![[이종병렬컴퓨팅] OpenMP](https://img1.daumcdn.net/thumb/R750x0/?scode=mtistory2&fname=https%3A%2F%2Fblog.kakaocdn.net%2Fdn%2FbyARfD%2FbtsB6LTbPSR%2FPNTyKrc6nFwJiIOtEvDic1%2Fimg.png)
이 글은 포스텍 성효진 교수님의 이종병렬컴퓨팅(CSED490C) 강의를 기반으로 재구성한 것입니다.
이 글에서는 OpenMP 프로그래밍 모델의 기본 개념과 pragma, 간단한 예제들을 살펴본다.
OpenMP
OpenMP API는 pragma(컴파일러 지시문), library routine, 환경변수 등을 제공한다. 이를 통해 multithread parallel fortran이나 C/C++ 프로그램을 쓸 수 있다.
programmability와 portability를 위한 high-level parallel structure를 제공한다. 때문에 low-level thread를 조작하는 것보다 parallel program을 쓰고 유지하는 것이 더 쉽다.
SMP 관행을 표준화하며, vectorization과 heterogeneous device programming도 지원한다.
Motivation
OpenMP 프로그래머는 1) sequential 버전으로 시작한 다음, 2) OpenMP 지시문을 추가한다. 그러면 대부분의 kernel 생성, memory allocation, data 전송을 OpenMP compiler에게 맡기게 된다.
한편, OpenMP 코드는 pragma를 무시하고 non-OpenMP 컴파일러에서 컴파일할 수 있다.
Tradeoff
장점으로는 low-level detail을 알 필요 없이 sequential program에서 parallel version으로 빠르게 변환할 수 있다.
단점은 OpenMP 프로그램의 성능은 컴파일러의 성능에 크게 의존한다. 몇몇 OpenMP pragma는 컴파일러에게 hint일 수 있지만, 그렇지 않을 수도 있다. 때문에 컴파일러가 pragma에 따라 동작하지 않는 이유를 찾기 어렵다. 이러한 불확실성은 CUDA나 OpenCL 프로그램에 비하면 훨씬 덜하다.
OpenMP common core
| OpenMP pragma, function, clause | 개념 |
| #pragma omp parallel | 병렬 영역, thread team, structured block, thread 간 교차 실행 |
| int omp_get_thread_num() int omp_get_num_threads() | 병렬 영역에서 thread를 생성하고, thread ID를 사용해 여러 개의 thread를 식별하고 작업을 분할한다. |
| double omp_get_wtime() | Amdahl's law를 적용한 speedup. false sharing과 기타 성능 문제 |
| setenv OMP_NUM_THREADS N | 내부 제어 변수로, 기본 thread 개수를 설정한다. |
| #pragma omp barrier #pragma omp critical | synchronization과 race conditioon. 교차 실행을 revisit한다. |
| #pragma omp for #pragma omp parallel for | workshaing, 병렬 loop, loop carried dependency |
| reduction(op:list) | thread team 사이에서 값을 reduction |
| schedule(dynamic [,chunk]) schedule (static [, chunk]) | loop 계획, loop overhead과 load balance |
| private(list), firstprivate(list), shared(list) | data 환경 |
| nowait | 작업 공유 구조에서 barrier 비활성화. barrier의 high cost. flush 개념 |
| #pragma omp single | single thread로 작업 공유 |
| #pragma omp task #pragma omp taskwait | 작업에 대한 데이터 환경을 포함한 작업 |
OpenMP Device Model
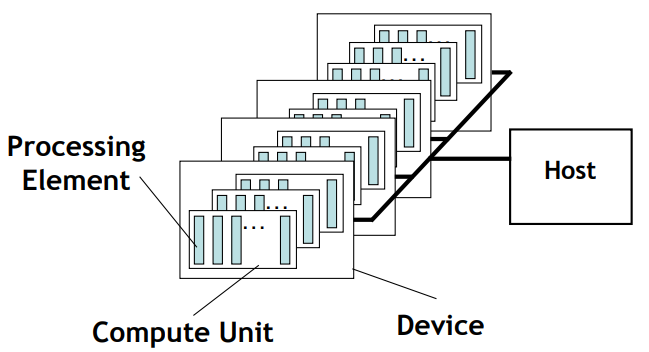
OpenMP는 host/device model을 사용한다. host는 초기 thread가 실행을 시작하는 위치이며, 0개 이상의 device가 host에 연결된다.
