![[이종병렬컴퓨팅] Parallel Computing Basics](https://img1.daumcdn.net/thumb/R750x0/?scode=mtistory2&fname=https%3A%2F%2Fblog.kakaocdn.net%2Fdn%2FbJlwiH%2Fbtsy9la7lxV%2F34QWKxb5eokS2kVuwnl3V0%2Fimg.png)
이 글은 포스텍 성효진 교수님의 이종병렬컴퓨팅(CSED490C) 강의를 기반으로 재구성한 것입니다.
이 글에서는 다음과 같은 내용을 살핀다.
- parallel computing의 기본적인 개념
- parallelism의 종류
- parallel architecture 분류
- parallel program을 어떻게 작성하고 어떤 기준으로 평가하는지
Parallelism의 종류
크게 3가지의 parallelism이 있다.
- ILP, Instruction Level Parallelism
- instruction들끼리 independent하다.
- hardware는 instruction window size 내내에서 implicit하게 찾을 수 있다.
- complier들은 window 내에 있는 명령어들이 independent할 수 있도록 찾아서 순서를 바꾼다. independent한 순서로 재배열 한 후 실행하는 방식이다.
- TLP, Thread Level Parallelism
- complier와 programmer가 program을 명시적으로 나눈다.
- DLP, Data Level Parallelism
- TLP의 variation 중 하나로, 같은 instruction을 실행하는 여러 개의 thread가 다른 data에 대해 동작하는 방식이다.
예시

위쪽 부분은 programmer view를, 아래쪽 부분은 실제 작동 방식을 나타낸다.
- ILP의 경우 independent한 instruction을 적당히 동시에 실행시킨다. hardware가 수행하기에 programmer는 이에 대해 알 수 없다.
- TLP의 경우 programmer가 instruction을 나누어 배치했기 때문에 해당 instruction들끼리는 parallel하게 실행되는 모습이다. programmer가 instruction을 나누었기 떄문에 이를 인지하고 있다.
- DLP의 경우 같은 종류의 data는 같은 instruction이 실행되는 모습이다. TLP의 variation인 만큼 programmer도 이를 인지하고 있다.
Flynn's Taxonomy
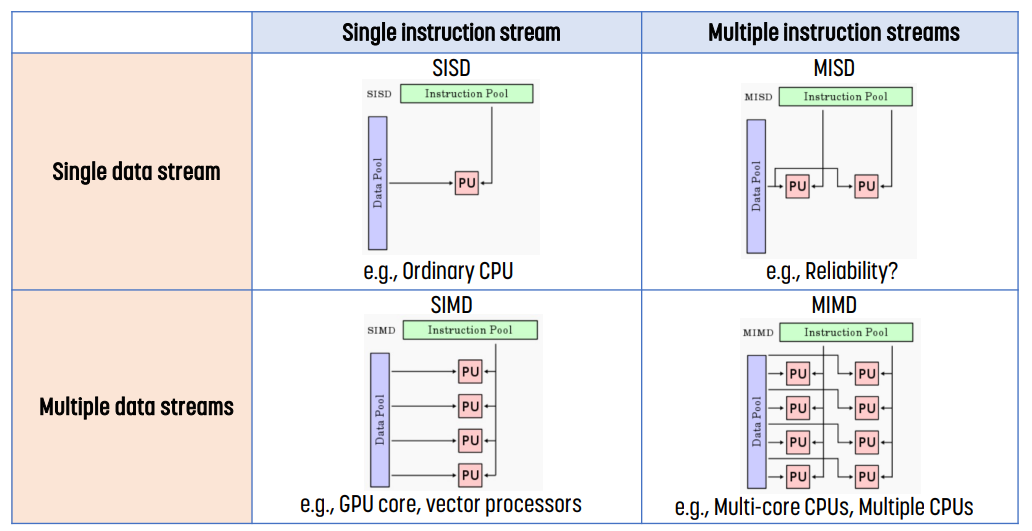
single instruction stream은 single thread를, multiple instruction stream은 multiple thread를 의미한다.
multiple data streams & single instruction stream - (1, 0)에 있는 것 - 은 DLP를, multiple data streams & multiple instruction streams - (1, 1)에 있는 것 - 은 TLP를 의미한다.
