![[이종병렬컴퓨팅] Memory와 Data Locality - Tiled Multiplication & Unified Memory](https://img1.daumcdn.net/thumb/R750x0/?scode=mtistory2&fname=https%3A%2F%2Fblog.kakaocdn.net%2Fdn%2F8oqui%2Fbtsy8rKPhbI%2FEnZGqcDGCp9KasjsRMG6ZK%2Fimg.png)
이 글은 포스텍 성효진 교수님의 이종병렬컴퓨팅(CSED490C) 강의를 기반으로 재구성한 것입니다.
이 글에서는 다음과 같은 내용들을 살핀다.
- CUDA memory를 효율적으로 사용하는 방법
- memory access 효율이 performance에 미치는 영향
- 다양한 memory의 수명
- tiled parallel algorithm
- matrix multiplication - tiled multiplication kernel
- unified memory
Introduction
Matrix Multiplication
__global__ void MatrixMulKernel(float* M, float* N, float* P, int Width) {
// Calculate the row index of the P element and M
int Row = blockIdx.y*blockDim.y+threadIdx.y;
// Calculate the column index of P and N
int Col = blockIdx.x*blockDim.x+threadIdx.x;
if ((Row < Width) && (Col < Width)) {
float Pvalue = 0;
// each thread computes one element of the block sub-matrix
for (int k = 0; k < Width; ++k) {
Pvalue += M[Row*Width+k]*N[k*Width+Col];
}
P[Row*Width+Col] = Pvalue;
}
}M, N이 given, P가 output일 때, 지난 포스팅에서 배운 내용으로 matrix multiplication을 구현하면 위와 같을 것이다. if문 검사하는 부분은 matrix size가 input size의 배수가 아닐 수 있기 때문에 하는 검사 로직이다.

곱하는 부분을 그림으로 나타내면 위와 같다.
문제점: GPU의 성능
위 코드의 경우, 모든 thread가 global memory의 `input` matrix에 접근한다.
- floating point 곱셈과 덧셈 연산에서 2번의 memory access가 발생한다.
- 각 floating point operation Flops당 4byte의 memory bandwidth가 발생한다.
그러면 이 때 GPU가 600GB/s DRAM이고, GPU는 1.6TFlops - 초당 1.6T개의 floating point operation - 를 할 수 있다고 가정하자.
- GPU가 가지는 1.6TFlops를 모두 감당하기 위해서는 4 * 1.6 = 6.4TB/s의 bandwidth가 필요하다.
- 가정한 memory bandwidth는 600GB/s이므로, 150GFlops밖에 하지 못한다.
즉, floating point 연산 속도에 비해 memory bandwidth가 크게 못미치는 상황이다. 따라서, 1.6TFlops에 근접하기 위해서는 memory access를 줄여야 한다.
Cuda Memory Hierarchy
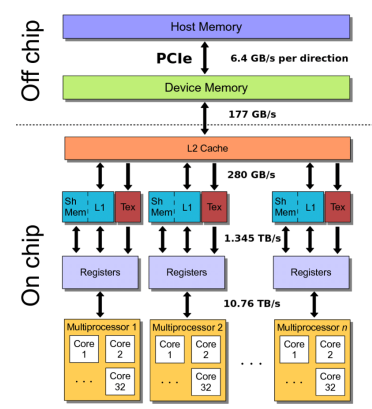
CUDA memory hierarchy는 위와 같다.
- 각 thread는
- thread별 register에 1-2 cycle만에 read/write할 수 있다.
- thread별 local memory에 약 500 cycle만에 read/write할 수 있다.
- block별 shared memory에 10 cycle만에 read/write할 수 있다.
- grid별 global memory에 500 cycle만에 read/write할 수 있다.
- grid별 constant memory나 texture memory에 100 cycle만에 read only할 수 있다.
CUDA의 Variable Type
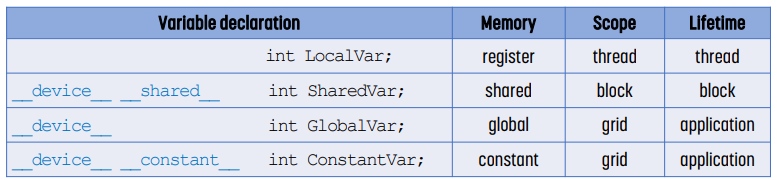
- LocalVar는 thread의 register에 저장되고, thread가 끝나면 사라진다.
