으며, ICMP message를 수신한 source host는 destination까지 network path를 얻을 수 있다.
- 만약 TTL이 충분히 커쳐 destination host에 packet이 도착했다고 하자. 그러면 destination port unreachable ICMP message가 날라오고, 이를 수신한 source host는 명령을 중지한다.
IPv6
IPv6은 IPv4 방식의 IP address 부족 문제를 해결하기 위해 고안되으며, address를 32bit가 아니라 128bit로 사용한다.
특징으로는 아래 2가지가 있다.
- 40 byte fixed length header : header length가 fixed이면 software가 아닌 hardware가 파싱하고 처리할 수 있기 때문에 processing 과정을 단축할 수 있다.
- network 고안 초기에는 link bandwidth가 bottleneck이었다. 그러나 기술 발전으로 인해 link bandwidth보다는 packet process time이 bottleneck이 되었고, 이를 줄이기 위해 위와 같은 방식을 사용한다.
- no fragmentation : packet이 너무 크면 router가 drop하고 ICMPv6에 새로 정의된 "packet이 너무 큼" ICMP를 전송하는 방식이다.
- source host가 fragmentation해서 보내게 한다. 기존에는 router가 fragmentation & reassembly를 수행했는데 이 과정에서도 process time이 필요하다. 이를 줄이기 위해 fragmentation을 network edge로 빼는 (application layer가 수행하게 만드는) 방식이다.
IPv6 Header

IPv6에는 IPv4에서 필요없는 것들을 버리고, 꼭 필요한 것들만 모아 fixed header를 만들었다.
- optional header가 사라졌다. 만약 optional header가 필요한 경우, next header를 사용해 해당 header를 가리킨다. 그리고, 다음 header가 segment header라면 UDP header, 또는 TCP header를 가리키기 때문에 IPv4 header의 upper layer field는 삭제된다.
- service quality를 보장하기 위해 priority, flow level 2가지 header가 추가되었다. flow의 priority를 주기 위해 사용하는 field이다.
- checksum field가 삭제되었다. 기술 발전으로 인해 전송 과정에서 오류가 없다고 가정할 수 있게 되었기 때문에 router가 checksum을 수행할 필요가 없어졌다. checksum 삭제로 인해 router process time이 줄게 된다.
- ICMPv6 : ICMP의 IPv6 버전. 차세대 인터넷에서는 multicast가 많으리라 예상하고, mutlicast group을 관리하는 기능을 추가했다.
Tunneling
tunneling은 한 network에서 다른 network로 packet을 보내는 방법이다.
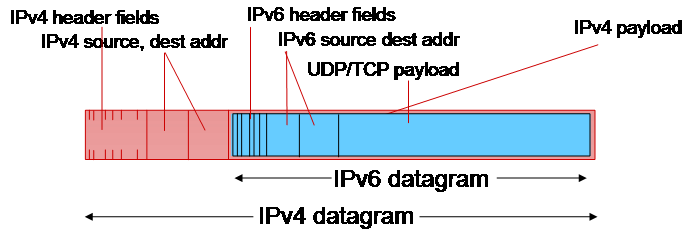
모든 IPv4 router를 IPv6으로 한 순간에 바꾸는 것은 매우 힘들다. 따라서 일부 router를 조금씩 IPv6으로 바꾸어 간다.
그러나 IPv4는 IPv6을 인식하지 못하는데, 이 경우 tunneling을 사용해 IPv4 datagram 안에 IPv6 datagram을 올린다. (IPv6을 payload로 보고 IPv4 방식으로 encapsulate) 그러면 IPv4 router가 해당 packet을 전송한다.
- 만약 IPv4 router가 해당 packet을 수신하면, 계속 IPv4로 전송한다.
- IPv6 router가 해당 packet을 수신하면, 해당 packet을 decapsulation했을 때 IPv6 packet임을 아므로, 다음 router가 IPv6인 경우 IPv6 방식으로 옮긴다.
예시
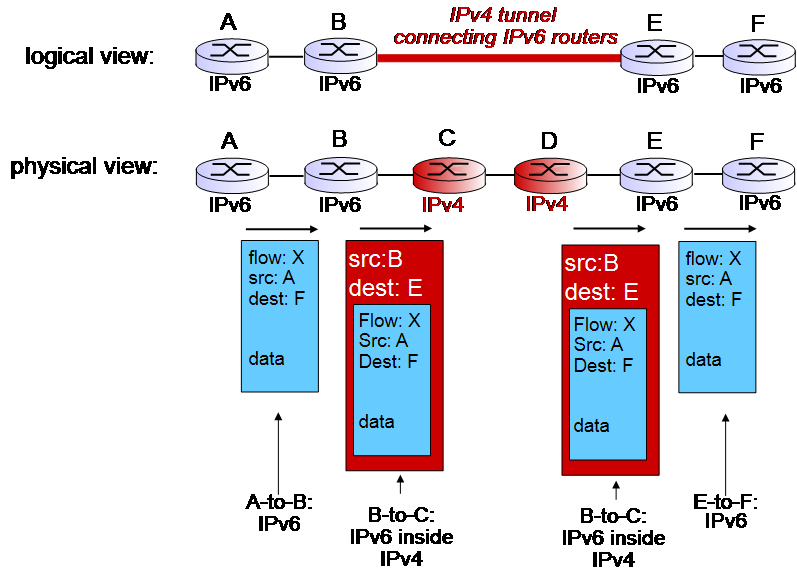
위 그림을 보자. IPv6 router는 다음 IPv6 router를 알고 있기에 B는 E에게 IPv6 packet을 전송해야 한다는 것을 안다. 그렇지만, 실제로는 B와 E 사이에 IPv4 router인 C, D가 설치되어 있다.
이 때 B는 E에게 IPv6 packet을 옮기기 위해 IPv4로 encapsulate한 후 C에게 전송한다. C는 D에게, D는 E에게 같은 방식으로 전송한다. 그러면 E가 IPv4 packet을 받는데, decapsulte하면 IPv6 packet임을 눈치챈다. 그러면 다음으로 이어진 IPv6 router에게 이를 전송한다.
이 방식이 tunneling이다.
잘못된 내용이나 오탈자에 대한 지적, 질문 등은 언제나 환영합니다.