Hardware가 parallelism을 달성하는 방법
- ILP
- Superscalar : single thread에서 여러 개의 instruction을 실행하는 방식이다. instruction dependency가 없는 instruction만 하나의 cycle에 동시에 실행되기 때문에 dependency에 크게 영향을 받는다.
- TLP
- Find Grain Multithreading : thread 간 context switching이 빠르다. 매 cycle마다 다른 thread를 교체해서 실행하는 방식이다. (single core)
- SMT, Simultaneous MultiThreading : 같은 cycle에 여러 개의 thread의 instruction을 실행하는 방식이다. (multi core)
- CMP, Chip Multi Processors : 하나의 chip에 여러 개의 core를 탑재하고 각 thread를 다른 core에서 실행하는 방식이다.
- DLP
- Vector Processors : data의 여러 부분에 작동하는 single instruction을 실행하는 방식이다.
Parallel vs Concurrency
Parallel은 여러 개의 resource(CPU나 core 등)을 사용해 single prcessor에서보다 더 빨리 푸는 방식이다. 예를 들어 merge-sort의 경우 각 thread가 data의 각 부분을 정렬하고, 합치는 parallel을 생각할 수 있다.
Concurrency는 여러 개의 execution flow를 동시에 실행하는 것처럼 보이는 방식이다.
Parallel Algorithm Design
concurrency를 달성하기 위해서는 programmer가 concurrency를 인지하고 아래 3가지를 잘 다뤄야 한다.
- dependency를 올바르게 관리
- concurrency 관리로 발생하는 overhead 최소화
- balanced한 방식으로 work를 나누기
때문에 parallel program을 설계하는 방식은 크게 아래와 같다.
- parallel하게 수행할 수 있는 작업 식별
- task, data 분할
- data access, communication, synchronization 관리
이를 통해 program을 parallel하게 실행해서 성능을 향상시키는 것이 목적이다.
Speedup(P processors) = $\frac{\text{Time(1 processor)}}{\text{Time(P processors)}}$
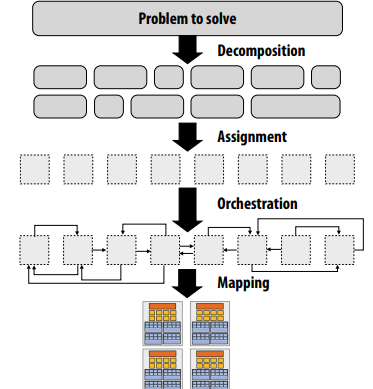
이 단계를 그림으로 표현하면 위와 같다.
decomposition은 work를 subwork로 나누는 것, assignment는 core에 work를 할당하는 것, orchestration은 communication을 하는 부분을 말한다. mapping은 hardward에 mapping하는 과정으로, 이 과정은 보통 OS가 수행한다.
Parallel Algorithm의 목표
제일 좋은 방식은 아래 3가지를 모두 달성하는 것이다.
- Maximize parallelism
- Minimize communication
- Minimize load imbalance
그러나 실제로는 이런 3가지를 모두 달성하기는 매우 어렵다. 아래와 같은 conflict에서 적당한 위치를 찾아야 한다.
- parallelism vs communication : 이 둘은 tradeoff이다.
- load imbalance vs communication : 이 둘은 tradeoff이다.
- architectural contraints의 한계
Parallel Algorithm의 구성 요소
parallel algorithm은 위 그림에서 언급되었듯 크게 3가지로 나뉜다.
- Task Decomposition: 문제를 동시에 실행할 수 있는 작업으로 나누는 것
- Mapping & Scheduling : task를 여러 computing unit에 할당하고 input/output/중간 data를 배포하는 과정
- Communication & Synchronization : parallel execution의 다양한 지점에서 task를 동기화
Task Decomposition
task를 개별적인 작업으로 나누어 사용하는 방법. execution unit이 최대한 busy하게 두면서 dependency를 최소화하는 방법이 기본적인 골자이다. 이 때, task를 지나치게 잘게 쪼개면 thread의 생성/관리에 필요한 overhead가 더 커지기 떄문에 적당히 작은 크기로 쪼개는 것이 좋다.
