[이종병렬컴퓨팅] Heterogeneous Parallel Computer를 위한 기술 스택
이 글은 포스텍 성효진 교수님의 이종병렬컴퓨팅(CSED490C) 강의를 기반으로 재구성한 것입니다.
이 글에서는 이종 시스템을 위한 고수준 프로그래밍을 가능하게 하는 software stack에 대해 설명한다. compiler-based, library-based, framework-based로 나눠 설명하고, OpenCL에 대한 compile/runtime 지원을 살펴본다.
Compiler란?
compiler는 source code를 기계어로 번역하는 일을 한다.
- source code는 high level abstraction, low level detail을 숨긴다. 떄문에 알고리즘에 대한 이해가 쉽고, fine-grained performance tuning이 제한된다.
- 기계어는 코드를 짜고 유지보수하기 어렵지만, 성능을 직접적으로 제어할 수 있다.
compiler는 lexical analysis, syntatic analysis, semantic analysis, IR generation, IR optimization, code generation, code optimization의 과정을 거쳐 기계어를 생성한다.
더 깊은 software stack에 대한 동기
언제, 그리고 왜 abstraction layer를 사용할 수 있을까? 크게 3가지가 있다. detail을 숨기고 싶을 때는 programmability를, 최적화된 기능을 제공하고 싶을 땐 performance를, portable code를 작성하고 싶을 땐 portability이다.
그러나 이것은 heterogeneous system을 위한 것일까? CPU와 GPU는 서로 다른 contraint와 기능을 가지고 있기에 설계가 복잡하고, 때문에 성능을 추정하기 어렵다.
General Purpose Compiler

Application Programming Interface: API
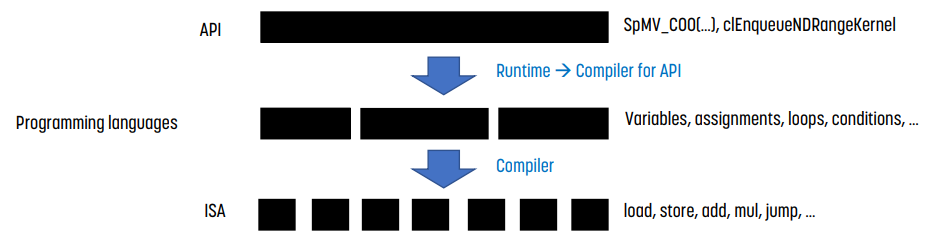
software 객체 간의 상호작용을 정의하는 library 기반 interface이다. 이를 통해 기본 구현을 추상화하고, 개발자가 필요로 하는 객체나 동작만 노출시켜 programming을 간단하게 만든다. 언어에서 만든 추가적인 abstraction layer라고 생각하면 된다.
Domain Specific Language

domain specific language는 특정 domain에 대한 더 높은 abstraction을 제공한다.
맞춤형 추상화라고 불리우며, 이를 통해 domain 전문가들에 대한 접근성과 신뢰성을 향상시킬 수 있다. 코드가 더 짧아지고 compiler는 정해진 boilerplate code를 생성하기 때문이다. 또한 표현력을 일부 제한해서 domain 수준에서 유효성을 검사하고 최적화를 할 수 있다.
Library와의 비교
복잡한 libaray는 사용하기 어려울 수 있다. type checking은 host language level에서만 사용할 수 있다. domain 지식을 활용하거나 여러 artifact를 생성하기 더 어렵다.
Framework

framework는 프로그램을 구축하고 배포하는 표준 방식을 사용해 개발을 용이하게 한다. compiler, code library, toolset, API, 개발환경, 테스팅 환경, 실행환경 등이 포함된다.
framework는 domain specific language 그 이상의 구현이다. 다양한 engineering 장점들을 제공한다.
- modularity : 다른 시스템이 작업을 수행하는 방식에 대한 자유로운 모듈
- extensibility : 작업의 실행과 구현이 분리된다.
- flexbility : 언어가 부여한 구조나 규칙이 없다.
- development support : 개발/디버그 환경이나 utility 등 프로그램이 있다.
Inversion of Control: IoC

기존 코드에서는 사용자가 모든 library를 호출한다. 그러나 framework는 framework가 사용자가 작성한 코드를 호출한다. 때문에 dependency의 책임을 higher-level code에게 전가한다.
HPC를 위한 software stack



