[이종병렬컴퓨팅] Parallel Patterns : Histogram
이 글은 포스텍 성효진 교수님의 이종병렬컴퓨팅(CSED490C) 강의를 기반으로 재구성한 것입니다.
이 글에서는 다음과 같은 내용들을 살펴본다.
- parallel한 histogram 계산 패턴
- privatization
Histogram
histogram은 큰 data set에서 특징과 패턴을 추출하는 방법으로, 기본적으로는 dataset의 각 bin 요소에 대해 count를 증가하는 방법이다. 제일 기본적인 병렬 알고리즘은 아래와 같다.
- input을 section으로 나누기
- 각 thread는 하나의 section을 담당한다.
- 각 thread는 section에서 순회한다.
- 각 letter에 대해 bin counter를 증가시킨다.
효율적인 memory 접근을 위한 partitioning 방법
section을 나누는 방법이 memory access 효율에 영향을 미친다.
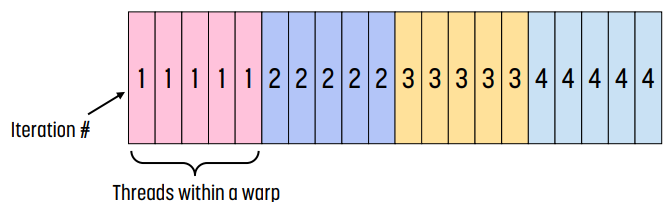

위 그림에서 각 숫자는 thread가 어떤 element에 어떤 thread가 접근하는지를 나타낸다.
왼쪽 그림은 sectioned partitioning인데, 이 경우 각 thread의 memory access가 coalesce되지 않기 때문에 효율적이지 않다. 각 thread의 첫 실행에서 thread 1은 index 0에, thread 1은 index 5에, thread 2는 index 9에, ... 이런 방식으로 접근하기 때문에 memory access가 coalesce된다.
오른쪽 그림은 interleaved partitioning인데, 이 경우 모든 thread가 연속된 section의 element에 접근하기 때문에 memory access가 coalesce되어 더 효율적이다.
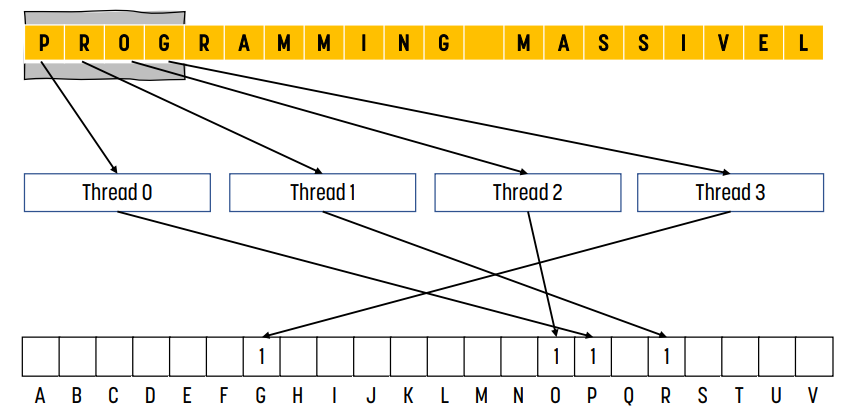
예시 : sectioned partitioning


위 그림은 `PROGRAMMING MASSIVEL`이라는 글자를 5개씩 section으로 나누고, 4개의 thread가 parallel하게 histogram을 count하는 것을 보여준다.
왼쪽 / 오른쪽 그림에서 각 thread는 각 section의 첫 번째 글자에 해당하는 bin counter를 1 증가시킨다.
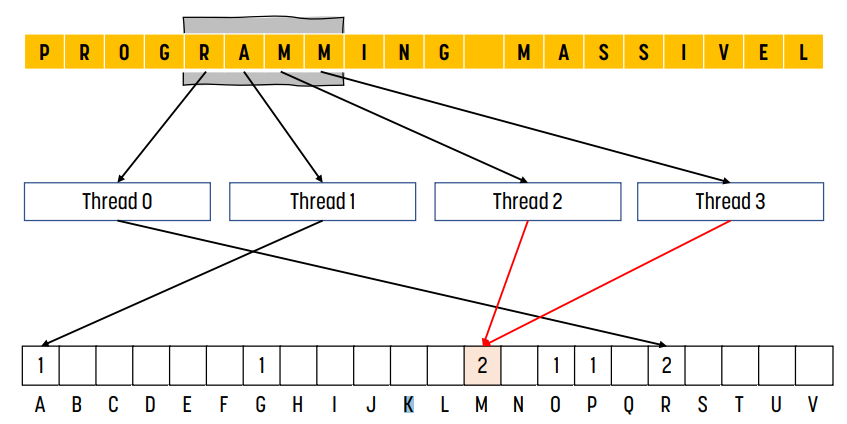
오른쪽 그림은 2개의 thread가 같은 bin counter에 접근할 때 발생하는 문제를 보여준다. 이 경우, 두 thread가 접근하는 bin counter 모두 정상적으로 증가해야 한다.