나누는 방법은 다음과 같은 방법들이 있다.
- 어떻게 나누는지
- domain decomposition : operation을 나누는 것이 아니라 data만 나누어서 같은 연산을 수행하는 방식이다.
- functional decomposition : 문제의 분류에 따라 나누는 방식이다. 다른 작업으로 나뉘기에 다른 연산을 수행한다.
- 언제 나누는지
- static decomposition : 계산하기 전에 decomposition을 결정하는 방식이다.
- dynamic decomposition : 입력에 따라 decomposition을 결정하는 방식으로, 나눌 때 발생하는 overhead가 있다. 예시로 sparse matrix multiplication이 있다.
- 어떠한 크기로 나누는지
- coarse-grained task : 크게크게 나누는 방법. communication overhead가 적지만 load imbalance가 발생한다.
- fine-grained task : 세밀하게 나누는 방법. communication overhead가 크지만 load balance하다.
parallel execution overhead는 `communication/synchronization cost + idling + excess work`의 3가지로 표현된다.
이 때, 너무 세밀하게 나누면 overhead가 너무 커지고, 너무 크게 나누면 load imbalance가 너무 커지기 때문에 overhead와 load imbalance가 균형을 이루는 지점을 잘 잡아 task decomposition해야 한다.
Mapping and Scheduling
이 단계는 decompose한 task를 어떤 processing unit에게 할당하고(mapping), 언제 실행할지(scheduling) 결정하는 단계이다.
- static mapping and scheduling
- task가 실행 전에 processing unit에 할당되는 방식이다.
- 때문에 task size가 고정된 경우에 쓸 수 있다.
- overhead가 적다.
- dynamic mapping and scheduling
- task가 실행 중에 동적으로 processing unit에 할당되는 방식이다. scheduler가 다음에 실행할 작업을 결정하고 core에 할당한다. 때문에 task queue 등 자료구조가 필요하다.
- task 크기를 모르는 경우에 써야 한다.
- overhead가 높지만, load imbalance를 줄일 수 있다.
예시
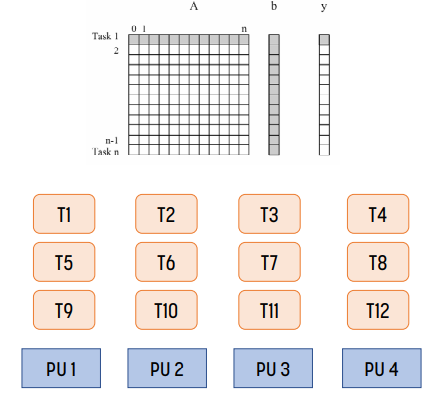
이러한 예시가 있다고 하자. Tn은 n번째 row를 처리한다고 하자. 위 경우, static decomposition, static mapping을 사용했다. 이 경우 locality가 나쁘다! T1, T5, T9가 하나의 processing unit에서 사용되는데, 서로 다른 cache를 보기 때문이다.

locality를 개선하면 위 그림과 같다. T1, T2, T3가 같은 processing unit에 속하므로 cache를 좀 더 효율적으로 쓸 수 있다.
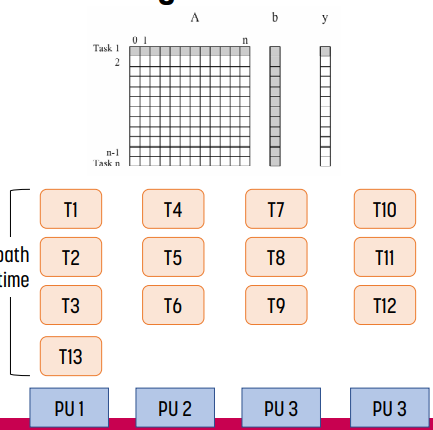
이 상태에서 위와 같은 상황이 되면 어떨까? processing unit 1에 추가적인 load가 생기기 때문에 load imbalance가 생긴다. 때문에 T13을 끝낼 때 까지 cycle을 낭비하게 된다.