왼쪽은 host를 직접 짜는 경우이다. 이 경우 구현이 더 투명해지며, 실행 동작을 직접 관리할 수 있고 platform에 indepdent하게 동작할 수 있다.
오른쪽은 framework에서 짜는 경우이다. framework는 scheduling과 mapping을 제어해 높은 runtime flexibility와 시스템 전반적인 최적화를 제공한다.
AMD ROCm
- GPU 가속화된 HPC, 과학 계산, CAD를 위해 디자인되었다.
- 모듈로 나누고, 최소한의 소프트웨어 개발
- framework, library, driver, programming model, linux kernel support로 구성되었다.
- 성능이나 확장성에 최적화되어 있다.
- 특히 ROCm 5.6의 경우 LLM을 위한 최적화된 library를 제공한다.
Intel OneAPI
- heterogeneous processing architecture를 위한 프로그램 개발을 위한 통일되고 간소화된 프로그래밍 모델을 위한 industry
- Intel Xeon이나 Core processor, Intel FPGA를 목표로 한다.
- 기존 AI나 HPC 프로그래밍 모델과 호환된다.
NVICIDA CUDA와 CUDA-X
- 고성능 AI 및 HPC를 위한 library와 도구의 collection.
GPU library
CUDA library
- CUDA math library
- exponential, logarithmic, trrigonometric, hyperbolic, vector norm 등 기본적인 수학 함수를 지원한다.
- cuBLAS
- dense matrix를 위한 선형대수 subroutine 지원
- matrix-vector나 matrix-matrix 곱셈 지원
- user kernel에서 cuBLAS 호출 가능. (device API이다.)
- CUDA stream 지원
- cuBLASxt는 multiple GPU도 지원한다.
- cuFFT
- 1D, 2D, 3D FFT
- cuBLAS와 유사하게 user host code에서 호출된다.
- batch로 독맂벅인 변환을 수행하는 기능을 지원한다. 예를 들어 3D dataset에서 1D transform 등
- cuTENSOR
- tensor 선형대수 library
- 새로운 tensor core를 활용한다.
- cuSPARSE
- sparse matrix를 위한 작업 지원
- sparse matrix-vector와 matrix-matrix 곱셈 포함
- cuRAND
- 난수 생성
- cuSOLVER
- cuBLAS나 cuSPARSE library를 기반으로 한 고수준 package
- LAPACK dense solver를 제공하며, Intel MKL보다 3-6배 빠르다. sparse direct solver는 CPU보다 2-14배 빠르다.
- 최신 버전은 low-precision tensor core 연산을 사용한다.
- CUTLASS (CUDA Template for Linear Algebra Subroutines)
- GEMM 행렬 곱을 구현하기 위한 CUDA C++ 템플릿 추상화 collection
- cuDNN
- deep neural network를 위한 library
- nvGraph
- 그래프 분석 library
- page rank, single source shortest path, single source widest path 등을 지원한다.
- NPP (NVIDIA Performance Primitive)
- imaging이나 video 처리를 위한 library
- filtering, JPEG decoding 등을 지원한다.
- NCCL
- NVIDIA GPU 및 네트워킹에 최적화된 multi GPU 및 multi node 통신을 구현한다.
- all-gather, all-reduce, broadcase, reduce, reduce-scatter, P2P 등 지원
- Thrust
- C++ STL 기반 interface를 갖는 고수준 C++ template library
- 사용자는 CUDA 코드 없이 표준 C++ 코드를 작성하지만 GPU 병렬화의 이점을 가질 수 있다.
- x86도 지원한다.
- memory 관리나 data movement를 간소화한다.
AMD ROCc Library
- AMD의 ROCm 런타임 및 toolchain에서 매우 유사한 library set을 제공한다.
- HIP 프로그래밍 언어로 구현되어 AMD GPU에 최적화되어 있다.
- rocBLAS, rocFFT, rocSPARSE, RCCL 등이있다.
- hipBLAS나 hipSPARSE는 backend를 지원하는 marshalling library이다.
- rocThrust는 thrust를 위한 HIP backend이다.
잘못된 내용이나 오탈자에 대한 지적, 질문 등은 언제나 환영합니다.