- `__shared__`로 선언하는 SharedVar는 shared memory에 저장되고, thread block이 끝나면 사라진다. thread block당 하나가 생성된다.
- `__device__`로 선언하는 GlobalVar는 global memory에 저장되고, grid, 즉 application이 끝나면 사라진다.
- `__constant__`로 선언하는 ConstantVar는 constant memory에 저장되고, application이 끝나면 사라진다.
Variable의 선언 위치
- host가 접근해야 하는지 여부에 따라 variable을 어디에 선언하는지가 달라진다.
- True면 function 밖에 선언한다. `__constant__`나 `__device__`로 선언한다.
- False면 kernel 안에 선언한다. `LocalVar`나 `__shared__`로 선언한다.
Memory Type에 따른 전략
- read only : constant memory에 둔다. 이는 64KB 이하의 작은, thread가 공유하는 read only data인 경우 좋다. 빠르다.
- block 내부에서 공유하고, read/write하는 경우 : local memory 또는 shared memory에 둔다. 빠르다.
- 각 thread에서 read/write하는 경우 : thread register에 둔다. 빠르다.
- 각 thread 내부에서 indexed read/write하는 경우(array인 경우) : thread-local memory에 둔다. 느리다.
- 따라서 array를 쓰는 경우 global memory에 두고 shared memory로 가져오는 편이 좋다.
- input/result read/write : global memory에 둔다. 느리다.
GPU의 Shared Memory
kernel 코드에서 explicitly하게 정의되고 사용되는 특별한 memory이다. 즉 프로그래머가 직접 관리해야 하는 memory이다. L2 cache는 공개 cache이기 때문에 많은 thread가 모두 공유하는데, GPU의 경우 thread가 매우 많기 때문에 L2 cache에 caching되더라도 evict될 확률이 너무 높다. 따라서 L2 cache만을 사용해서 locality를 제공하는 것은 한계가 있다.
- 각 SM당 하나씩 있다.
- access 및 sharing의 범위는 thread block이다.
- lifetime은 thread block이다. 즉, thread block의 실행이 끝나면 내용이 사라진다.
- explicitly하게 memory load/store instruction을 호출해야 한다.
- scratchpad memory라고도 불린다.
- 직접 관리하는 cache라고 보면 된다.
Cache vs Shared Memory
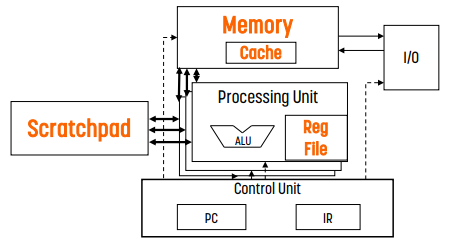
| cache | shared memory |
| hardware과 관리한다. | software가 관리한다. (별도의 address space를 사용하므로 cache 나 global memory와 공유하지 않는다.) |
| tag matching으로 인해 overhead가 있다. | 전력 소비량이 낮고, directly addressed이다. |
| implicit하게 data가 이동한다. | explicit하게 data가 이동한다. |
| replacement policy를 따르기 때문에 memory 낭비가 발생할 수 있다. | 작고 효율적이다. |
예시: Shared Memory의 필요성
// motivate shared variables with Adjacent Difference application
// compute result[i] = input[i] – input[i-1]
__global__ void adj_diff_naive(int *result, int *input) {
// compute this thread’s global index
unsigned int i = blockDim.x * blockIdx.x + threadIdx.x;
if (i > 0) {
// how many times does this kernel load input[i]?
int x_i = input[i]; // once by thread i
int x_i_minus_one = input[i-1]; // once by thread i+1
result[i] = x_i – x_i_minus_one;
}
}위 코드는 인접한 index의 차이를 result에 넣는 kernel function이다.
이 경우, input[i]는 thread i에 의해 한 번, thread i+1에 의해 또 한 번 불러진다. 그러나 input은 global memory에 있기 때문에 느리다! 따라서 이러한 중복된 global memory access를 줄이는 것이 shared memory의 목표이다.
