[이종병렬컴퓨팅] GPU architectures - SIMT와 SIMD
이 글은 포스텍 성효진 교수님의 이종병렬컴퓨팅(CSED490C) 강의를 기반으로 재구성한 것입니다.
이 글에서는 다음과 같은 내용들을 살핀다.
- GPU의 실행 모델인 SIMT와 SIMD
Heterogeneous Computing
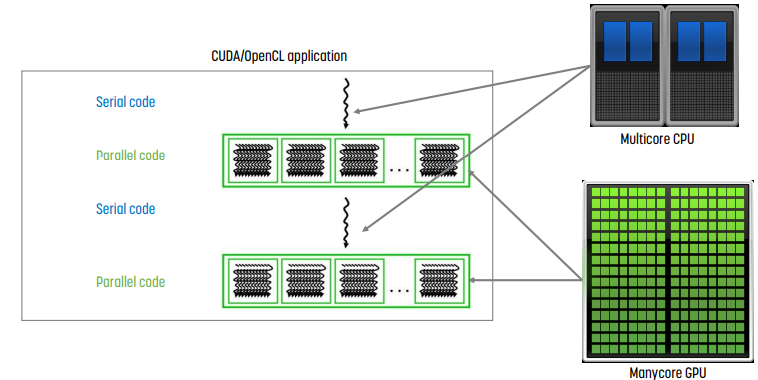
순서가 있는 instruction은 CPU에, parallel하게 돌릴 수 있는 instruction은 GPU에 할당해서 돌리는 것이 heterogeneous computing이다.
GPU Architecture의 개요
CPU vs GPU
CPU는 하나의 thread에서 발생하는 latency를 최소화하는 데 목적이 있으며, 때문에 cache가 매우 크다. 따라서 일반적으로 core의 개수가 적으며, 여러 종류의 instruction을 수행할 수 있는 general한 목적이다.
GPU는 모든 thread의 throughput을 최대화하는 것이 목적이며, multithreading으로 인해 latency를 숨길 수 있다. 따라서 또한 core가 수행하는 연산이 더 간단하기 때문에 core의 개수가 매우 많으며, cache의 크기가 작다.
CPU는 훨씬 복잡하고, latency가 훨씬 적다. 반면 GPU는 훨씬 작고 간단하지만 훨씬 많은 core가 있다.
GPU는 어떻게 높은 성능을 내는가?
GPU는 graphics processing unit인 만큼, 동일한 작업을 계속 수행하므로 parallel하게 구성한다.


CPU와 비교했을 때 나타나는 이러한 GPU의 효율성은 control overhead를 최소화하는 데서 나온다.
여기서 control overhead란 flow of control에서 발생하는 overhead이다. 기본적으로 instruction을 fetch하고 어떤 instruction을 실행할지 결정하는 것이 flow of control이다.
CPU는 모든 context에 별개의 program counter가 있으며, 하나의 core에서도 context가 여러 개 있기도 하다. 반면 GPU는 여러 개의 core를 그룹화하기 때문에 core 각각의 program counter가 없다. 한 group은 program counter 나 call stack 등의 정보를 공유하는 방식을 통해 각 group을 한 번에 관리한다.
GPU의 모든 core는 여러 개의 thread를 independent하게 실행해야 하므로 자체적인 control logic이 필요한데, 여기서 GPU는 core들끼리 이 control logic을 공유하는 방식을 택한다. (때문에 모든 thread가 program counter 나 stack pointer를 공유한다.) 이것이 GPU의 핵심 실행 모델이며, 본질적으로는 hardward가 실행하는 SIMD 방식이다. 이러한 방식으로 control overhead를 최소화한다.
이렇게 하나의 그룹으로 묶인 thread set을 warp라고 한다. warp의 모든 thread set은 동일한 instruction을 실행하고, SIMD 작업이지만 GPU scheduler가 수행한다.
SIMD, Single Instruction Multiple Data

여러 개의 data, 일반적으로 vector에 대해 하나의 instruction을 수행하는 것을 말한다. 오직 하나의 instruction으로 여러 개의 data를 처리할 수 있다. 이 경우, programming model과 execution model 모두 SIMD로 작동한다.
SIMD를 사용하기 위해서는 SIMD가 작동할 때 한 번에 몇 개의 data를 처리할지에 대한 지표인 width를 알고 있어야 한다.
예를 들어 width를 512로 설정하면, instruction 하나로 512개의 data를 처리할 수 있는 것이 vector instruction - SIMD이다.