이를 해결하는 방법 중 하나가 fine-grained task이다. task를 좀 더 쪼개면 cycle 낭비가 있더라도 그 낭비를 더 줄일 수 있다.
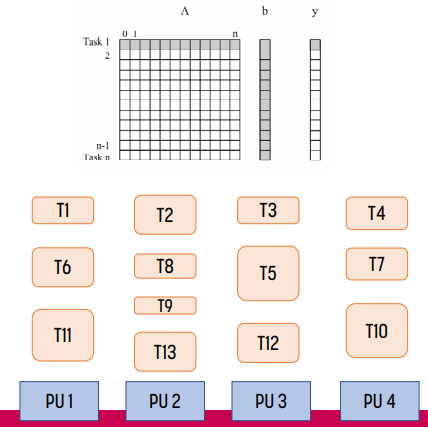
다른 한 가지 해결 방법은 dynamic mapping이다. task를 dynamic하게 나눠서 다른 processing unit이 task를 끝낼 때 쯤 다른 task를 할당하는 방식이다. 이 방법은 앞에서 설명했듯 granularity를 설정하기 위한 scheduling overhead가 발생한다.
Overhead 최소화 방법
overhead를 최소화하는 방법은 아래와 같은 방법들이 있다.
- independent task를 다른 core에 할당 : 만약 depedent task를 다른 core에 할당하는 경우 core끼리 통신하기 위해 barrier나 log가 필요하다. 때문에 independent task를 다른 core에 쓰는 것이 좋다.
- parallelism을 최대화한다.
- critical path를 최대한 빨리 할당 : 다른 작업들보다 오래 걸리는 작업은 먼저 수행하는 것이 좋다. 이 작업을 나중에 수행하면 다른 core들이 idling하기 떄문이다.
- load imbalance를 최소화한다.
- communication 최소화 : 첫 번째 것과 관련이 있는 내용으로, communication을 최소화하면 최대한 independent task를 다른 core에 할당해야 한다.
- overhead를 최소화한다.
이러한 기준들은 서로 충돌할 수 있다. 예를 들어 indepedent task의 개수를 찾을 수 없을 수도 있고, 다른 core에 dependent task를 할당해야 할 수도 있다. 때문에 balance를 잘 맞춰야 한다.
Communication and Synchronization
parallel task 사이에서 data를 공유하는 부분을 의미하며, thread끼리의 communication, synchronization에 관한 것이기 때문에 그 자체로 race condition을 만든다. 따라서 parallel thread로 동작하는 경우, communication cost는 sequential program에 동작하지 않는 순수한 overhead이다. lock contention의 경우 network를 사용한다는 문제점도 있다.
communication은 문제에 따라 필요할 수도 있고, 그렇지 않을 수도 있다. 문제가 communication이 거의 없는 경우 그냥 바로 하면 된다. 앞서 matrix add 예시가 그것이다.
이를 사용하는 방법은 크게 2가지가 있다.
- message passing model : communication이 explicit한 방식이다.
- 더 많은 programming을 해야 하고, flexible하지 않지만 이해하기 쉽다.
- shared memory model : communication이 implicit한 방식이다. coherence protocol 등 software나 hardward의 communication support가 있어야 한다.
- 프로그래밍 자체는 쉽지만 어디서 버그가 났는지 찾기 어렵다.
Communication의 종류
크게 collective, point-to-point가 있다.
Barrier Synchronization (collective)
먼저 collective이다.
1 to all, all to all을 수행하는 broadcast(multicsat)와 all to one을 수행하는 reduction이 있다. 별개로 scatter/gatter로 하기도 한다.