Barrier Synchronization

`__syncthreads()` 함수를 사용해 한 thread block에 있는 모든 thread가 해당 barrier에 도착하면 모든 thread가 도착할 때까지 기다리게 할 수 있다.
Shared Memory의 사용법
static allocation과 dynamic allocation 2가지가 있는데, 둘 다 예시를 통해 살펴볼 것이다.
예시 : Shared Memory Fixed Allocation
// optimized version of adjacent difference
__global__ void adj_diff(int *result, int *input)
{
int tx = threadIdx.x; // shorthand for threadIdx.x
// allocate a __shared__ array, one element per thread
__shared__ int s_data[BLOCK_SIZE];
// each thread reads one element to s_data
unsigned int i = blockDim.x * blockIdx.x + tx;
s_data[tx] = input[i];
// avoid race condition: ensure all loads
// complete before continuing
__syncthreads(); // thread block 내의 모든 thread의 실행이 끝난 것을 보장한다. 즉, s_data에 모든 값이 잘 들어갔음을 보장한다.
if (tx > 0)
result[i] = s_data[tx] – s_data[tx–1];
else if (i > 0) // tx == 0 && i > 0
{
// handle thread block boundary
result[i] = s_data[tx] – input[i-1];
}
}
이 경우 fixed size allocation으로 shared memory를 사용하는 예시이다. fixed allocation인 만큼 BLOCK_SIZE로 s_data를 할당했으며, BLOCK_SIZE는 thread block size와 동일하다. (one element per thread이므로)
shared memory 부분에는 `s_data[tx] = input[i]`로 수행되었는데, s_data의 경우 tx로 indexing하고 input의 경우 i로 indexing했다. tx는 thread index이고, i는 전체에서 실행 중인 thread의 index이다. 이렇게 한 이유는, shared memory는 thread block 내에서 공유하기 때문에 s_data를 tx로 indexing하기 때문이다.
이후에는 `__syncthread()`를 호출하는데, 다음 단계로 진행하기 전에 barrier를 만들어 s_data에 모든 data가 들어갔는지 보장하기 위해 사용한다. 만약 `__syncthread()`가 없다면 data가 아직 들어오지 않았을 수 있기 때문에 다음 코드에서 문제가 생긴다.
이후의 if문에서는 shared data에 접근해서 값을 계산한다. 이 코드에서는 `result[i] = ...`와 같이 global memory에 값을 1번 쓰고 있는데, 오직 1번의 global memory write만 하므로 괜찮다. (문제가 되는 것은 여러 번 access할 때이므로)
else if문에서는 `result[i] = s_data[tx] - input[i-1];`의 방식으로, s_data는 shared memory에 접근하고 input은 global memory에 접근하는데, tx == 0인 경우는 해당 thread block의 shared memory에 저장되지 않은 input[i-1]의 값이 필요하다. 즉, 다른 thread block의 data를 필요로 하는 경우가 있기 때문에, 이 경우만 예외적으로 처리해 준다.
예시 : Shared Memory의 Dynamic Allocation
/ when the size of the array isn’t known at compile time...
__global__ void adj_diff(int *result, int *input)
{
// use extern to indicate a __shared__ array will be
// allocated dynamically at kernel launch time
extern __shared__ int s_data[];
...
}
// pass the size of the per-block array, in bytes, as the third
// argument to the triple chevrons
adj_diff<<<num_blocks, block_size, block_size * sizeof(int)>>>(r,i);dynamic allocation을 하기 위해서는 아래 2가지를 지켜야 한다.
- kernel의 ` __shared__` 앞에 `extern`을 붙여 써야 한다.
- kernel launch를 할 때 shared memory 크기를 지정해 줘야 한다.
- shared memory는 thread block에 할당되며, SM이 하나의 thread block을 실행한다. kernel launch에서 shared memory 크기를 알려 주고, 이를 통해 scheduler가 applicatoion 전체에서 필요한 공간을 계산한다.
예시 : Shared Memory에 여러 개의 Dynamic Array
extern __shared__ int s[];
int *integerData = s; // nI ints
float *floatData = (float*)&integerData[nI]; // nF floats
char *charData = (char*)&floatData[nF]; // nC chars
...
