![[Network] 하향식 접근 네트워크 - 4. Network Layer - (2) Router의 내부](https://img1.daumcdn.net/thumb/R750x0/?scode=mtistory2&fname=https%3A%2F%2Fblog.kakaocdn.net%2Fdn%2FbIVfpE%2Fbtspokzo30G%2FKrhE9ifUlYKcI6o25VHTjk%2Fimg.png)
이 글은 이화여자대학교 이미정 교수님의 2014년 2학기 컴퓨터 네트워크 강의를 기반으로 재구성한 것입니다. 삽화는 링크를 출처로, 저작권은 J.F Kurose and K.W. Ross에게 있다는 것을 밝힙니다.
network layer에서는 다음과 같은 내용들을 살펴본다.
- network layer principles
- virtual circuit, datagram network
- router의 내부
- IP
- datagram format
- IPv4 addressing
- ICMP
- IPv6
- routing algorithm
- link state
- distance vector
- hierarchical routing
- routing in the internet
- RIP
- OSPF
- BGP
- broadcast, multicast
Router
router의 핵심 기능은 routing과 forwarding이다.
- routing : 필요한 정보를 router끼리 교환하고, 이 정보를 바탕으로 routing algorithm을 실행하고 path를 저장한다.
- forwarding : packet이 들어오면 다음 router로 packet을 전달한다.
Router의 내부 구조
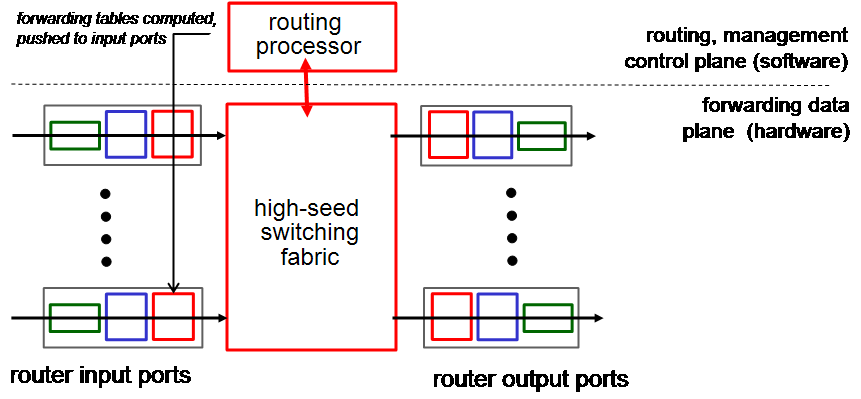
router의 내부는 크게 2가지로 구성되어 있다.
- control plane : routing message를 주고받으며, software가 구현한다. control plane은 forwarding table을 계산하고, 이 table을 input port로 push한다. 내부에는 routing protocol, algorithm을 수행하는 routing processor가 있다.
- data plane : user data를 주고받는다. 이 경우 빨리 전달되어야 하므로 hardware가 구현한다. 크게 input port, switching fabric, output port로 이루어진다.
Data Plane - Input Port
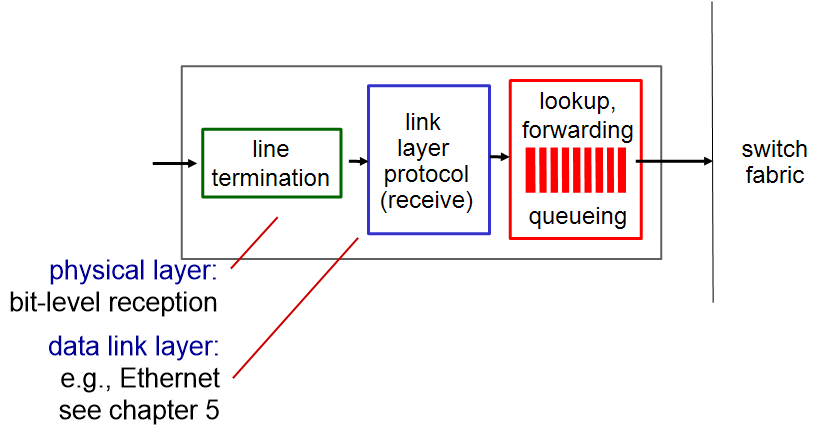
router의 input port는 위와 같이 3가지로 나뉘어 있으며, 하는 일은 다음과 같다. input port는 들어오는 속도와 나가는 속도를 같게 하는 것이 목표이다.
- physical layer, line termination : bit 신호를 받고 frame을 만든다.
- link layer : hop을 잘 건넜는지 확인한다.
- network layer, buffer queue : input이 들어오면 다음 hop으로 보내기 위한 output port를 찾는데, 이 과정을 forward table lookup이라고 한다. 이 때 input이 들어오는 속도가 switch fabric이 처리하는 속도보다 더 빠를 수 있다. 이러한 경우를 대비해 buffer로 queueing하는데 속도 차이가 큰 경우 queueing delay가 발생하며 심한 경우 loss가 발생할 수 있다.
Data Plane - Switching Fabric
switching fabric은 input port와 output port를 연결해 packet을 다음 hop으로 전달한다. 때문에 input port packet을 얼마나 빨리 output port로 전달할 수 있는지가 제일 중요한 요소이다.
switching fabric이 input port에서 output port로 packet을 전달하는 속도보다 input port로 들어오는 속도가 너무 심할 경우 input port buffer로 packet이 쌓이는데, 이 경우 queueing delay가 발생하고 더 심하면 packet loss가 일어난다.