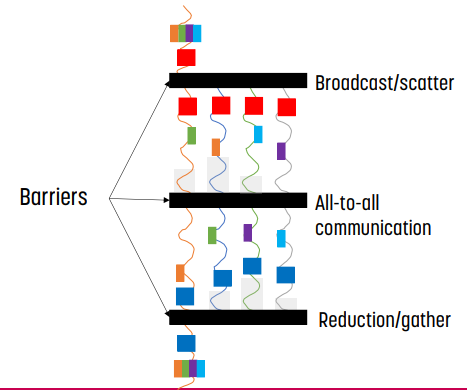
위 그림과 같이 parallel program은 barrir로 의해 단계가 나눠진다.
- 제일 처음에는 broadcast / scatter로 parallel하게 나눠진다.
- 각 단계에서는 parallel하게 실행되고, barrier에서는 communicate가 실행된다.
- 마지막에는 reduction / gather가 실행된다.
barrier를 사용하는 경우 depedency를 사용하는, coarse-grained한 방식이다. 각 단계의 연산은 이전 단계의 연산(이전 단계의 barrier에서 완료된)에 의존한다.
Point to Point Synchronization
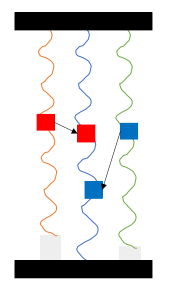
다음으로 point to point로, lock을 사용하는 방식이다. 때문에 하나의 thread만 critical section에 진입할 수 있다.
이 경우 fine grained이기 때문에 더 빠르며, lock이 필요한 각각의 thread가 1대1로 통신하기 때문에 통신에 대한 overhead도 더 적다.
Communication Overhead
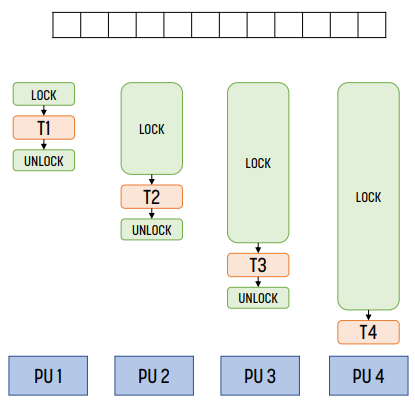
위 그림과 같은 경우 communication overhead = synchronization time + data communication time이다.
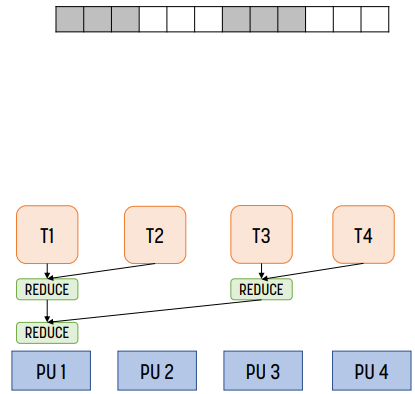
task를 위 그림과 같이 n/4 iteration으로 나눈 경우, distributed reduction이다. 이 경우 communication overhead = reduction time + data communication time이다.
위 경우에서는 distributed reduction을 한 경우가 좋은데, 항상 그런 것은 아니다. 예를 들어 core가 1개, 또는 2개인 경우 task를 reduction하고 합치는 시간이 더 많이 들어가기 때문에 전자의 방식이 더 좋다. 일반적으로는 core가 4개 이상일 때 distributed reduction을 하는 것이 좋다고 한다.
현대로 올수록 computation 속도가 매우 빨라졌기 때문에 communication cost보다 communication cost가 훨씬 더 크다.
- data locality 최대화
- data exchange 최소화
- communication 최소화
- contention 최소화
- computation과 communication 겹치기 (non-blocking communication의 경우)
Performance Modeling
- 실행 시간 $T_p$ : p개의 processor가 문제를 해결하는 데 걸린 시간
- 전체 overhead $T_0 = pT_{p} - T_s$
- speedup $S_p = \frac{T_s}{T_p}$ : sequential 실행 시간 / parallel 실행 시간
- 효율 E = $\frac{S_p}{p} = \frac{T_s}{p \times T_p}$
- parallel execution으로 얼마나 더 많은 task를 했는지에 대한 지표.