//kernel launch from host
myKernel<<<gridSize, blockSize,
nI*sizeof(int)+nF*sizeof(float)+nC*sizeof(char)>>>(...);만약 여러 개의 array를 사용하고 싶다면 위 코드와 같이 하나의 큰 array를 할당한 후, pointer를 사용해 나누어야 한다.
Tiling
Tiling이 없는 경우

앞서 살펴본 matrix multiplication은 같은 element에 중복해 접근하는 일이 많았고, 이 중복이 모두 global memory access였다. 각 thread는 M과 N을 width번 호출한다. 호출 위치가 global memory이기 때문에 상당히 느리다.
Tiling을 쓰는 경우

global memory를 tile을 기준으로 나누고, 각 thread 또한 tile에만 집중해서 계산하는 방식이다. 이 방법을 사용하면 global memory를 중복해 호출하는 회수를 줄일 수 있다.
이 구현은 L1 cache나 L2 cache를 사용해 caching effect를 극대화 할 수도 있고, shared memory(scratchpad)를 사용할 수도 있다.
Synchronization

단, 이 방식은 synchronization이 필요하다.
위 경우, 같은 element에 2개의 thread가 비슷한 시간대에 접근하고 있다. 반면, 아래 경우 같은 element에 2개의 thread가 매우 다른 시간대에 접근하고 있다. 아래 경우는 cache effect를 받지 못하고, 그만큼 on chip memory에 데이터를 계속 올려둬야 하기에 좋지 않은 모델이다.
따라서, thread들이 비슷한 시간에 access할 때 좋다.
요약
global memory access는 on chip memory보다 느리기 때문에 이 global memory access 대신 shared memory access를 사용한다.
- global memory content에 사용할 tile을 만든다.
- global memory에서 shared memory로 tile을 가져온다.
- thread는 shared memory에 access해서 계산한다.
- synchronization을 위해 barrier를 사용한다.
- (필요 시) shared memory에서 global memory로 계산 결과를 복사한다.
- 다음 tile로 이동한다.
Tiling : Matrix Multiplication
tiling의 종류에는 크게 2가지, input tiling과 output tiling이 있다.
output tiling은 output matrix를 tile 기준으로 나누고 thread block에 매핑하는 방식이다. 반면 input tiling은 input matrix를 tile 기준으로 나누는 방식이다.
Output Tiling

output tiling은 위 그림처럼 output matrix을 tile로 나누고, 이 tile을 thread block에 할당하는 방식이다. thread block을 output matrix에 매핑하는 것이다.
그러면 하나의 thread block은 하나의 output tile을 계산한다. 일반적으로 thread block을 tile과 동일한 크기로 잡으므로, thread block은 output matrix에서 하나의 element를 계산하게 된다. 그러면 각 thread는 M의 row와 tile에 해당하는 N의 column에 access한다. 위 그림에서는 Md, Nd로 표현되었다.
예제: Output Matrix를 Thread Block에 매핑

TILD_WIDTH * TILD_WIDTH 크기의 thread block을 선언한다. 그러면 각 thread block에는 TILD_WIDTH$^2$개의 thread가 들어가고, thread block은 총 $\frac{\text{WIDTH}}{\text{TILE_WIDTH}}^2$개가 존재한다.
위 예시는 WIDTH가 4, TILD_WIDTH가 2인 예시이다.
Memory Layout

이전 포스팅에서 다뤘듯 모든 n-D memory는 1D array로 평면화된다. 따라서 indexing을 해야 한다.
예를 들어 위 그림에서 M$_2, _1$에 접근하기 위해서는 2 * WIDTH + 1에 접근해야 한다.
코드
__global__ void MatrixMulKernel(float* M, float* N, float* P, int Width) {
// Calculate the row index of the P element and M
int Row = blockIdx.y*blockDim.y+threadIdx.y;
// Calculate the column index of P and N
int Col = blockIdx.x*blockDim.x+threadIdx.x
if ((Row < Width) && (Col < Width)) {
float Pvalue = 0;
// each thread computes one element of the block sub-matrix
for (int k = 0; k < Width; ++k) {
Pvalue += M[Row*Width+k]*N[k*Width+Col];
}
P[Row*Width+Col] = Pvalue;
}
}
void MatrixMulOnDevice(float* M, float* N, float* P, int Width) {
int size = Width * Width * sizeof(float);
cl_mem Md, Nd, Pd;
cudaMalloc((void**) &Md, size);
cudaMalloc((void**) &Nd, size);
cudaMalloc((void**) &Pd, size);
cudaMemCpy(Md, M, size, cudaMemcpyHostToDevice);
cudaMemCpy(Nd, N, size, cudaMemcpyHostToDevice);
cudaMemset(Pd, 0, size);
// kernel invocation code
...