하나의 host, 여러 개의 device가 존재한다. 각 device는 1개 이상의 compute unit으로 구성되며, 각 compute unit은 1개 이상의 processing element로 구성된다.
memory는 host memory와 device memory로 분할된다.
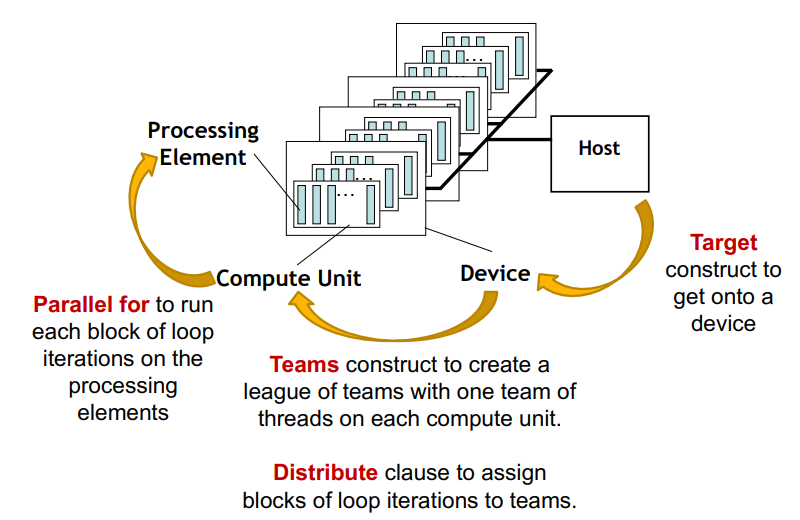
- target : device로 진입하기 위한 대상 구성
- teams : 각 computing unit에 하나의 team thread로 이뤄진 team league를 만든다.
- distribute : distribute clause로 team에게 loop iteration block을 할당한다.
- parallel for : 각 loop iteration block을 processing element에서 실행한다.
예시 : Vector Add
#include <omp.h>
#include <stdio.h>
#define N 1024
int main() {
float a[N], b[N], c[N];
// initialize a, b and c ....
#pragma omp target // thread는 host에서 실행된다.
for (int i = 0; i < N; i++)
c[i] += a[i] + b[i];
// Test results, report results ...
}여기서 `#pragma omp target`을 하면 thread는 host에서 실행된다. original variable i, a, b, c는 construct 초기에 device로 복사된다. target construct는 code 영역을 device로 offload한다. 이후 계산이 끝나면 i, a, b, c는 host로 돌아온다.
`target` : device에서 실행 중인 초기 thread가 code block의 code를 실행한다. 즉, single thread가 loop를 sequential하게 실행한다.
#include <omp.h>
#include <stdio.h>
#define N 1024
int main() {
float a[N], b[N], c[N];
// initialize a, b and c ....
#pragma omp target
#pragma omp teams
for (int i = 0; i < N; i++)
c[i] += a[i] + b[i];
// Test results, report results ...
}`teams` : 같은 개수의 thread를 가진 여러 개의 thread group이 시작된다. 실행은 각 team의 master thread에 의해 계속된다. team들끼리는 synchronization이 없다.
#include <omp.h>
#include <stdio.h>
#define N 1024
int main() {
float a[N], b[N], c[N];
// initialize a, b and c ....