예시 : interleaved partitioning
위 그림은 interleaved partitioning 예시이다. sectioned partitioning과 다르게 하나의 iteration에서 모든 thread가 비슷한 memory에 있는 값을 참조하기 때문에 memory coalescing이 일어나며, 따라서 memory bandwidth를 더 효율적으로 사용할 수 있다.
마찬가지로 오른쪽 그림의 경우 2개의 thread가 같은 bin counter에 접근할 때 문제점을 보여준다. 이를 해결하기 위해 read-modify-write operation을 사용한다.
Atomic Operation (Read-Modify-Write)
동일한 memory 위치에 대해 2개 이상의 thread가 접근할 때 data race가 발생한다. 이 경우 값을 쓰는 과정이 non-deterministic하기 때문에 결과가 어떻게 될지 보장할 수 없다. 이를 막기 위해 `atomicAdd()`를 사용한다.
이를 적용한 CUDA histogram 코드는 다음과 같다. (interleaved partitioning 버전이다)
__global__ void histo_kernel(unsigned char *buffer, long size, unsigned int *histo) {
int i = blockIdx.x * blockDim.x + threadIdx.x;
int stride = blockDim.x; // stride는 thread의 총 개수이다.
// 모든 thread는 blockDim.x * gridDim.x개의 연속적인 element를 처리한다.
while (i < size) {
atomicAdd(&(histo[buffer[i]]), 1);
i += stride;
}
}
Atomic Operation 성능

DRAM에서 atomic operation의 경우, 각 read-modify-write 연산은 2번의 full memory access delay(read latency, write latency)를 가진다. 이는 하나의 thread가 atomic하게 특정 위치에 값을 썼을 때 다른 모든 thread들이 해당 위치의 변경된 값을 확인할 수 있어야 하기 때문이다.
또한 동일한 memory location에 대한 모든 atomic operation은 serialize된다. 하나의 thread가 atomic operation으로 하나의 memory에 접근하고 있을 때, 다른 thread는 해당 위치에 접근할 수 없다는 말이다.
Latency가 Throughput을 결정한다.
같은 DRAM 위치에 대한 atomic operation throughput은 프로그램이 atomic operation을 실행하는 속도와 동일하다. 따라서 특정 위치에 대한 atomic operation의 비율은 read-modify-write 연산의 latency에 의해 한정된다. 일반적으로 global memory의 경우 1000 cycle보다 더 크다.
즉, 많은 thread가 같은 memory location에 대해 atomic operation을 수행해 contention이 발생한다면, memory throughput은 최대 bandwidth의 1/1000배 이하로 감소한다.
Hardware Improvement
L2 cache에서 atomic operation 수행
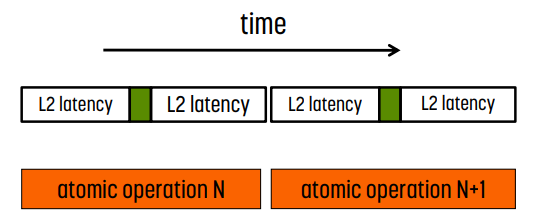
atomic operation을 L2 cache에서 수행하는 것이다. 이 경우 latency가 더 줄어들게 된다. 그렇지만 여전히 serialize된다.
Shared Memory에서 atomic operation 수행
atomic operation을 shared memory에서 수행하면 latency가 매우 줄어든다. 반면 각 work group에 private하게 만들어지므로 코드를 좀 더 짜야 한다는 단점이 있다.
