[이종병렬컴퓨팅] Thread Execution Efficiency
이 글은 포스텍 성효진 교수님의 이종병렬컴퓨팅(CSED490C) 강의를 기반으로 재구성한 것입니다.
이 글에서는 다음과 같은 내용들을 살핀다.
- SIMD hardware에서 GPU thread가 실행되는 방식 : warp partitioning, control divergence
- control divergence가 성능에 미치는 영향을 분석하는 방법 : boundary condition checking
- GPU thread execution을 겹치는 방법 : CUDA stream
- GPU의 synchronization primitive 동작 : warp synchronization, atomics
SIMD hardware에서 GPU thread가 실행되는 방식
Scheduling Thread Blocks
hardware는 thread block을 가능한 processor에게 보내며, 어떤 SM이 어떤 thread block을 실행할지 결정한다.
- GPU는 많은 processor(SM)들이 있다. 보통 16개 ~ 132개 정도가 있다.
- 각 processor는 여러 thread block을 concurrent하게 실행할 수 있다. 때문에 kernel launch가 충분한 thread block을 생성해서 busy한 상태를 유지하게 하는지 살펴야 한다. (이에는 memory latency를 숨기는 효과도 있다.)
- thread block의 개수가 SM의 개수보다 작으면 SM을 모두 사용하지 못하는 것이고, 즉슨 성능을 100% 활용하지 못하는 것이다.
- hardware는 resource가 사용가능할 때 thread block을 실행한다. 때문에 thread block 간의 순서가 보장되지 않으므로 이에 알고리즘이 thread block의 실행 순서에 영향을 받지 않게 설계해야 한다.
Scheduling 단위로써 Warp
- 각 thread block은 하나 이상의 warp에 mapping된다.
- hardware scheduler는 각 warp를 independent하게 scheduling한다. 즉, warp가 scheduling의 단위이다.
- warp 안의 thread는 SIMD 방식으로 함께 수행된다.
- thread block의 다른 warp는 independent하게 실행된다. 예를 들어 warp size가 32인 경우, thread block 크기가 32보다 크면 thread block을 실행하는 warp는 2개 이상으로 나뉘며, 이 warp들은 independent하게 실행된다.
- warp의 크기나 execution/communication model은 버전/제조사에 따라 다르다.
N차원 Thread Block에서 Warp
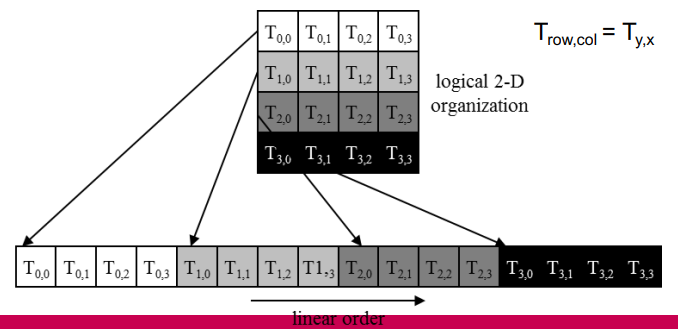
n-D 형태의 thread block은 row-major 순서로 1D로 linearize되며, x, y, z축 순서이다.

이렇게 나누는 이유는 thread block을 warp로 나누기 위함이다.
- 1D로 바뀐 thread block은 warp로 나뉘며, warp 내의 thread index는 연속적이며 증가한다.
- partitioning하는 방식은 모든 기기에서 동일하므로 control flow에 사용할 수 있다. CUDA의 경우 어떤 warp에 어떤 thread를 넣을지 explicit하게 설정할 수 있다.
위 예시에서는 4 by 6 by 2의 형태인데, 여기서 warp를 할당하기 위해 1D로 펼치고 32개의 thread를 하나의 warp에 넣는다. 0부터 31까지는 warp 0에, 32부터 64까지는 warp 1에, ... 넣는다.
Warp 채우기
- thread block은 warp를 가득 채울 수 있는 것이 좋다.