#pragma omp target
#pragma omp teams distribute
for (int i = 0; i < N; i++)
c[i] += a[i] + b[i];
// Test results, report results ...
}`distribute` : team의 master thread가 loop iteration을 분배한다. (static distribution) 정해진 실행 순서가 없고, thread team 내부에서 parallelism이나 work-sharing을 생성하지 않는다.
#include <omp.h>
#include <stdio.h>
#define N 1024
int main() {
float a[N], b[N], c[N];
// initialize a, b and c ....
#pragma omp target
#pragma omp teams distribute parallel for
for (int i = 0; i < N; i++)
c[i] += a[i] + b[i];
// Test results, report results ...
}`parallel for` : loop 반복을 team 내의 thread에게 분배한다. `teams`가 없는 경우 오직 하나의 team만 존재하게 된다.
Target Data Environment
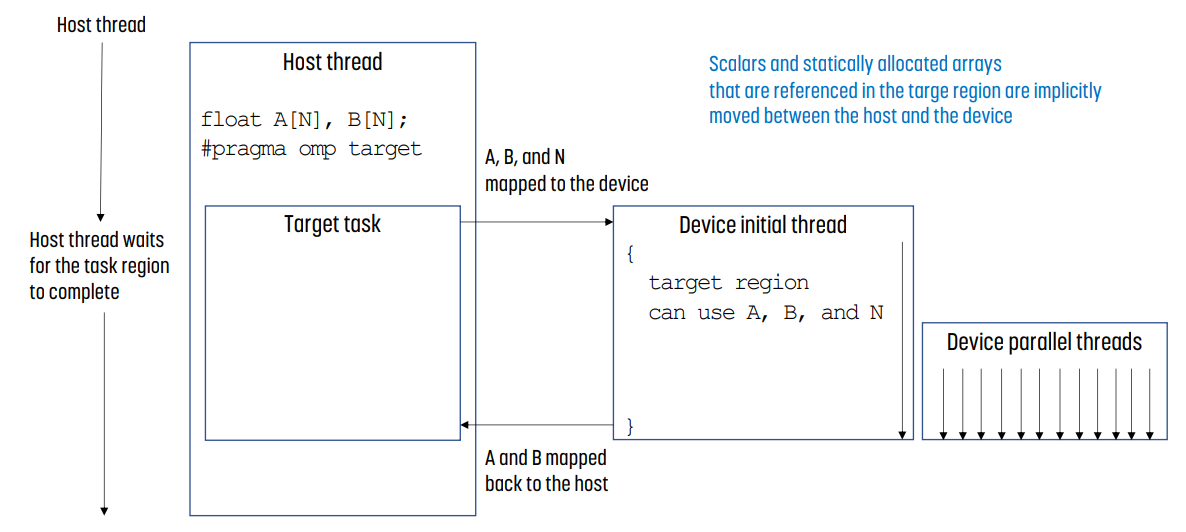
host thread에서 `#pragma`로 OpenMP를 실행시키면 다음과 같은 일이 일어난다.
- host thread는 task가 끝나기를 기다린다.
- A, B 등 원래 값들이 device로 복사된다.
- target 영역에서 참조된 scalar나 static allocated array는 implicitly하게 host - device에서 복사된다.
- device에서 값을 parallel하게 계산한다.
- device에서 계산이 끝난 A, B 등 변수 값들을 host로 돌린다.
- host thread가 이어 실행한다.
Data Movemont 관리
data movement는 `map`을 사용해 explicitly 관리할 수 있다.
int i, a[N], b[N], c[N];
#pragma omp target map(to:a, b) map(toform:c)- map(to: list) : device에서 read-only data
- map(from: list) : device에서 write-only data. target 영역의 끝에서 list 내의 변수들이 원래 값에 복사된다.
- map(tofrom: list) : to와 from 둘 다 동작한다.
- map(alloc: list) : data가 device에서 할당되고, 초기화되지 않은 상태
- map(to: a[0:N]) : pointer의 경우 array notation을 사용해야 한다.