// Read P from the device
cudaMemCpy(P, Pd, size, cudaMemcpyDeviceToHost);
// Free device matrices
cudaFree(Md);
cudaFree(Nd);
cudaFree(Pd);
}output tiling의 코드는 위와 같다.
- `MatrixMulOnDevice`에서 `cudaMalloc()`, `cudaMemcpy()`, `cudaMemset()`을 호출해 M, N, P를 초기화한다. 이후 `cudaMemcpy()`를 호출해 Pd를 P에 복사하고 있다.
- `MatrixMulKernel`은 M의 모든 row, N의 모든 column으로 output tile의 한 element에 들어갈 값들을 계산한다. 이게 한 thread에서 수행하는 일이고, TILE_WIDTH * TILE_WIDTH개의 thread... 즉 thread block이 `MatrixMulKernel`을 실행하면 하나의 output tile의 모든 element를 계산하게 된다.
Input Tiling
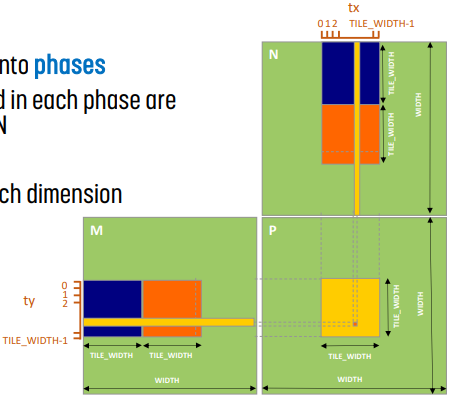
input tiling은 input을 tile로 나누는 방법이다.
output tiling에서는 M의 모든 row, N의 모든 column으로 P의 한 element를 계산했는데 여기서는 그 방법 대신 M의 tile, N의 tile을 사용한다.
input tiling에서는 각 thread의 실행을 phase로 나눈다. 그러면 각 phase에서 thread가 접근하는 data가 M의 tile 1개, N의 tile 1개에 집중된다. 위 그림에서는 처음에는 파란색 tile의 곱을 계산하고, 이후에는 주황색 tile의 곱을 계산한다.
물론 한 번의 tile의 곱으로 완벽한 결과를 내지 못한다. 모든 tile의 연산이 끝나야 올바른 결과가 나온다.
대신, 하나의 thread가 하나의 element의 결과를 연산하는 것이 아니라, shared memory에 올린 모든 data, 그러니까 tile에 해당하는 모든 data에 대해 연산한다. 따라서, 각 tile을 shared memory에 올리고 - 이것은 thread block의 모든 thread가 공유한다 - 각 thread는 shared memory를 참조하면서 결과를 계산한다는 것이 input tiling의 기본 골자이다.
예시
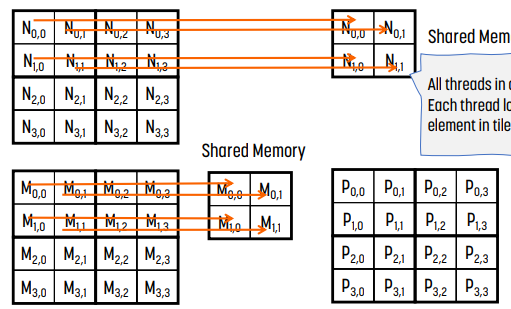
M의 tile 1개와 N의 tile 1개를 각각 shared memory에 넣는다. 그러면 각 thread block은 자신만의 tile을 가지게 된다.