- 예를 들어 thread block size가 1이면 1개의 warp에 할당되지만 나머지 부분이 비어서 별로다.
- 32면 1개의 warp에 할당되지만 warp의 빈 공간이 적어서 좋다.
- 128이면 4개의 warp를 채울 수 있어서 더 좋다.
- hardware가 warp를 전환할 수 있게 하려면 thread block당 충분한 thread가 존재해야 한다. thread block이 warp에 매핑되기 때문이며, warp가 여러 개 있어야 memory access latency를 숨길 수 있기 때문이다.
- scratchpad memory와 같은 resource는 thread block당 thread 개수를 제한할 수도 있다. 앞선 글에서 살펴본 것처럼 한 thread block에 너무 많은 thread가 할당되면 하나의 SM에서 실행할 수 있는 thread의 개수가 낭비되기 때문이다.
- thread의 개수가 thread block의 개수의 배수가 아니면 kernel 내부에 boundary test를 삽입해야 한다. 앞서 살펴본 if문과 동일하다.
- boundary test가 없는 경우 thread blodk이 array의 index 외부에 접근할 수 있기 때문이다.
Control Divergence
warp의 모든 thread는 동일한 instruction을 실행해야 한다. 때문에, 모든 thread가 같은 control flow path를 따르는 경우 제일 효율적이다.
- 예를 들어 모든 if-then-else는 같은 결정을 내리며, 모든 loop는 같은 회수만큼 반복된다.
만약 warp의 thread가 branch로 인해 서로 다른 작업을 수행하면 어떻게 될까? 이게 control divergence이다.
이 내용은 SIMT와 SIMD 포스팅에서 잠깐 다뤘었다.
control divergence는 서로 다른 control decision이 발생해 서로 다른 control flow path로 갈 때 발생한다.
- 예를 들어, if-then-else에서 몇몇은 then으로, 몇몇은 else로 가는 경우이다.
- 다른 예로 몇몇 thread가 loop 회수가 다를 수도 있다.
이 때, 서로 다른 path를 사용하는 경우, GPU 내부에서 serialize된다. 모든 warp의 thread는 같은 instruction을 실행해야 하기 때문이다.
- warp의 thread가 선택한 control path는 더 이상 다른 path를 가진 thread가 없을 때까지 한 번에 하나의 path에 해당하는 thread를 실행한다. 돌지 않는 thread는 idling한다.
- 각 path를 실행하는 동안 모든 thread는 parallel하게 실행되며, 해당 path를 사용하지 않는 모든 thread는 mask된다.
예시


위와 같은 상황을 고려해 보자. 한 warp에는 32개의 thread가 들어간다.

- 파란색 warp 1에 속한 thread들은 모두 같은 control decision을 내리기 때문에 divergence가 없다.
- 빨간색 warp 2에 속한 thread들의 경우 일부 thread는 threadIdx.y가 0이고, 일부 thread는 아니다. 때문에 [B에 해당하는 control decision을 내린 thread들]과 [C에 해당하는 control decision들을 내린 thread들]을 serialize해서 실행한다. 이후 D는 모든 thread가 같은 control decision을 내렸기 때문에 모두 같이 실행된 모습이다. 이 경우 divergence이다.
- 초록색 warp 3에 속한 thread들의 경우 thread block이 warp size를 삐져나갔다. 때문에 warp 내에 있는 thread들만 활성화된 모습을 볼 수 있다. 이 경우 divergence는 아니다.
Nested Control Divergence

위 그림처럼 nested branch가 있는 경우, 모든 branch가 serialize되므로 divergence가 더 심해진다.
Divergent Iteration
__global__ void per_thread_sum(int *indices, float *data, float *sums)
{
...
// number of loop iterations is data dependent
for(int j=indices[i]; j<indices[i+1]; j++)
{
sum += data[j];
}
sums[i] = sum;
}nested loop 이외에도 나쁜 divergent의 예시이다.
위와 같은 kernel code를 실행한다고 하자. 이 경우 실행 회수가 모두 다르기 때문에 thread 하나가 전체 warp의 실행 시간을 결정할 수도 있다.