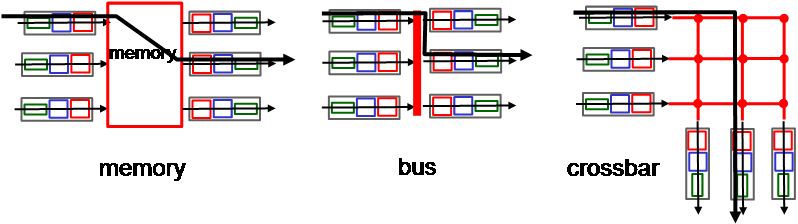
switching fabric은 3종류가 있다.
- memory : switching이 CPU의 제어 하에서 일어난다. input port packet이 memory로 복사하고 memory에 있는 값을 output port로 복사하는 방식이기에 system bus가 2번 일어나며, memory bandwidth에 의해 성능이 결정된다.
- bus : memory 방식의 단점인 2번의 system bus, memory에 의존하는 방식을 해결하기 위해 나온 방법이다. 모든 port가 shared bus를 하나 두고, 여기를 통해 input buffer에서 output buffer로 packet이 이동한다. 단, 1번에 1개의 packet만 bus에 접근할 수 있기 때문에 2개 이상의 input port가 동시에 접근할 때 bus contention이 일어난다. 때문에 switching speed가 bus bandwidth에 의존한다. Cisco 5600의 경우 32Gbps 속도가 나온다.
- crossbar (interconneciton network) : 이 방식은 multi processor를 연결할 때 사용하는 matrix 방식으로, bus 방식의 단점을 해결하기 위해 나타났다. Cisco 12000의 경우 60Gbps 속도가 나온다.
HOL blocking
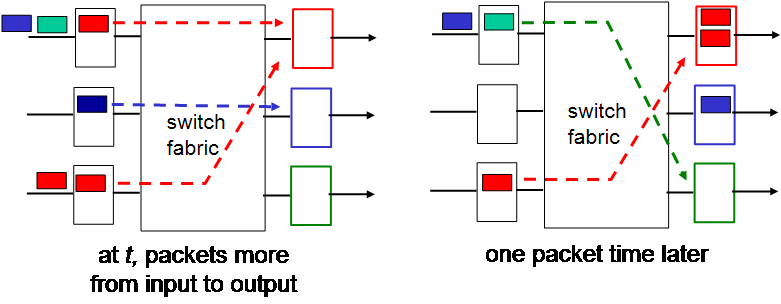
HOL blocking은 Head Of Line blocking의 약자로, input port queue의 front packet의 queueing delay 때문에 output port로 전달될 수 있는 packet이 나가지 못하는 경우를 의미한다. switching fabric에서 2개 이상의 packet이 동시에 동일한 port로 나갈 수 없기 때문에 발생하는 문제이다.
위 예시를 보자. 왼쪽 그림에서 빨간 packet이 빨간색 output port로 가고 싶어 한다. 그러나 2개 이상의 packet이 같은 port로 동시에 갈 수 없기 때문에 delay가 발생한다. 그러나 빨간색 input port를 보면, 초록색 packet은 바로 나갈 수 있다. 그러나 바로 앞에 있는 빨간 packet의 delay때문에 나가지 못하고 기다리고 있는데, 이 상황을 HOL blocking이라 한다.
Data Plane - Output Port
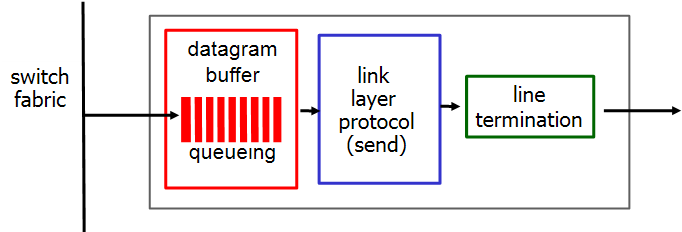
output port는 input port의 역순으로 되어 있다.
- network layer, buffer queue : input port에서 fabric switch에 들어가기 전에 대기했던 것처럼, output port에서도 bit 신호로 전송하기 전까지 대기한다. input port buffer와 동일하게 만약 bit 신호로 보내는 속도가 switching 속도보다 느린 경우 queueing delay, 심한 경우 loss가 발생한다.
- buffer에 있는 것들 중 어떤 것을 먼저 전송할지에 대한 scheduling이 있으며, internet의 경우 FIFO를 사용한다.
- link layer : 받은 buffer data로 frame을 생성한다.
- physical, line termination : frame을 bit 신호로 전송한다.
Buffer Size 결정
$\frac{\text{RTT} * \text{C}}{\sqrt{N}}$
buffer size는 queueing delay나 loss와 직결되기 때문에 buffer size는 잘 골라야 한다. 그렇지만 무작정 크게 설정하면 overhead가 많이 발생하기 때문에 적절한 값을 사용해야 한다.
C를 link capacity라고 할 때, TCP의 pipelining은 RTT와 C에 비례하기에 분모는 RTT * C로 둔다. N은 flow size로, 여러 packet이 동시에 발송되면 multiplexing이 일어나므로 전체 양은 줄어든다. 때문에 $\sqrt{N}$으로 나누며, 위 수식을 buffer size로 결정한다.
잘못된 내용이나 오탈자에 대한 지적, 질문 등은 언제나 환영합니다.