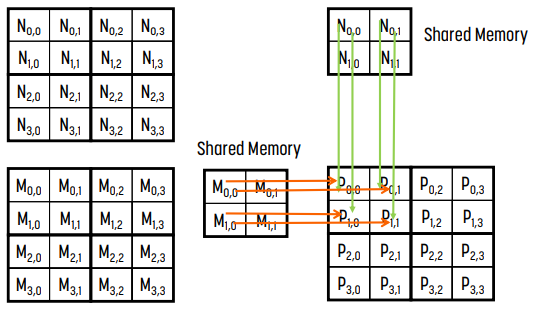
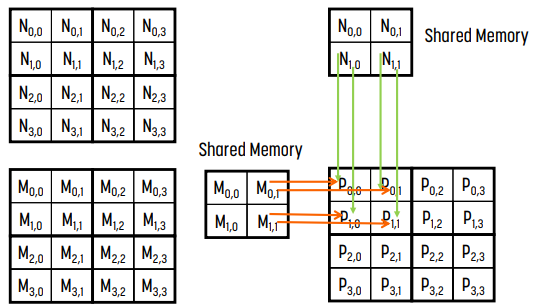
loading이 끝나면 shared memory에 로딩된 block (0, 0)을 사용해 계산한다. 여기서 계산의 결과값은 최종값이 아니다.
- 왼쪽 그림은 iteration 0으로 M의 column 0과 N의 row 0 - M$_0, _0$과 M$_1, _0$, N$_0, _0$과 N$_0, _1$ - 을 사용한다.
- 오른쪽 그림은 iteration 1로, M의 column 1과 N의 row 1 - M$_0, _1$과 M$_1, _1$, N$_1, _0$과 N$_1, _1$ - 을 사용한다.
- 그냥 단순히 matrix multiplication이다! (각 iteration은 ijk matrix multiplication에서 k를 의미한다고 생각하면 된다.)

block (0, 0)은 아직 계산이 덜 되었다. 이전에 계산한 tile 말고, 다른 M의 tile 1개와 N의 tile 1개를 shared memory에 넣는다.
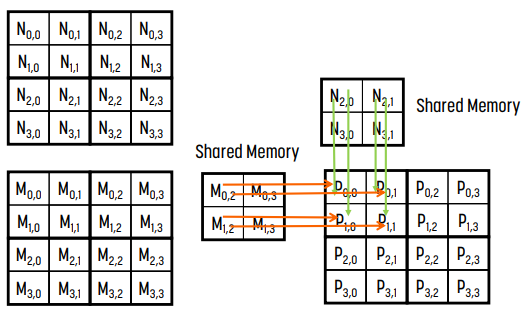
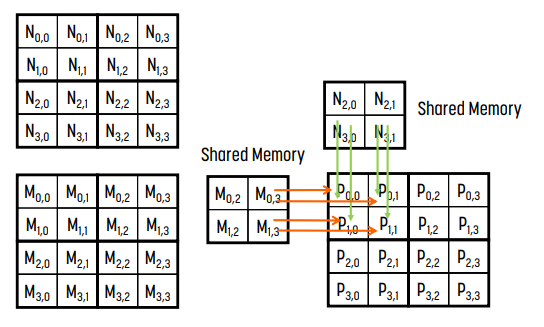
shared memory에 있는 값으로 block (0, 0)을 계산한다. 세부 내용은 위와 동일하다.
Indexing

- 2D의 경우
- M[row][m*TILE_WIDTH + tx]
- N[m*TILE_WIDTH+ty][col]
- 1D로 바꾸면
- M[row*WIDTH + m*TILE_WIDTH + tx]
- N[(m*TILE_WIDTH+ty)*WIDTH + col]
- 참고로 row = `blockIdx.y * blockDim.y + threadIdx.y`, `col = blockIdx.x * blockDim.x + threadIdx.x`이다.
여기서 m = for loop의 iteration index.
Boundary Check

1D에서 처리했던 것과 마찬가지로 WIDTH가 TILE_WIDTH의 배수가 아닐 수 있기 때문에 이에 관한 예외 처리를 해야 한다. 만약 하지 않는다면, 값을 넣지 않은 공간을 계산하기 때문에 결과가 달라질 수 있다.
이를 수행하는 방법은 아래와 같다.
- index를 계산하고, valid한지 검사한다. 구체적으로는, M의 row, column에 대해 / N의 row, column가 모두 Width보다 작은지 검사한다.
- 범위를 벗어나는 것에 대해서는 0을 둔다. 이는 결과에 영향을 미치지 않기 때문이다.