Control Divergence가 성능에 미치는 영향
divergence는 프로그램의 정확성에 영향을 주지 않기 때문에, 프로그램을 짤 때 divergence에 대해 correctness를 고려할 필요가 없다.
control divergence가 있는 코드가 synchronization을 할 때 deadlock이 발생하기도 하지만, 매우 드물다.
그렇지만 일반적으로 divergence가 많아질수록 성능이 떨어지기 때문에, performance를 분석하고 divergence를 줄일 수 있도록 해야 한다. 1개 정도는 괜찮지만, nested branch는 지양해야 한다.
예시 : control divergence가 성능에 미치는 영향
array size가 1000이고, thread block당 256개의 thread가 있고, 각 thread block당 8개의 warp가 있다고 하자.
- thread block 0, 1, 2에 해당하는 thread들은 0부터 767이며, 총 24개의 warp가 있다. 이들은 control divergence가 없다.
- thread block 3에서 control divergence가 발생한다.
- warp 0 ~ 6 (thread 0 ~ 223)까지는 1000 안에 들어오므로 control divergence가 없다.
- warp 7의 992 ~ 999에 해당하는 thread들은 범위 내에 있다.
- warp 7의 1000 ~ 1023에 해당하는 thread들은 범위 밖에 있다.
- 이 경우 32개의 warp 중 1개의 warp에 control divergence가 발생하기 때문에 성능에 미치는 영향은 약 3%일 것이다.
이처럼 큰 input data에 대해서는 boundary test로 인한 영향이 적어야 한다. 그렇지만 기능이 올바르게 동작하는 것을 보장하기 위해서는 boundary test를 사용해야 한다.
Addressing Control Divergence Guideline
- control divergence로 인해 parallel의 효율이 매우 크게 저하될 수 있다. worst case, 한 thread만이 매우 복잡한 branch를 따르고 나머지 32개의 thread는 그렇지 않다면 32배 성능 손실을 본다.
- warp 내부에서 divergence를 피해야 한다. 다른 warp는 다른 code를 실행할 수 있으므로 성능에 영향을 주지 않는다.
// divergence가 발생하는 예시
// branch granularity < warp size
if (threadIdx.x > 2) {...}
else {...}
// divergence가 발생하지 않는 예시
// branch granularity is a whole multiple of warp size
if (threadIdx.x / WARP_SIZE > 2) {...}
else {...}위 예시와 같은 방법을 쓸 수 있다.
위 코드는 무조건 divergence가 발생한다. 반면 아래 코드의 경우, 특정 warp에 대해서만 if문이 걸리기 때문에 divergence가 발생하지 않는다.
- cost를 고려해서 boundary test를 해야 한다.
- 만약 boundary test cost가 낮다면 branch를 써도 된다.
- 반면 boundary test cost가 높다면 여러 개의 kernel을 사용하는 것이 좋다. 예를 들어 하나는 범위 내의 것, 하나는 범위 밖의 것으로.
- kernel specialization : cost가 매우 크게 드는 일부 목록을 분리하는 방법이다.
Concurrency With Stream
Synchronicity
- 폰 노이만 모델은 계산 단계가 synchronous이다.
- 실제로는 false인 경우가 대부분이다. compiler나 out of order reorder나 pipelined CPU가 instruction을 중복한다. 이처럼 실제 동작은 다르다.
- 그러나 여전히 abstract level을 보는 programmer에게는 synchronous한 실행으로 보인다.
- 만약 program level에서 asynchronous하다면 프로그래머는 어떤 일이 어떤 순서로 일어나는지 면밀히 관심을 가져야 한다.
- GPU의 경우 host와 kernel code의 synchronicity와, GPU stream들끼리의 synchronicity를 고려해야 한다.
GPU Kernel Code에서 Synchronicity
- 하나의 warp에서 코드는 synchronous하게 실행된다. 즉 모든 instruction은 이전 instruction이 끝날 때까지 기다린다.
