![[이종병렬컴퓨팅] Performance Considerations](https://img1.daumcdn.net/thumb/R750x0/?scode=mtistory2&fname=https%3A%2F%2Fblog.kakaocdn.net%2Fdn%2FbySXkp%2Fbtszk3uUekl%2Fn6UAlhSDY3L8khqIh4H1tk%2Fimg.png)
이 글은 포스텍 성효진 교수님의 이종병렬컴퓨팅(CSED490C) 강의를 기반으로 재구성한 것입니다.
이 글에서는 GPU resource의 제약과, 이들이 성능에 미치는 영향을 알아본다.
- 최적화 목표
- memory coalescing
- shared memory bank 충돌
- 점유율
- thread granularity
최적화 목표
Performance 고려 사항
parallel한 코드와 hardware resource의 제약, 이 두가지를 관리하는 것이 고성능의 핵심이다.
그러나 먼저, 어디서 제일 많은 시간이 걸리는지 측정해야 한다.
- Amdahl의 법칙을 생각해야 한다.
- coarse grained한 부분부터 측정하고, 이후에 fine grained한 부분을 측정하면 된다.
다음으로 main resource의 병목을 찾아야 한다.
- application마다 bottleneck이 다르다.
- 하나의 resource 사용량을 다른 것과 교환해서 성능을 올릴 수 있는지 고려해야 한다.
- compute-bound인지 memory-bound인지 고려해야 한다.
최적화 목표
최적화의 목표는 computing unit과 memory bandwidth를 최대로 사용하는 것이 목적이다.
computing unit을 최대로 사용하기 위해서는,
- Flops가 최대 연산량에 근접하게 처리해야 한다.
- 각 thread에서는 latency와 control divergence를 줄여야 한다.
- DRAM bandwidth 줄이기 : shared memory나 memory hierarchy를 사용해야 한다.
- memory coalescing : memory bandwidth를 더 효율적으로 사용해야 한다.
- shared memory bank collision 회피
- control divergence 회피
- thread끼리는 더 concurrent하게 만들어야 한다. 이는 occupancy이며, SM resource를 동적으로 분할하면 된다.
memory bandwidth를 최대로 사용하기 위해서는
- thread granularity : 각 thread는 더 independent하게 접근해야 한다.
- thread끼리는 더 concurrent하게 만들어야 한다. 이는 occupancy이다.
Memory Coalescing
DRAM Burst

DRAM burst는 memory에서 data를 읽거나 쓸 떄 한 번에 연속적인 data 묶음을 사용하는 방법이다.
기본적으로 off chip memory, DRAM은 chunk로 접근한다. 만약 하나의 byte에 접근하더라도, 그 byte가 속한 chunk에 있는 모든 byte를 읽어온다. 때문에 chunk 전체를 읽지 않으면 bandwidth가 낭비된다!
Memory Coalescing

모든 warp에서 memory operation이 발생하고, warp 내의 32개의 thread가 memory에 접근한다.
만약 모든 thread의 memory에 접근하는 위치가 연속적이고 하나의 burst section에 있는 경우 하나의 DRAM 요청만 발생하게 되므로, 모든 access가 coalescing(통합)된다.
위 그림에서는 T0, T1, T2, T3가 memory의 같은 burst에 접근하고 있다.

반면 memory에 접근하는 위치가 1개 이상의 burst인 경우, coalescing이 실패하므로 여러 개의 DRAM 요청이 만들어진다. 이렇게 받은 memory의 일부 정보는 thread에서 사용하지만, 몇몇 정보는 thread에서 사용하지 않기 때문에 bandwidth가 낭비된다.
위 그림에서는 T0, T1, T2, T3가 2개의 DRAM burst에 접근하고, 이마저도 100% 사용하는 것이 아니기 때문에 bandwidth가 낭비된다.
Coalesced Access
만약 array index가 다음과 같은 형식인 경우, warp의 memory access는 연속적이다.