기본적으로 GPU 내부는 SIMD로 구현되어 있다. program counter를 공유하는 같은 core에 대해 같은 instruction이 실행하기 때문에, SIMD처럼 작동해야만 한다. 그렇지만 programming model이 SIMD가 아니기 때문에 프로그램에서 vector instruction을 볼 수 없고, 일반적은 parallel program처럼 thread로 작성한다. - 즉, GPU의 프로그래밍 모델(software)과 실행 모델(hardware)이 분리되어 있다.
Programming Model vs Hardware Execution Model
- programming model : 프로그래머가 코드를 작성하는 방식이다. 예를 들어 sequential, data parallel, dataflow, multi thread 등이 있다.
- execution model : hardward가 실제로 코드를 실행하는 방식이다. out of order execution, vector processor, multiprocessor 등이 있다.
- 이 둘은 다른 것이기 때문에, 둘이 지향하는 패러다임에서 매우 큰 차이가 날 수 있다. 예를 들어 programming model은 sequential이지만 execution model이 out or order일 수도 있다.
GPU : SPMD 프로그래밍 모델과 SIMD 실행 모델
SPMD, Single Program Multiple Data
때문에, GPU는 GPMD programming model과 SIMD execution model이라 불리기도 한다.
SPMD의 작명에서 알 수 있듯 하나의 프로그램이 여러 개의 data를 돌리는 방식이다. SPMD는 programming model이며, MIMD의 subclass로 좀 더 제약이 걸린 버전이다.
각 thread는 같은 kernel을 수행하지만, data의 다른 부분을 실행한다. 각 thread는 각각의 context가 있으며, 때문에 독립적으로 동작한다. 각 program은 서로 다른 control flow path를 가질 수 있다. 이러한 동작은 불필요한 overhead를 없애기 때문에 더 빨리 동작한다.
SIMT, Single Instruction Multiple Thread
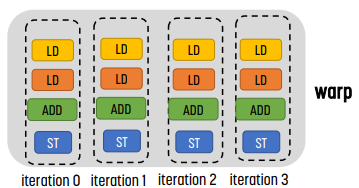
코드를 작성하는 단계에서는 single instruction을 사용하지만 실제로 실행되는 방식은 mulitple thread인 형식이다. 이 때 instruction은 vector instruction이 아니라, scalar instruction이다! 한편 thread들은 warp라는, 동적으로 형성된 group으로 묶이며, 각 thread는 scalar instruction을 사용한다. hardware가 warp를 그룹화하며, 각 warp는 동일한 instruction을 실행한다.
warp의 크기는 하드코드된 값을 사용한다. 예를 들어 32라고 설정하면 총 32개의 thread를 하나의 warp에 넣고, 64라고 설정하면 64개의 thread를 하나의 warp에 넣는다.
만약 너무 작은 숫자를 사용한다면 SIMD exeuction engine을 사용하는 이점이 사라진다. 반면 너무 큰 숫자를 사용하면 해당 warp를 채우기 힘들뿐더러 가장자리 부분에 cache miss가 날 수 있다. 따라서 이러한 경우를 모두 고려해 memory를 효율적으로 사용할 수 있는 숫자를 사용해야만 한다. 지금은 일반적으로 32를 쓴다.
SIMD vs SIMT
- SIMD : 하나의 instruction이 여러 개의 data를 처리하는 방식이다. 예를 들어 VLD, VLD, VADD, VST, VLEN 등이 있다. vector length를 알고 있어야 한다.
- SIMT : scalar instruction의 multiple instruction stream이다. 같은 명령어를 동시에 실행하는 여러 개의 thread가 hardward에 의해 warp로 묶인 것이다. 예를 들어 LD, LD, ADD, ST, NumThreads 등이 있다.
- SIMD의 경우 single thread이다.
SIMT는 크게 2가지 장점이 있는데,
- SIMT는 multi thread이므로 thread를 개별적으로 처리할 수 있다. 즉, 각 thread가 독립적으로 실행할 수 있기 때문에 MIMD processing을 할 수 있다.
- thread를 동적으로 warp로 묶을 수 있다. 즉, 동일한 instruction을 실행해야 하는 thread를 warp로 묶어 SIMD processing의 이점을 최대화할 수 있다.
Warp와 Warp-Level FGMT
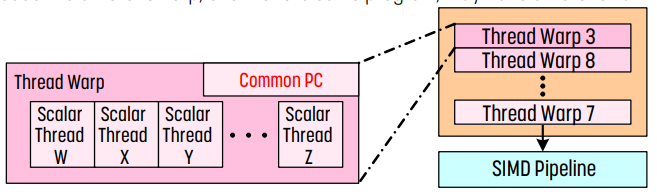
warp의 각 thread는 program counter , call stack을 공유하고, register만 다른 값을 가진다. 따라서 같은 프로그램이더라도 다른 warp는 다른 program counter 를 가질 수 있다.