- 다른 warp들은 랜덤하게 overlap된다. 이는 `__syncthreads()`를 호출해 올바른 동작을 유도할 수 있다.
- 다른 thread block들은 랜덤하게 overlap된다. 이들은 어떻게 synchronous하게 동작하게 유도할까? 가장 쉬운 방법은 작업이 끝나면 kernel을 종료하는 것이다.
CUDA Host Code에서 Synchronicity
- 모든 CUDA 호출은 host에 대해 synchronous 또는 asynchronous이다
- synchronous의 경우 : 작업을 대기열에 추가하고 끝날 때까지 기다린다.
- asynchronous의 경우 : 작업을 대기열에 추가하고 즉시 리턴한다.
- Default API의 경우
- CUDA kernel launch는 CPU와 asychronous이다. (non-blocking) host에서 kernel call을 해도 kernel이 끝날 때까지 다음 instruction을 실행하는 것을 보류하지 않는다.
- 대부분의 CUDA call은 synchronous / blocking이다. 예를 들어 `cudaMemcpy()`의 경우 복사가 끝날 때까지 기다린다.
- asynchronous한 버전의 API도 존재한다. 예를 들어 `cudaMemcpyAsync()`는 CPU와 asynchronous하다.
- asynchronous한 API를 호출한 경우, `cudaDeviceSynchronize()`를 호출해 완료를 기다리거나 `cudaMemcpy()`를 호출해야 한다.
CUDA Streams
CUDA Streams는 GPU에서 만들어진 순서대로 실행되는 operation sequence. host는 작업을 queue에 넣고, device는 resource를 쓸 수 있을 때 stream에 작업을 넣는다.
- stream을 사용해 여러 개의 CUDA operation을 동시에 할 수 있다. 때문에 concurrency와 pipelining을 실현하는 programming model이다.
- 종류는 크게 2가지, kernel launch와 data transfer이다.
- 또한 CPU에서 GPU로, GPU에서 CPU로 data를 옮기는 communication을 숨길 수 있다!
예시
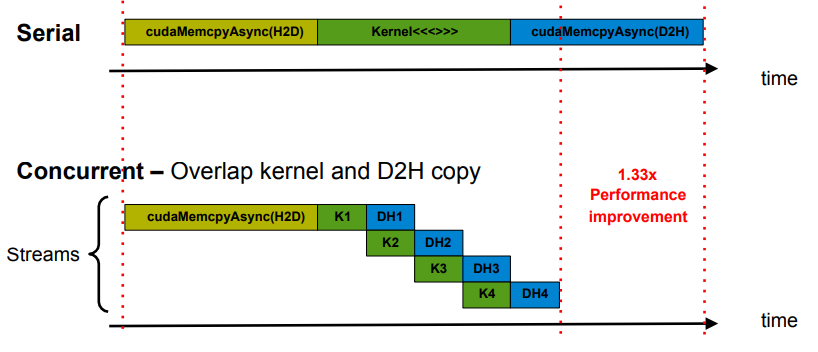
stream을 사용하면 위 예시와 같이 kernel launch와 data transfer를 겹칠 수 있다.
예시 : 코드
cudaSream_t stream; // Declaring the stream variable
cudaStreamCreate(&stream); // Creating the stream
// Assigning stream to kernel launch
myKernel<<grid, shmem, stream>>(args);
// Checking if the stream has finished
if (cudaStreamQuery(stream) == cudaSuccess) cout << “Finished”;
// Waiting for finalization
cudaStreamSynchronize(stream);
// Deallocating memory
cudaStreamDestory(stream);
Stream Semantics
- stream이 지정되지 않은 경우 기본값인 stream 0이 사용된다.
- 같은 stream에서 만들어진 두 연산은 만들어진 순서대로 실행된다. 예를 들어 operation A, operation B 순서대로 만들어졌다면 A가 끝날 때 까지 B는 실행되지 않는다.
- 서로 다른 stream에서 만들어진 두 연산은 순서 없이 실행된다.
