[이종병렬컴퓨팅] GPU architectures - NVIDIA
이 글은 포스텍 성효진 교수님의 이종병렬컴퓨팅(CSED490C) 강의를 기반으로 재구성한 것입니다.
이 글에서는 다음과 같은 내용들을 살핀다.
- GPU architecture의 예시 - NVIDIA
NVIDIA GPU Architecture
용어 정리
| NVIDIA | AMD | 뜻 |
| kernel | kernel | GPU의 multiple thread에 의해 동작하는 함수. CPU와 parallel하게 동작할 수 있다. |
| thread block | work group | 다른 data에 대해 같은 kernel을 실행하는 thread의 그룹. 단일 SM/CU에서 warp의 그룹으로 실행된다. 내부의 thread끼리는 communicate할 수 있는데 이는 hardward에 의해 지원된다. |
| thread | work item / thread | warp의 개별 실행 단위 |
| streaming multiprocessor (SM) | compute unit (CU) | parallel ALU를 포함하는 GPU의 parallel vector processor 중 하나. |
| warp | wavefront | lock step에서 실행되고, 동일한 instruction을 실행하며, 같은 control flow path를 공유하는 작업 단위, mask될 수 있으며, hardward thread에 의해 vectorize된다. |
thread block의 크기에 따라, 즉
- thread block의 크기가 너무 작은 경우(thread block에 thread 1개) : thread block의 개수가 streaming multiprocessor보다 더 많아져서 scheduling overhead가 너무 커진다.
- thread block의 크기가 너무 큰 경우(thread block에 thread 개수가 data size와 동일) : 1개의 thread block, data size개의 thread가 있는 경우 그러면 100개의 streaming multiprocessor가 있더라도 1개밖에 사용하지 못하기 때문에 비효율적이다. 때문에 적당히 나눠야 하며, 나눈 thread block들은 streaming multiprocessor에 적당히 할당되어 실행된다.
NVIDIA Memory Hierarchy

- thread : kernel의 instance로, thread만이 접근할 수 있는 private memory가 있다. thread block 내의 thread ID, PC, register, input/output 결과들이 이 memory에 저장된다.
- thread block : 동시에 실행되는 thread의 집합. block별 shared memory가 있으며, barrirer나 shared memory를 통해 communicate한다. thread block을 식별하기 위한 block ID가 있다.
- grid : 동일한 kernel을 실행하는 thread block의 array. 즉 grid는 전체 kernel이므로 global memory에 읽고 쓰며, 이를 통해 global synchronization을 한다. 단 thread block의 barrier나 shared memory를 쓰는 것이 훨씬 빠르다.
NVIDIA Fermi
16개의 SM, 총 512개의 core가 있다.

각 SM은 위 그림과 같이 생겼다. warp scheduler는 2개, 각 warp에는 32개의 thread가 있다. SM에는 2개의 exeuction unit, 32개의 core가 있다.
여기서 core 내부에 register가 있는 것이 아니라 외부에 register가 있기 때문에 각 core는 연산을 하기 위해 register에서 값을 가져오고, register에 값을 쓰는 연산을 했다. core 내부에는 floating point unit과 integer unit 2개가 같이 있었다.
또 shared memory외 L1 cache의 역할을 둘 다 하는 memory가 하나 있다. 현대의 GPU들은 L1 cache용 memory와 shared memory용 memory가 따로 있지만, 그 당시에는 이렇게 사용했다.
Fermi의 Thread Scheduler
- chip level : thread block을 SM에 할당한다. (thread block scheduler)
- sm level : warp와 warp의 exeuction unit에 대해 작동한다. (warp scheduler)
warp scheduler는 한 cycle에 warp에서 하나의 instruction을 가져온다. 이 방식은 매 cycle마다 다른 warp에서 instruction을 가져오기에 fine grained multithreading이다. 이 방식을 사용하면 thread instruction 간의 dependency를 신경쓰지 않아도 된다는 장점이 있다.
Fermi Memory Hierarchy