이외 자주 사용되는 Clause
Target과 자주 사용되는 Clause
#pragma omp target [clause[[,]clause]...]
structure-block- if (scalar expression) : scalar expression이 false면 target은 host에 의해 실행된다.
- device (integer expression) : integer expression의 값은 device를 결정한다.
- private(list) firstprivate(list) : list에 있는 변수와 동일한 변수를 device에 생성한다. firstprivate의 경우 host에서 원래 변수의 값이 device에서 생성된 private 변수로 복사된다.
- map(map-type: list[0:N]) : list의 변수가 host와 device 간에 어떻게 이동하는지 정의한다.
- nowait : target 작업이 연기되어 host와 target 영역이 parallel하게 실행된다.
Teams Distribute Parallel For과 사용되는 Clause
#pragma omp teams distribute parallel for [clause[[,]clause]...]
for-loop- reduction(reduction-identifier : list) : list의 변수에 대해 reduction 연산을 수행한다. reduction 변수는 map clause에도 나타나야 한다.
- collapse(n) : distribute 지시어가 iteration을 team에게 분배하기 전에 loop를 합친다.
- schedule(kind[, chunk_size]) : loop iteration을 team에게 분배하는 것을 제어한다.
Target Data Directive
#pragma omp target data map(to: A,B) map(from: C)
{
#pragma omp target
// do lots of stuff with A, B, and C
//do something on the host
#pragma omp target
// do lots of stuff with A, B, and C
}- `target data`는 target data region을 생성한다.
- `map`은 explicit한 data 관리를 위해 사용한다. device data 환경에 data가 지시문의 시작과 끝에 복사한다.
- `target data` 영역 내에서 여러 `target` 지시문이 하나의 data 영역과 작업할 수 있다.
Target Update Directive
#pragma omp target data map(to: A,B) map(from: C)
{
#pragma omp target
// do lots of stuff with A, B, and C
#pragma omp target update from(A)
// do something with A on the host
#pragma omp target update to(A)
#pragma omp target
// do lots of stuff with A, B, and C`target update`를 사용해 target 영역 간의 data를 갱신할 수 있다.
CUDA vs OpenMP : Vadd
- CUDA의 경우
_global__ vadd(float *a, float *b, float *c) {
int i = blockDim.x * blockIdx.x + threadIdx.x;
c[i] += a[i] + b[i];
}
- OpenMP의 경우
#include<omp.h>
#include<stdio.h>
#define N 1024
int main() {
float a[N], b[N], c[N];
// initialize a, b and c ....
#pragma omp target map(to:a,b) map(tofrom:c) // device로 정보 옮김
#pragma omp teams num_teams(NCU) thread_limit(NPE) // device 묘사. NCU는 CU의 개수, NPE는 CU당 PE의 개수
#pragma omp distribute // thread block을 compute unit에게 분배
for (ib=0; ib<N; ib+=tbsize)
#pragma omp parallel for // 바로 아래의 for문은 thread block의 개별 thread가 실행
for(int i=ib; i<ib+tbsize; i++)
c[i] += a[i] + b[i];
// Test results, report results ...
}
잘못된 내용이나 오탈자에 대한 지적, 질문 등은 언제나 환영합니다.
'CS > Parallel Computing' 카테고리의 다른 글
| [이종병렬컴퓨팅] Accelerators for Deep Learning (0) | 2023.12.20 |
|---|---|
| [이종병렬컴퓨팅] Heterogeneous Parallel Computer를 위한 기술 스택 (0) | 2023.12.18 |
| [이종병렬컴퓨팅] Parallel Patterns : Sparse Computation (1) | 2023.12.17 |
| [이종병렬컴퓨팅] Parallel Patterns : Scan (0) | 2023.12.17 |
| [이종병렬컴퓨팅] Parallel Patterns : Reduction (0) | 2023.12.16 |