- `cudaMemcpyAsync()`나 kernel launch를 stream으로 사용하는 것이 일반적이다.
Default Stream (stream 0)
- stream이 지정되지 않은 경우 사용되는 stream이다.
- default stream은 특별한 synchronization 규칙이 있다.
- host와 device에 대해 100% synchronous하다. 다른 stream에 대해서도 synchronous하다.
- `cudaDeviceSynchronize()`가 모든 CUDA operation 전후에 삽입된 것처럼 보인다.
- host에 대해서는 asynchronous하다.
- kernel은 default stream에서 실행된다. 만약 `cudaMemcpyAsync()`나 `cudaMemsetAsync()`를 호출하면 asynchronous하게 실행된다.
Concurrency의 요구사항
- CUDA operation은 0이 아닌 서로 다른 stream에 있어야 한다.
- `cudaMemcpyAsync()`는 host의 pinned memory와 사용되어야 한다.
- pinned memory는 page locked memory이며, page eviction이 발생하지 않는 memory에 고정된 page이다.
- `cudaMallocHost()`나 `cudaHostAlloc()`으로 할당할 수 있다.
- 충분한 resource를 사용할 수 있어야 한다.
- `cudaMemcpyAsync()`의 방향이 다르기 때문이다.
- 만약 SM, register, memory, block 등이 충분하지 않지 않다면 concurrency가 발생하지 않는다.
Pinned Memory
pinned memory는 GPU의 exclusive access를 위한 virtual memory page이며, CPU에 할당된다. pinned memory로 지정된 memory는 host virtual memory에서 제거되며, paging의 대상에서 벗어난다. (항상 on memory라고 생각하면 된다.)
- CPU나 GPU 사이에서 asynchronous하게 memcopy하며, host와 device copy보다 빠르다.
- direct memory access의 방식이기에 asynchronous하다.
사용 방법은 다음과 같다.
- `cudaHostAlloc()`과 `cudaFreeHost()`
- `cudaHostRegister()`과 `cudaHostUnregister()`
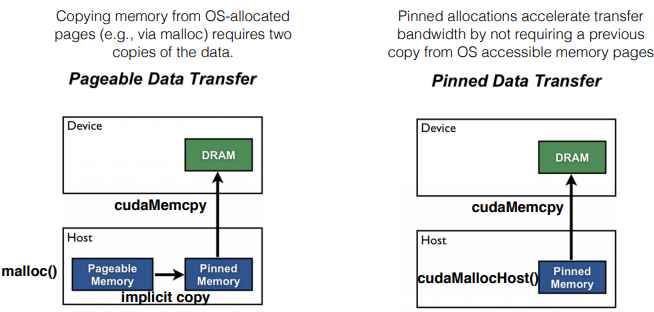
`cudaMemcpy()`와 같이 pinned memory로 할당하지 않는 data transfer는, pageable host memory에서 implicitly pinned memory로 이동한 후 device memory로 이동한다.
반면 pinned memory로 할당한 data transfer는 바로 device memory로 이동한다.
예시 : synchronous
cudaMalloc (&dev1, size);
double *host1 = (double *) malloc(&host1, size);
…
cudaMemcpy(dev, host1, size, H2D);
kernel2<<<grid, block, 0>>>(…, dev2, …);
kernel3<<<grid, block, 0>>>(…, dev3, …);
cudaMemcpy(host4, dev4, size, D2H);
...위 코드에서 `cudaMemcpy()` 2개 사이에 있는 kernel launch는 100% synchronous이다. default stream의 모든 CUDA operation끼리는 100% synchronous이기 때문이다. kernel launch는 host와 asynchronous이지만 default stream 내에서는 synchronous이다.