`A[X + threadIdx.x]` 또는 `A[X + (blockDim.x*blockIdx.x + threadIdx.x)]`
(여기서 X는 X 이외의 항과 독립적이다.)
예시 : Output Tiling Matrix Multiplication
지지난 포스팅에서 살펴본 output tiling matrix multiplication을 보자.
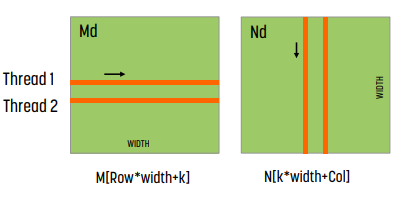
각 thread는 위 그림처럼 memory에 접근한다.
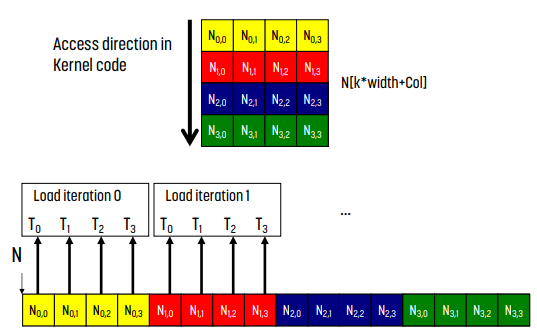
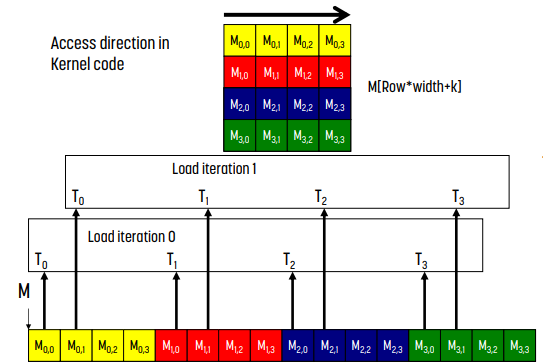
왼쪽 그림은 matrix N에, 오른쪽 그림은 matrix M에 해당하는 memory에 접근하는 방식이다.
그림에서 알 수 있듯 N의 경우 memory access가 coalescing되어 있다. 접근이 연속적이기 때문이다. 반면 M은 coalescing되어 있지 않다. 연속적인 memory에 접근하지 않기 때문이다.
예시 : Input Tiling Matrix Multiplication
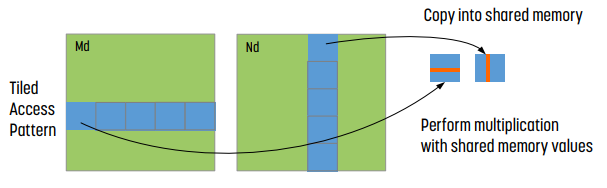
반면 tiling을 한 경우 memory coalescing이 일어난다. 연속된 memory를 shared memory로 읽어오기 때문이다!
예시 : strided access
__global__ void foo (int* input, float3* input2)
{
int i = blockDim.x * blockIdx.x + threadIdx.x;
// Stride 1
int a = input[i];
// Stride 2, half the bandwidth is wasted
int b = input[2*i];
// Stride 3, 2/3 of the bandwidth wasted
float c = input2[i].x;
}위 코드를 보자.
- stride 1의 경우 access pattern이 i이다.
- stride 2의 경우 access pattern이 2i이므로 bandwidth의 50%가 낭비된다.
- stride 3의 경우, input2는 float3이므로 bandwidth의 2/3이 낭비된다.
예시 : Structure의 Array와 Array의 Structure
C를 공부했다면 알만한 내용이다.
struct AoS
{
int key;
int value;
int flag;
};
AoS *d_AoS_data;
struct SoA
{
int * keys;
int * values;
int * flags;
};
SoA *d_SoA_data;
__global__ void bar(AoS *d_AoS_data, SoA *d_SoA_data)
{
int i = blockDim.x * blockIdx.x + threadIdx.x
// AoS wastes bandwidth
int key_aos = d_AoS_data[i].key;
// SoA efficient use of bandwidth
int key_soa = d_SoA_data->keys[i];
}이 경우 memory bandwidth는 어떨까?