// Loop over the M and N tiles required to compute the P element
for (int p = 0; p < ((Width-1)/TILE_WIDTH)+1; ++p) {
__shared__ float ds_M[TILE_WIDTH][TILE_WIDTH];
__shared__ float ds_N[TILE_WIDTH][TILE_WIDTH];
int bx = blockIdx.x;
int by = blockIdx.y;
int tx = threadIdx.x;
int ty = threadIdx.y;
int Row = by * blockDim.y + ty;
int Col = bx * blockDim.x + tx;
float Pvalue = 0;
// Loop over the M and N tiles required to compute the P element.
for (int p = 0; p < ((Width-1)/TILE_WIDTH)+1; ++p) { // phase
// Collaborative loading of M and N tiles into shared memory
if (Row<Width && p*TILE_WIDTH+tx < Width) {
ds_M[ty][tx] = M[Row*Width + p*TILE_WIDTH+tx];
} else {
ds_M[ty][tx] = 0.0;
}
if (p*TILE_WIDTH+ty < Width && Col<Width) {
ds_N[ty][tx] = N[(p*TILE_WIDTH+ty)*Width + Col];
} else {
ds_N[ty][tx] = 0.0;
}
}
__syncthreads(); // 모든 data가 shared memory에 저장된 것을 보장
if (Row < Width && Col < Width) {
for (int i = 0; i < TILE_WIDTH; ++i)
Pvalue += ds_M[ty][i] * ds_N[i][tx];
}
}
__synchthreads(); // 모든 data가 계산된 것을 보장
if (Row < Width && Col < Width)
P[Row*Width+Col] = Pvalue;
}그러면 코드는 위와 같다.
`__syncthread()`를 사용하는 이유는 위와 같이, 모든 data가 shared memory에 저장된 것을 보장하고, 모든 data가 계산된 것을 보장하기 위해 사용한다.
- 첫 번째 `__syncthread()`는 thread의 실행 속도가 다르기 때문에 모든 data가 shared memory에 저장된 것을 보장한다.
- 두 번째 `__syncthread()`는 모든 data가 계산된 것을 보장한다. 만약 이것이 없다면 다음 phase에서 다른 값을 집어넣고, pvalue를 계산할 수 있기 때문에 꼭 필요하다.
for문에서 `p < (Width-1) / TILE_WIDTH + 1`는 phase의 ceil을 취한 것이다.
Tile Size 결정
tiling multiplication을 하면 TILE_WIDTH만큼의 global memory access 회수를 줄일 수 있다. 원래 구현이 N$^3$이라면, tiling multiplication에서는 2N$^2$ * $\frac{\text{N}}{\text{TILE_WIDTH}}$이다.
각 thread block은 TILE_WIDTH * TILE_WIDTH개의 thread를 가진다. 예를 들어 TILE_WIDTH가 16이면 16$^2$ = 256개의 thread를 가진다.
이 때, 각 thread block이 실행하는 연산 회수는 다음과 같다.
- M에 대해 1번, N에 대해 1번, 총 2 * [thread 개수]만큼의 float load
- for문에서 TILE_WIDTH * [thread 개수] 만큼의 multiply, TILE_WIDTH * [thread 개수]만큼 add operation, 총 2 * TILE_WIDTH * [thread 개수]만큼의 mul/add
- 그러면 1번의 load에 대해 TILE_WIDTH만큼의 연산을 할 수 있다.
그러나 무작정 TILE_WIDTH를 늘린다고 좋은 것은 아니다. shared memory size가 한정되어 있기 때문이다.
예를 들어 SM당 shared memory가 16KB라고 하자.
- 만약 TILE_WIDTH가 16이면 각 thread block은 2 * 16 * 16 * 4byte = 2KB의 shared memory를 사용하게 된다. 즉, 한 번에 8개의 thread block만 사용할 수 있다. 그러면 8 * 2 * [thread 개수]만큼의 pending load가 발생한다.
- 반면 TILE_WIDTH가 32면 각 thread block은 2 * 32 * 32 * 4byte = 8KB의 shared memory를 사용하게 된다. 즉, 한 번에 2개의 thread block을 사용할 수 있다. 그러나 GPU의 SM당 thread는 1536개로 제한되어 있으므로 SM당 block 수가 1개로 줄어든다. 한계는 1536인데 실제로 사용하는 것은 1024개로, thread의 낭비가 발생한다!