예시 : asynchronous
cudaMalloc (&dev1, size)
double *host1 = (double *) malloc(&host1, size);
…
cudaMemcpy(dev, host1, size, H2D);
kernel2<<<grid, block, 0>>>(…, dev2, …);
some_CPU_method();
kernel3<<<grid, block, 0<<<(…, dev3, …);
cudaMemcpy(host4, dev4, size, D2H);
…위 코드에서 `kernel2<<<grid, block, 0>>>()`과 `some_CPU_method()`는 겹칠 수 있다. GPU kernel launch는 host와 asynchronous이기 때문이다.
cudaStream_t stream1, stream2, stream3, stream4;
cudaStreamCreate(&stream1);
…
cudaMalloc(&dev1, size);
cudaMallocHost(&host1, size); // pinned memory required on host
…
cudaMemcpyAsync(dev1, host1, size, H2D, stream1);
Kernel2<<<grid, block, 0, stream2>>>(…, dev2, …);
Kernel3<<<grid, block, 0, stream3>>>(…, dev3, …);
cudaMemcpyAsync(host4, dev4, size, D2H, stream4);
some_CPU_method();
…다른 예시이다. 위 코드에서 `cudaMemcpyAsync()`부터 `some_CPU_method()`는 모두 겹칠 수 있다. `cudaMemcpyAsyn()`과 kernel launch에서 stream을 썼기 때문이다. `some_CPU_method()` 또한 겹칠 수 있다.
Explicit Synchronization
- 모든 것을 synchronize하고 싶을 때 : `cudaDeviceSynchronize()`로 실행할 수 있고, 모든 CUDA call이 완료될 때까지 host를 block한다.
- 특정 stream에 대해 synchronize하고 싶을 때 : `cudaStreamSynchronize()`로 실행할 수 있고, 모든 stream CUDA call이 완료될 때까지 host를 block한다.
- event를 사용해 synchronize하고 싶을 때 : stream 내부에서 event를 사용해 synchronize한다. `cudaEventRecord()`, `cudaEventSynchronize()`, `cudaStreamWaitEvent()`, `cudaEventQuery()` 등이 있다.
Implicit Synchronization
- 아래 작업들은 CUDA operation을 implicitly synchronize한다.
- paged locked memory allocation : `cudaMallocHost()`, `cudaHostAlloc()`
- device memory allocation : `cudaMalloc()`
- non async version of memory operation : `cudaMemcpy90`, `cudaMemset()`
- L1이나 shared memory로 변경 : `cudaDeviceSetCacheConfig()`
Stream Scheduling
GPU가 stream을 예약하는 방법. Computer Engine Queue, H2D Copy Engine Queue, D2H Copy Engine Queue 3개의 queue가 있다.
CUDA operation은 만들어진 순서대로 hardware에 전달되고, 그리고 관계 있는 queue에 배치된다. kernel launch는 computer engine queue에, memcpy는 관련된 queue에 들어가는 식이다.
- engine queue들끼리 stream dependency는 유지되지만, 각각의 engine queue에서는 dependency가 유지되지 않는다.
이후, 아래 조건을 만족할 때 engine queue에서 pop된다.
- 같은 stream의 이전 호출이 완료되었을 때
- 하나의 stream에는 kernel launch, host2device, device2host operation이 여러 개 있을 수 있다. 예를 들어 이 stream이 kernel launch - host2device - device2host 순서로 호출을 한다고 하자. device2host가 실행되기 위해서는 host2device의 실행이 끝나야 한다! 이런 의미다.
- 같은 queue에 있는 호출이 전달되었을 때 : 이건 작업 queue에서 순서가 왔을 때 실행할 수 있다는 의미이므로 직관적이다.
- resource를 사용할 수 있을 때
서로 다른 stream에 있는 CUDA kernel은 concurrent하게 실행될 수 있다.
- 주어진 kernel의 thread block은 이전 kernel에 대한 모든 thread block이 예약되었거나, 아직 사용할 수 있는 SM resource가 있을 때 schedule된다.
- 참고로, blocked operation은 같은 queue의 다른 모든 operation을 block한다.
예시
- synchronous : `cudaMemcpy()`
- 같은 stream일 때 asynchronous : `cudaMemcpyAsync(..., stream1)`로 memory를 옮기고 `foo<<<..., stream1>>>()`로 kernel launch한다.