물론 코드 짜기 나름이겠지만, 위 코드의 경우 array of structure는 bandwidth의 2/3을 낭비한다. structure of array는 100% 쓰고 있다.
요약
각 warp에서 100% address coalescing을 이루면 좋다.
이를 위해서 시작 주소를 정렬해서 쓰거나(padding이 필요할 수도 있다.), warp는 연속적인 memory에 access하는 것이 이상적이다. thread 사이에 큰 stride가 있거나, access 간격이 큰 것은 별로다.
이를 위해 address access pattern을 분석하고 최적화해야 한다.
- request당 memory transaction 회수 분석
- array of structure 대신 structure of array 사용
- read only data는 read only variable을 사용하는 것이 좋다.
- 가능하면 shared memory를 쓰는 것이 좋다.
Shared Memory Bank Conflict
shared memory는 thread block 내의 thread의 communication과 global memory access 회수를 줄이기 위해 사용한다.
이런 shared memory는 4byte로 이뤄진 32개의 bank로 이뤄져 있으며, 서로 다른 bank를 통해 연속적인 word에 접근할 수 있다. (bank level parallelism)
성능의 경우,
- shared memory access는 warp별로 만들어진다.
- 각 SM의 clock당, bank의 bandwidth는 4byte이다.
- serialization : N개의 thread가 하나의 bank 안에 있는 32개의 다른 word에 접근한다면, N개의 access는 순서대로 실행된다.
- mutlicast : N thread는 하나의 fetch로 같은 word에 접근할 수 있다.
각 bank는 모두 independent하다.
- optimal : 모든 thread가 다른 bank에 접근하는 경우 optimal하며, multicast할 수 있다.
- worst : 2개 이상의 thread가 같은 bank에 접근하는 경우 bank conflict가 발생한다. 이 경우 serialization이 발생하기 때문에 효율이 떨어진다.
Bank Conflict 회피
예시 : Matrix Transpose
__global__ transpose(float in[], float out[])
{
__shared__ float tile[TILE][TILE];
int glob_in = xIndex + yIndex*N;
int glob_out = xIndex + yIndex*N;
tile[threadIndx.y][threadIndx.x] = in[global_in];
__sync_threads();
out[glob_out] = tile[threadIdx.x][threadIndx.y];
}
위 코드를 실행시킬 때 shared memory에 32 by 32의 array가 있다고 하자.
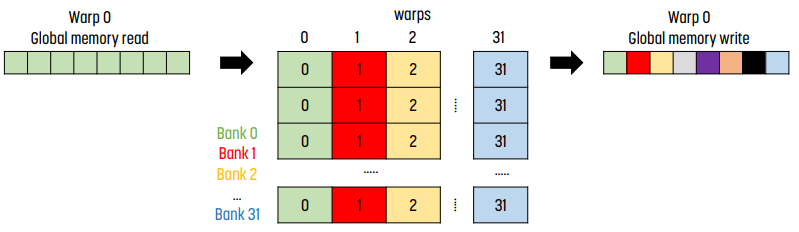
read에 대해서는 stride 1이기 때문에 coalescing이 발생한다. 때문에 가운데 그림처럼 bank 0에는 0번째 column이, bank 1에는 1번째 column이, ... 들어간다. 이 경우는 괜찮다! 모든 thread가 다른 bank에 접근하고 있다.
반면 bank에 값을 쓰는 상황을 보자. thread 0은 bank 0의 0번째에 값을 쓰고, thread 1은 bank 0의 1번째에, ... thread k는 bank 0의 k번째에 값을 쓴다.