일반적으로 GPU는 매우 큰 register를 가지며, 이를 적당히 나눠 각 thread에게 제공한다.
위 그림의 오른쪽은 SIMD pipeline을 의미하는데, 여기에는 실행할 준비가 끝난 warp들이 들어가며 여기서 실행하기로 한 warp가 SIMD pipeline에 들어간다.
High Level View of GPU
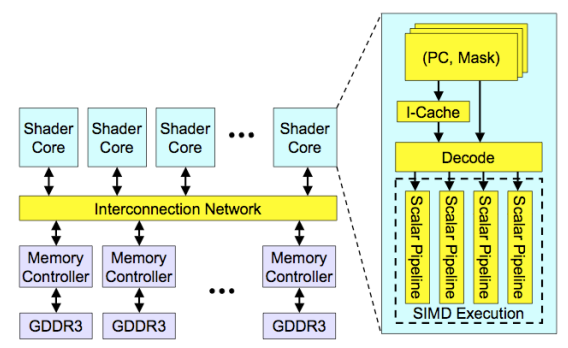
- sharder core는 앞에서 설명한 core라 받아들이면 된다.
- 각 core에는 scalar pipeline이 있으며, SIMD execution이 일어나는 곳이다.
- PC, mask는 warp의 실행 정보가 담기는 부분이다. PC는 program counter이고, warp가 같은 program counter를 공유하므로 필요하다. mask의 경우 warp의 thread가 분기로 인해 다른 warp로 바뀔 때 적용하는 값이다. mask를 사용해 다른 program counter를 실행하는 warp를 묶는다.
- 아래쪽의 GDDR3는 GPU memory를 의미하는데, NVIDIA나 AMD GPU는 GPU 내부의 memory, GPU memory 또는 device memory가 있다. ARM GPU의 경우 CPU와 RAM을 공유하기도 한다.
Latency Hiding with Warp Level FGMT
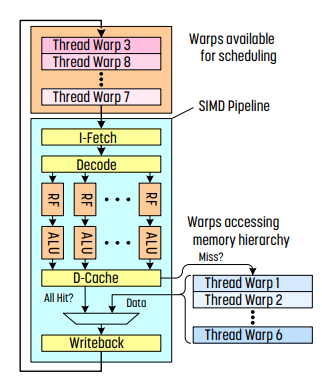
- 제일 윗부분은 hardware scheduler가 있는 부분이다. 실행할 준비가 된 warp들이 들어간다.
- 이후 SIMD pipeline에서는 하나의 warp를 실행한다.
- SIMD pipeline을 보면 fetch, decode는 하나만 있고, ALU만 여러 개가 있다. - 즉 하나의 instruction을 thread끼리 공유한다는 뜻이다. (SIMD)
- cache miss가 있는 경우 memory를 확인해야 하는데, 값을 가져오기 위해 context switch를 한다. 이 context switch의 경우 CPU와는 조금 다르다. CPU의 경우 PC, register, stack pointer 등을 저장하고 context switch를 한다. 반면 GPU의 경우 모든 thread가 크기가 큰 개인용 register를 가지기 때문에 여기다가 PC, register, stack pointer 등을 저장하므로 값을 저장하고 꺼내오는 데에 대한 overhead가 매우 적고, 따라서 warp의 실행을 잠시 보류하기만 한다.
fine-grained multithreading을 사용하기 때문에 매 cycle마다 hardward scheduler가 서로 다른 warp로부터 instruction을 수행한다. 이 과정은 interlocking이 없이, pipeline에 있는 thread마다 하나의 instruction을 실행한다는 것이다. context switch를 할 때, 모든 thread의 register 값들은 register file에 저장되며, context switching overhead가 매우 낮기 때문에 I/O를 기다리는 warp를 hardware scheduler가 scheduling하기만 하면 되는 이 효과로 인해 latency가 숨겨진다. 따라서 FGMT는 긴 latency를 허용한다.
Warp Instruction Level Parallelism
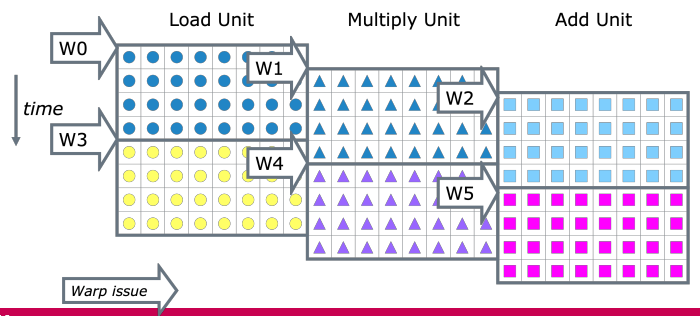
여러 개의 instruction을 겹칠 수 있다.