- 다른 stream일 때 asynchronous : `cudaMemcpyAsync(..., stream1)`로 memory를 옮기고 `foo<<<..., stream2>>>()`로 kernel launch한다.
예시 : Blocked Queue
2개의 stream이 있다고 하자. stream 1은 HDa1, HDb2, K1, DH1 순서고, stream 2는 DH2 작업이 있다고 하자.

stream 1이 먼저 만들어진 경우 execution은 오른쪽 그림과 같다.
queue는 dependency를 관리하지 않기에, queue의 signal이 synchronization을 만든다. 각 stream의 CUDA operation은 아래 조건을 만족할 때 실행된다.
이후, 아래 조건을 만족할 때 engine queue에서 pop된다.
- 같은 stream의 이전 호출이 완료되었을 때
- 같은 queue에 있는 호출이 전달되었을 때
- resource를 사용할 수 있을 때
때문에 stream 1이 모두 실행된 후 stream 2의 DH2가 실행된다.
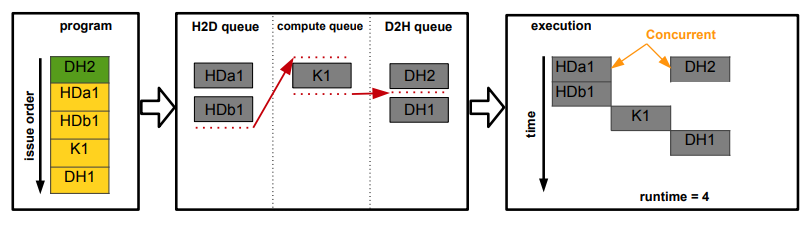
반면 stream 2가 먼저 만들어진 경우 실행은 위와 같다.
stream 2의 DH2가 실행되고, 동시에 steam 1의 HDa1은 이전 호출이 없고, H2D queue도 비었고, 작업을 사용할 수 있으므로 HDa1을 실행한다.
때문에 stream 1의 HDa1과 stream 2의 DH2가 concurrrent하게 실행된다.
예시 : 다른 blocked kernel
만약 두 stream이 CUDA kernel을 호출하기만 한다고 하자. 그러면 stream 1은 Ka1, Kb1이고 Stream 2는 Ka2, Kb2이다.
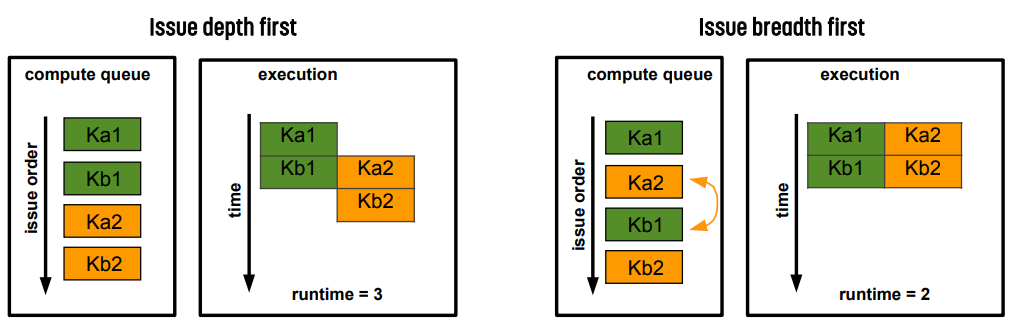
이 때 kernel이 작아서 SM의 절반을 채울 수 있다고 하자. 그러면 depth부터 먼저 적용하면 runtime은 3이고, breath를 먼저 적용하면 runtime은 2가 된다.