Privatization
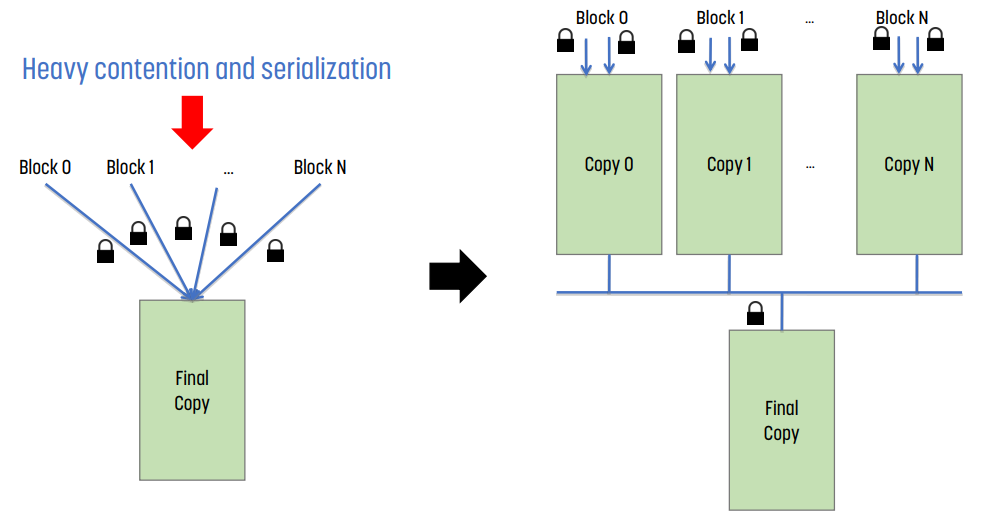
여러 개의 thread block이 하나의 memory에 접근하는 경우, contention과 serialization이 계속 발생한다. 이를 막기 위해 1) 각 thread block은 private copy를 가지고, 2) 이들을 통합해 final copy을 만드는 것이 privatization이다. 이를 통해 contention과 serialization을 줄일 수 있다.
장단점
- overhead : privatization의 경우 추가적인 overhead는 private copy를 만드는 것, 그리고 private copy를 합쳐 final copy를 만드는 것이 overhead이다.
- 장점 : final copy의 접근에 대한 contention과 serialization을 훨씬 줄일 수 있기 때문에 전체적인 성능은 약 10배 이상 향상된다.
Histogram의 Shared Memory Atomic Operation
하나의 thread block에는 여러 개의 thread가 있고, shared memory는 이들 사이에서 공유되는 memory이다.
이 때 shared memory에서 atomic operation을 수행할 때 DRAM보다 100배, L2 cache보다는 약 10배 정도 더 높은 throughput을 뽑아낼 수 있다. 또한 shared memory variable에 접근할 수 있는 것은 같은 thread block의 thread뿐이기 때문 에 contention도 더 적다.
Privatization과 Shared Memory Atomic
shared memory에서 atomic operation을 적용해 privatization을 구현한 CUDA histogram 코드는 다음과 같다.
__global__ void histo_kernel(unsigned char *buffer, long size, unsigned int *histo) {
int tid = threadIdx.x;
__shared__ unsigned int histo_private[256]; // number of bins = 256
if (tid < 256)
histo_private[tid] = 0;
__syncthreads(); // 초기화가 끝날 때까지 대기한다.
int i = blockIdx.x * blockDim.x + threadIdx.x;
int stride = blockDim.x; // stirde는 thread의 개수
while (i < size) {
atomicAdd ( &(private_histo[buffer[i]), 1); // shared memory에 접근
i += stride;
}
__syncthreads(); // thread block의 모든 thread의 작업이 끝날 때까지 대기한다.
// 이후 final copy에 추가한다.
if (tid < 256){
atomicAdd( &(histo[tid]), private_histo[tid] );
}
}
Privatization에 대한 추가 정보
- privatization은 병렬화하기 위해 자주 사용되는 강력한 기술이다.
- 이 때 privatization을 적용하기 위해, operation은 associative(결합)하고 commutative(교환) 가능해야 한다. 그래야만 private copy를 합쳐도 결과가 동일하기 때문이다.
- histogram add operation의 경우 associative & commutative하기 때문에 privatization을 적용할 수 있다. 만약 그렇지 않은 연산에 대해서는 privatization을 적용할 수 없다.
- 또한, shared memory의 크기는 작기 때문에 private histogram의 크기는 작아야만 한다.
- 만약 histogram이 privatize하기에 너무 크다면, output histogram을 부분적으로 privatize하고, range test를 사용해 global/shared memory로 이동하면 된다.
- shared atomics는, 일반적으로 global atomics보다 2배 이상 더 빠르다.
잘못된 내용이나 오탈자에 대한 지적, 질문 등은 언제나 환영합니다.