위 그림은 warp당 32개의 thread가 있고, 8개의 core이 있는 상황이다. 이 경우 각 core는 한 cycle에 8개의 thread만 처리할 수 있으므로, 각 warp가 처리되기 위해서는 4 cycle이 필요하다.
위 예시에서는 load, multiply, add unit 3가지로 나뉘어 있는데, 때문에 동시에 3개의 unit을 처리할 수 있다. 즉 cycle당 24개의 operation을 수행할 수 있게 된다.
Control Flow Problem in GPU
같은 warp에 있는 모든 thread는 같은 program counter를 실행한다. 그러나 branch를 만나 조건이 다르면 다른 program counter를 가지게 된다. 때문에 branch divergence - 다른 실행 경로를 가지는 문제가 발생한다.

이를 해결하기 위해 mask를 사용하며, mask를 사용해 다른 branch로 들어간 thread들을 묶을 수 있다.
위 예시에서 branch를 기준으로 실행하는 thread가 달라진 모습이다. 몇몇 thread는 path A로, 몇몇 thread는 path B로 간다. path A로 간 thread들은 1로 mask하고, path B로 간 thread들은 0으로 mask한다. 이후 branch가 끝난 후 converge하는 방식으로 branch divergence 문제를 해결한다.
이러한 방식으로 같은 instruction을 실행하는 thread를 동적으로 warp로 묶으며, 이를 통해 낭비되는 cycle을 줄여 SIMD process의 이점을 최대화한다.
정리
중요한 점: 각 thread는 independent이다!
SIMT는 2가지 장점이 있다.
- 각 thread를 독립적으로 처리할 수 있다.
- thread를 warp로 유동적으로 묶을 수 있다.
만약 thread가 매우 많다면
- 같은 program counter를 가진 독립적인 thread를 찾고,
- 이 thread를 warp로 묶는다.
이 과정은 divergence를 없애주기 때문에 SIMD utilization을 향상시킨다. 단, nested if문이 있는 경우에는 divergence가 발생하기 때문에 cycle이 낭비된다. if문이 하나일 때는 cycle 하나이지만 중첩될수록 많은 cycle이 낭비된다.
최신 기술은, 이러한 nested if를 허용하기 위해 각 thread별로 PC를 가진다. 앞서 warp의 모든 thread가 같은 PC를 가진다고 했는데 조금 모순되지 않나?라 생각할 수도 있다. 각 thread는 각각의 PC를 가지되, 같은 PC를 가진 thread만 한 번에 실행하는 형식이다. - 그래서 SIMT를 유지한다.
이를 통해 divergence로 인해 생기는 cycle 낭비를 조금이나마 막을 수 있다.
Warp Based SIMD vs Tranditional SIMD
traditional SIMD의 경우 single thread이다.
- sequential instruction execution이기 때문에 SIMD instruction에서 lock이 필요하다.
- programming model도 SIMD이다. 따라서 software가 vector 길이를 알아야 한다.
- ISA는 vector instruction이 SIMD instruction을 포함하고 있어야 한다.
반면 warp based SIMD의 경우, SIMD 방식으로 실행되는 여러 개의 scalar thread들로 구성되어 있다. (모든 thread가 같은 instruction을 실행한다)
- 따라서 lock이 필요없다.
- 각 thread는 독립적으로 취급받는다. 즉, programming model은 SIMD가 아니다. 때문에 software는 vector 길이를 몰라도 되며, dynamic하게 thread를 grouping할 수 있다.
- ISA는 scalar이므로 dynamic하게 구성될 수 있다.
- 근본적으로 SPMD programming model이 SIMD hardware에 구현된 것이다.
요약
GPU는 SPMD를 parallelism을 사용하고, 이에 최적화된 hardware를 설계한다. portability와 programmability를 위해 SPMD programming model을 유지하며, 복잡한 contol logic은 SIMD hardware로 대체한다.
GPU execution model은 ILP, DLP, TLP 3가지를 모두 지원한다.
DLP의 경우 여러 개의 data를 처리하는 것이고, TLP는 find-grained multithreading으로 여러 개의 thread를 실행하며, ILP는 모든 warp더라도 모든 instruction이 별개로 + 동시에 돌아가기 때문이다.
잘못된 내용이나 오탈자에 대한 지적, 질문 등은 언제나 환영합니다.