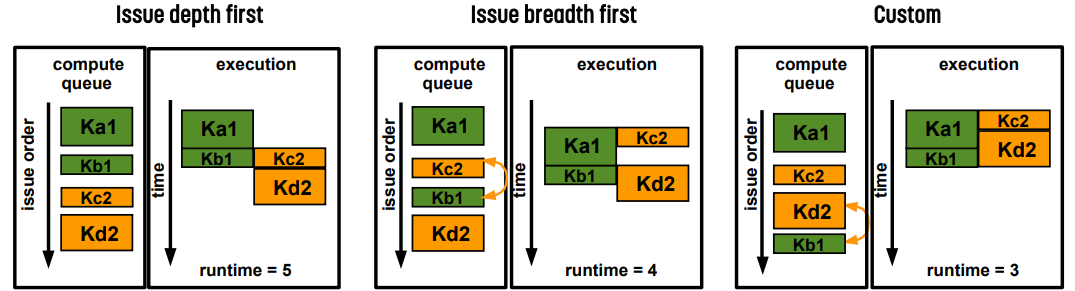
반면 각 kernel의 크기가 다른 경우 위와 같다. depth를 우선순위로 두면 runtime은 5, breath를 우선순위로 두면 runtime은 4가 된다. 개발자가 적당히 잘 조절하면 3까지도 줄일 수 있다.
Concurrency Guideline
- cost가 높은 GPU 작업을 pipelining하기 위해 CUDA stream과 asynchronous API를 사용한다.
- issue order에 따라 실행 결과가 크게 달라지기 때문에 주의해야 한다.
- concurrrency를 깨뜨릴 수 있는 resource와 operation에 주의해야 한다.
Thead Synchronization
Synchronizing Threads
- grid level collective synchronization : global memory를 통해 서로 다른 thread block끼리 communication과 synchronization을 한다.
- block level collective synchronization : shared memory를 사용해 thread block끼리 communication과 synchronization을 한다.
- warp level collective synchronization : warp level primitive를 사용하면 warp 내의 thread끼리 register를 사용해서 direct communication을 할 수 있다.
- fine grained synchronization :
- 만약 2개 이상의 thread가 동시에 같은 shared memory에 접근하고, 하나 이상의 thread가 write operation을 수행할 때 race condition이 발생한다.
- synchronization하지 않는다면 update가 사라지게 되므로 예측할 수 없는 동작이 발생한다.
- non-deterministic fine grained communication의 경우 kernel launch나 barrier가 동작하지 않는다.
Warp Level Synchronization

`__syncwarp()` : warp 내의 thread를 synchronize하는 데 사용하는 함수로, parameter로 넣은 mask에 해당하는 모든 wap 내의 thread가 `__syncwarp()`를 호출할 때까지 기다린다.
Atomics
필요성
제일 일반적인 문제는 shared data에 read-modify-write를 할 때 race condition이 발생한다는 것이다. 특히 transaction이나 data access에 대해! 이를 위해 data aggregation과 enumeration을 한다.
Atomic Operation
CUDA는 여러 thread에서 접근하는 shared variable에 대한 atomic function을 제공한다. 이는 다른 thread의 중단 없이 memory를 atomic하게 수정하는 방식으로 동작한다.
이를 통해 동시에 만들어진 atomic update가 수행되고, 모든 thread가 update 결과를 볼 수 있다는 것을 보장한다.
- access는 serialize되어 한 번에 하나의 thread만 접근하고 나머지는 대기하는 방식이다.
CUDA에서 Atomic Operation
- 단일 instruction으로 변환되는 function를 호출해 쓸 수 있다. `atomicAdd()`, `atomicSub()`, ... 등등이 있다.
- 예를 들어 `atomicAdd()`의 경우 원래 global/shared memory에 있는 값을 읽고, 거이에 값을 더하고 저장한다.
Atomic의 성능 효과
- atomics는 일반적인 memory load/store보다는 느리다.
- shared memory에 있는 변수에 대해서는 빠르지만 global memory에 있는 변수에 대해서는 느리다.
- 많은 thread가 몇몇 작은 위치에 atomic operation을 사용할 경우 성능 저하가 있을 수 있다.
- 더 많은 parallelism과 locality를 만들기 위해 hierarchy를 만든다.
- 가능할 때마다 synchronization을 피하기 위한 자료구조가 필요하다.
잘못된 내용이나 오탈자에 대한 지적, 질문 등은 언제나 환영합니다.