- host memory는 CPU의 memory이며, host memory는 device memory와 연결되어 있다. 따라서 CPU에서 사용한 값을 GPU에서 사용하기 위해서는 host memory에서 device memory로 옮기는 과정이 필수적이다.
- L2 cache는 모든 thread에 의해 공유되며, 모든 SM이 이 memory에 있는 값을 볼 수 있다. synchornization variable이 L2 cache에 있으면 더 빨리 쓸 수 있기 때문에 필요하다.
- 모든 SM에는 L1 cache가 있다. 앞서 언급했듯 이 시대의 L1 cache와 shared memory는 하나로 합쳐져 작동했다.
- 여기서 shared memory는 user-managed cache이며, 사용자가 값을 caching할 memory이다. 특정 값을 저장하기 위해 programmer가 explicit하게 값을 저장하는 공간이다.
- Register는 위 그림에서는 분리되어 있는 것처럼 보이지만 실제로는 매우 큰 register가 SM별로 할당되어 있는 것이다.
- 한 SM에 대해 active한 warp의 수를 신경써야 한다. GPU의 경우 register에 context switching을 위한 정보를 넣는데, 한 SM당 너무 많은 warp를 사용하면 이 register가 부족해지기 때문이다.
Kepler (2014)
double precision floating point 연산 속도를 향상시켰다.
4개의 warp scheduler, dual instruction dispatch unit이 있다. ILP한 방식으로 indepdendent한 warp를 가져와서 2개의 independent instruction을 실행시킨다. 만약 못 찾으면 그냥 하나만 실행한다. - 즉, ILP, TLP를 모두 실행하는 방법이다.
Pascal (2016)
NVLink를 사용한다. NVIDIA GPU 전용으로 구성된 link이며 속도가 매우 빠르다. 여러 개의 GPU를 사용할 때를 고려한 기술이다.
unified memory를 지원한다. pascal 이전의 unified memory는 software가 사용하는 방식이었으며, CPU memory와 GPU memory 사이에 데이터를 옮길 필요 없이 사용하는 통합된 memory였다. 때문에 CPU와 GPU 둘 다에서 모두 사용할 수 있었다. 이 memory는 unified virtual memory space를 제공했다.
Volta (2017)
tensor core를 사용한다는 점이 제일 큰 차이점이다. 때문에 더 유연한 thread scheduling을 할 수 있게 되었다. 이 때부터는 각 thread의 execution state가 저장되므로 각각의 PC와 call stack을 저장한다. 이 방식을 사용한다고 SIMT가 아닌 것은 아니다. 실제 실행은 같은 PC를 가진 thread만 실행하기 때문이다.
이전에는 barrier가 thread block level로 작동했는데, 여기부터는 sub-block과 multiblock에서도 작동하게 되었다.
Tensor Core

tensor core는 행렬 계산을 위한 특별한 연산 단위이다. 각 tensor cores는 cycle 하나에 4 by 4 행렬의 곱셈과 덧셈 연산을 수행한다.

각 warp가 16 by 16의 결과를 계산한다고 하자. tensor core는 4 by 4 크기이기에, 4개의 4 by 4 size로 입력을 나눈다. 그러면 각각의 4 by 4 행렬은 하나의 cycle에서 tensor core가 실행하고 결과를 만들 수 있다.
이 block을 어떻게 thread block으로 나누는지는 이후에 다룬다. input이 shared memory에 저장된 경우, 하나의 thread block당 여러 개의 tile을 계산할 수 있다. 이 방법도 나중에 다룬다.
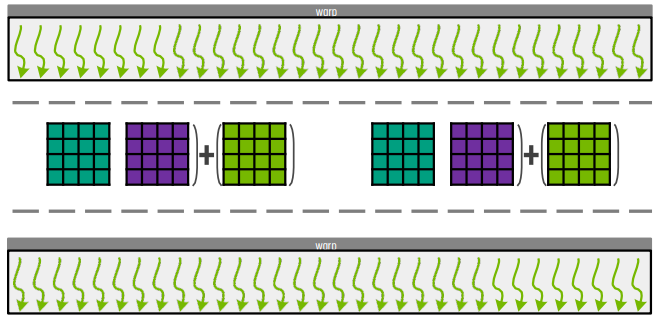
기존 방식의 경우, 행렬 연산을 위해서는 warp 내에 있는 32개의 thread가 병렬로 작동하고, 이후에 barrier가 작동하고 연산 결과를 tensor core가 작동하면서 취합하는 방식이었다.
Hopper (2023)
여기서부터는 tensor core gpu라고 부른다. tensor core를 위해 fetch 속도를 더 빠르게 했다.
thread block과 thread block hierarchy에 대해 새로운 수준의 parallelism을 도입했다. (thread - thread block - thread block cluster - grid 순서) 이를 통해 SM끼리 data를 더 쉽게 공유할 수 있게 되었다.
기술적 진화
- interconnect와 memory bandwidth 확장으로 인해 CPU-GPU, GPU-GPU 간 병목을 줄였다. 이외에도 NVLink(point to point)나 NVSwitch(bus)가 도입되었다.
- tensor core, RT cores를 사용해 heterogeneity가 증가했다.
- 더 flexible해졌다. thread끼리 더 fine-grained synchronization해졌고, thread block끼리 synchronization이 되고, 이를 지원하는 scheduler가 있다.
- unified memory와 hardware coherence를 지원해서 host-device data communication이 더 쉬워졌다.
- GPU virtual machine을 위한 보안 기능도 추가되었다.
기술적 트렌드
- transistor가 점점 더 작아지고 있고, 면적당 계산력이 늘어나기 때문에 core가 더 늘어날 것이다.
- 성능을 위해서 Tensor Core 등의 기능이, Programmability를 위해서 cooperative group이나 indepedent thread scheduling, threadd block cluster 등이 추가되고, security를 위해 VM support 등이 추가될 것이다.
- deep learning을 위해 더 큰 cluster로 scale out되고 있다. NVLink나 shared memory, NVSwitch 등의 기능이 생기고 있고, CPU와 GPU, DPU들끼리 integration이 일어나고 있다.
- 한계점은 GPU core가 더 빨라짐에 따라 memory bandwidth가 한계점으로 맞은 상황이다.
잘못된 내용이나 오탈자에 대한 지적, 질문 등은 언제나 환영합니다.