- 만약 E가 1보다 큰 경우 superlinear라 한다.
Amdahl's Law
변경으로 인해 f 부분이 K배 향상된 경우, 기존 실행 시간이 T = (1-f)T + fT일 때, 향상된 시간은 $T_K$ = (1-f)T + $\frac{f}{K}$T이다.
parallel programming에서 f는 parallel하게 실행되는 부분이다. 즉슨, (1-f) 부분은 sequential한 부분이라는 뜻이다.
그러면 speedup은 아래와 같다.
speedup S = $\frac{T}{T_K} = \frac{1}{(1-f) + \frac{f}{K}}$
이 수식 아래서 최대한 값을 키우는 것이 목적이므로 아래 2가지 방법을 모두 사용한다.
- f를 크게 만들어야 한다: parallel한 부분의 비중을 높여야 한다.
- f가 0.5인 경우 2배의 speedup이지만, 0.95인 경우는 20배의 speedup이다.
- K를 크게 만들어야 한다: core 개수를 늘려야 한다.
- data parallel computation의 경우 K를 키우기만 하면 된다. (core 개수만 늘이면 된다.)
- task parallel computation의 경우, parallel task는 고정되어 있기 때문에 K를 늘이기 쉽지 않다.
Scalability
$E_p$가 problem size가 변해도 계속 유지된다면 scalable하다고 한다. 일반적으로 p가 늘어나면 synchronization cost가 증가하기 때문에, core를 늘이더라도 동일한 효율을 얻을 수 없는 경우가 생긴다. $E_p$에 영향을 미치는 것은 communication과 synchronization이 대부분이다.
- strong scaling : problem size를 고정한 채로 K만 늘이는 방법. 예를 들어 n size의 문제를 1개, 2개, 4개, ...의 core로 해결할 때 speedup을 보는 방식이다.
- weak scaling : core가 담당하는 problem size를 고정한 상태로 problem size를 늘이는 방법. 일반적으로 이야기하는 scalability이다.
Parallelization Techniques
따라서, parallel한 프로그램을 짜고 싶다면 다음과 같은 단계를 거쳐야 한다.
Parallel Algorithm 설계
- parallel하게 해결하고 싶은 문제를 식별하고, parallel하게 풀 수 있는지 확인한다.
- 병목을 식별하고, 해당 부분을 parallelism을 적용한다. 이 때 overhead와 load imbalance를 최소화해야 한다.
Computation
- dependence graph를 사용해 task/data dependence를 분석한다.
- critical path를 최소화한다. 이는 load imbalance를 줄이는 효과도 있다.
- data dependency를 최소화한다. dependency가 있는 부분은 parallel의 효과가 떨어지기 때문이다. 특히 loop를 사용하는 부분을 잘 보아야 한다.
Synchronization and Load Imbalance
- centralized 대신 distributed 방식을 사용해서 공유 정도를 줄인다.
- lock-free와 synchronization-free 알고리즘을 사용한다.
- coarse-grained task decomposition을 지양한다.
- critical path에 더 높은 priority를 부여한다.
Communication
- data locality를 신경써야 한다.
- communication과 computation을 최대한 겹쳐야 한다.
- 몇몇 경우, communicate보다 다시 계산하는 것이 더 빠를 수도 있다.
잘못된 내용이나 오탈자에 대한 지적, 질문 등은 언제나 환영합니다.
'CS > Parallel Computing' 카테고리의 다른 글
| [이종병렬컴퓨팅] Thread Execution Efficiency (0) | 2023.10.28 |
|---|---|
| [이종병렬컴퓨팅] Memory와 Data Locality - Tiled Multiplication & Unified Memory (0) | 2023.10.27 |
| [이종병렬컴퓨팅] CUDA Basics (0) | 2023.10.26 |
| [이종병렬컴퓨팅] GPU architectures - NVIDIA (0) | 2023.10.25 |
| [이종병렬컴퓨팅] GPU architectures - SIMT와 SIMD (0) | 2023.10.25 |