이처럼 shared memory size가 active thread의 개수를 한정하므로, 일반적으로는 thread block이 많은 것이 더 좋을 것이다. 그렇지만 thread block의 크기가 커지면 global memory access 회수가 줄어들므로 중간지점을 잘 잡아야 한다.
Unified Memory
높은 programmability를 위해 성능을 조금 향상한 것. GPU와 CPU 둘 다에서 사용할 수 있는 통합용 메모리이다. 잘못 사용하는 경우 성능이 급격하게 떨어지기 때문에 잘 사용해야 한다.
특히 tree나 graph traversal과 같은 몇몇 알고리즘은 GPU에서 돌리기 어려운데, unified memory는 이를 가능하게 한다.
이외에도 아래와 같은 특징들이 있다.
- 더 큰 memory를 제공한다 : GPU memory size보다 더 큰 data를 가져올 수 있다. paging mechanism을 사용해 GPU memory에 올리는 방식이다.
- data access가 더 쉽다 : CPU/GPU data coherence가 보장된다.
- unified memory는 programmability를 위한 것이기 때문에 user API가 많다. 예를 들어 cudaMemAdvise()는 어떤 memory에 접근하는지 hint를 제공하며 이를 바탕으로 성능을 향상시킨다. prefetching이라 생각하면 된다.
예시 : Unified Memory를 사용하지 않은 경우

`cudaMalloc()`을 사용해 GPU memory를 할당하고, `cudaMemcpy()`로 data를 복사하고, CUDA kernal launch 한다. 이후 `cudaMemcpy()`를 사용해 결과값을 CPU memory로 다시 가져오고, `cudaFree()`로 GPU memory를 해제해야 한다.
예시 : Unified Memory를 사용한 경우

코드가 훨씬 줄어든다. `cudaMallocManaged()`를 사용해 unified memory를 사용한다는 것을 알린다. 이 때 pointer는 CPU와 GPU 둘 다에서 사용할 수 있다. 이후 같은 pointer를 사용해 kernel launch한다. 이후 `cudaDeviceSynchronize()`로 data 처리 결과값을 받아온다. 마지막으로 `cudaFree()`한다.
- cudaMemcpy()는 synchronous이므로 추가적인 synchronize method가 필요없다. 반면 unified memory를 사용하는 경우 barrier를 사용한 synchronize가 필요하다.
작동 방식
위 코드 예시에서 볼 수 있듯 `cudaMallocManaged()`로 호출하며, demand paging 방식으로 작동한다.
`cudaMallocManaged()`을 호출하면 GPU에 memory를 할당하고, CPU memory에 할당된 data를 GPU memory로 내부적으로 알아서 옮겨준다. 이 때, CPU에서 값을 수정한 후 GPU에서 접근하면 알아서 값을 옮겨준다. 그 반대도 마찬가지다.
한편 page fault는 overhead가 크기 때문에 unified memory는 느릴 수 밖에 없다.
요약
memory와 data locality... 즉 memory hierarchy가 GPU의 성능을 결정한다. 일반적으로 GPU의 계산 속도는 빠르지만 memory bandwidth가 훨씬 작기 때문에 memory bandwidth를 덜 사용하는 것으로 throughput을 높일 수 있다.
이를 위해 `__shared__` - shared memory를 사용해 중복 global memory access를 줄이며, 이를 통해 memory bottleneck을 해소해 throughput을 높인다.
또한, architectural trend는 portability를 높이고 programming에 대한 부담을 줄이는 쪽으로 발전하고 있다. 때문에 unified memory 등 방법이 고안되었다.
잘못된 내용이나 오탈자에 대한 지적, 질문 등은 언제나 환영합니다.
'CS > Parallel Computing' 카테고리의 다른 글
| [이종병렬컴퓨팅] Performance Considerations (0) | 2023.10.28 |
|---|---|
| [이종병렬컴퓨팅] Thread Execution Efficiency (0) | 2023.10.28 |
| [이종병렬컴퓨팅] CUDA Basics (0) | 2023.10.26 |
| [이종병렬컴퓨팅] GPU architectures - NVIDIA (0) | 2023.10.25 |
| [이종병렬컴퓨팅] GPU architectures - SIMT와 SIMD (0) | 2023.10.25 |