이 경우 bank conflict가 일어나며 이 요청은 serialize되기에 성능이 대폭 떨어진다.
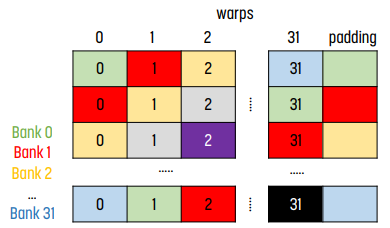
이를 막기 위해 사용하지 않는 column 하나를 덧붙이는 trick이 있다. 기존에 column 0에 해당하는 것은 모두 bank 0에 들어갔는데, 이렇게 바꾸면 column 0에 모든 종류의 bank가 들어가게 되어 bank conflict가 줄어든다.
Occupancy
Review : Thread Scheduling
SM은 overhead가 없는 warp scheduling을 했다. SM은 언제든 준비된 warp를 실행하고, 이 때 context swtiching cost가 없었다.
만약 모든 warp가 정지되어 실행할 warp가 없는 경우, 실행할 instruction이 없어 성능이 떨어진다.
그러면 왜 멈출까? 아래와 같은 이유가 있다. 두 경우 모두 active warp로 switch해서 latency를 숨겨야 하는데, 그러지 못하는 경우다.
- global memory access 대기
- compute unit를 대기
Occupancy
Occupancy = $\frac{\text{SM에서 활성화된 thread의 개수}}{\text{SM의 thread 개수}}$
Occupancy, 점유율의 정의는 위와 같다.
- occupancy가 높을수록 latency를 숨기는 데 도움이 된다. 당연하다! 실행할 수 있는 warp가 있기 때문에 그동안 idling하지 않는다.
- 달성된 occupancy vs 이론적 occupancy
- compute unit을 포화시키기 위해, 모든 SM을 채울 수 있는 충분한 thread block을 실행해야 한다.
- memory bandwidth를 포화시키기 위해 concurrent memory request를 가진 충분한 thread block을 실행해야 한다.
Occupancy와 성능
최대 성능을 위해 100% occupancy가 필요하지는 않다. 특정 occupancy에 도달하면, 더 늘려도 성능이 향상되지 않는다는 말이다.
이 [특정 occupancy]는 코드에 따라 다르다. 더 independen할수록 더 적은 occupancy가 필요하다. 일반적으로 memory에 의존하는 코드는 latency가 더 많기에 더 많은 occupancy가 필요한 경향이 있다.
Resource Limit
각 SM에서 각 thread는 register, shared memory를 공유한다. 또한 resource는 한계가 있기 때문에 hardware scheduler는 SM에 맞는 thread의 개수를 결정한다.
- thread당 register : SM register는 thread에 나눠진다.
- thread block당 shared memory : SM shared memory는 thrread block에 나눠진다.
- SM당 thread block : thread는 thread block granularity에 따라 나눠진다.
- SM당 thread
예시
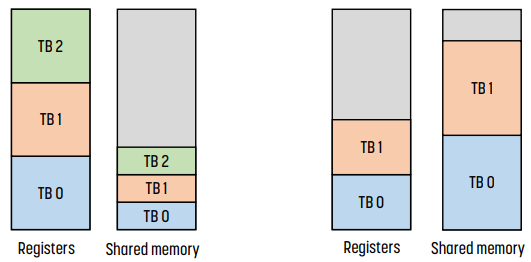
위 그림을 보자.
왼쪽의 경우, thread block 3개가 register와 shared memory를 나눠가진다.
반면 오른쪽의 경우 shared memory가 부족해 thread block 0, 1이 대부분의 shared memory를 점유하고 있다. 때문에 thread block 3가 활성화되지 못했다.
Thread Block Sizing
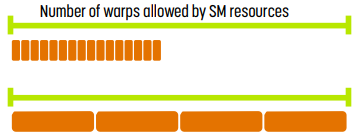

위 예시에서 볼 수 있듯 thread block의 개수와 thread의 개수는 thread block size과 관련이 있다.
- 위 그림의 왼쪽 부분. thread block이 너무 작으면 안 된다. SM이 occupancy의 임계점에 다다르기 전에 thread block의 한도에 다다르기 때문이다.
- 위 그림의 오른쪽 부분. thread block이 너무 커서도 안 된다. SM이 occupancy의 임계점에 다다르기 전에 thread 한도에 다다르기 때문이다. thread에 대해서는 resource가 충분하지만 thread block에 대해서 충분하지 않을 수도 있다.
Occupancy Guideline
- thread block 크기의 경우 (thread block당 thread의 개수)
- 각 thread block당 128 - 256개로 먼저 시작하고, 기능에 따라 조정하면 된다.
- warp size인 32에 배수인 것이 좋다.
- occupancy가 성능에 중요한 영향을 미치는 경우, thread block size가 register나 shared memory resource에 영향을 미치는지 확인해야 한다.
- grid size (grid당 thread block 개수)
- 1000개 이상의 thread block이 있는 것이 좋다.
Thread Granularity
thread가 얼마나 많은 일을 하게 둘지에 대한 지표이다.
일반적으로 independent한 thread가 더 많을수록 occupancy를 높일 수 있고, parallel하게 처리할 수 있다. 그러나 thread간 중복된 작업이 있는 경우 compute unit에서 thread가 정지될 수 있다.
- SM은 floating point, load나 branch instruction에 대해 제한된 bandwidth를 가지고 있다. 때문에 중복 작업을 없애는 것이 좋다.
예시 : Tiling Matrix Multiplication
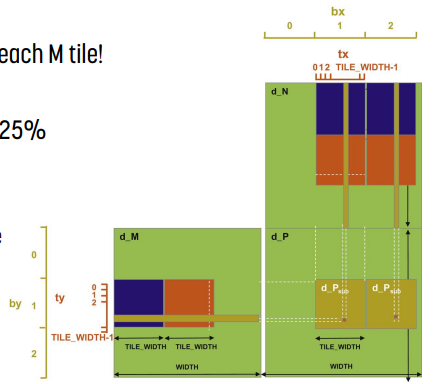
이 경우 각 M, N tile을 가져오는 데 중복이 있다. 이 경우 2개의 thread block을 하나로 합치면 global memory access를 줄 일 수 있다.
단, 이 경우 active thread의 개수가 줄어들어 SM resource에 대한 압박이 증가할 수 있고, 총 thread block의 개수가 줄어들어 parallelism에 문제가 생길 수도 있다.
요약
성능에 영향을 미치는 병목을 찾아내고 이를 해결해야 한다. 만약 병목을 찾아낸 경우, tuning을 적용해야 한다.
sequential code를 parallelize하는 방법도 고려해야 한다.
- kernel launch를 조절해 occupancy 높이기
- global memory access coalescing 을 사용해 memory bandwidth 효율 높이기
- shared memory & shared memory bank conflict 회피를 사용해 global memory에 대한 중복 접근을 없애기
- 같은 warp 내에서 다른 execution path를 줄여 control divergence 없애기
- stream, unified memory를 사용해 host - device data 전송 최소화 또는 숨기기
잘못된 내용이나 오탈자에 대한 지적, 질문 등은 언제나 환영합니다.
'CS > Parallel Computing' 카테고리의 다른 글
| [이종병렬컴퓨팅] Parallel Patterns : Histogram (0) | 2023.12.16 |
|---|---|
| [이종병렬컴퓨팅] Parallel Patterns : Convolution (0) | 2023.10.28 |
| [이종병렬컴퓨팅] Thread Execution Efficiency (0) | 2023.10.28 |
| [이종병렬컴퓨팅] Memory와 Data Locality - Tiled Multiplication & Unified Memory (0) | 2023.10.27 |
| [이종병렬컴퓨팅] CUDA Basics (0) | 2023.10.26 |