[이종병렬컴퓨팅] CUDA Basics
이 글은 포스텍 성효진 교수님의 이종병렬컴퓨팅(CSED490C) 강의를 기반으로 재구성한 것입니다.
이 글에서는 CUDA programming language를 사용하는 방법을 알아본다.
CUDA
CUDA는 NVIDIA GPU 전용 software이다. 기본적으로는 C/C++이며 여기에 몇몇 library를 추가해서 쓸 수 있다.
- CUDA kernel을 사용하고 실행하는 방법
- GPU memory를 관리하는 방법
- communication과 synchronization을 관리하는 방법
Host와 Device
- host memory : CPU의 memory
- device memory : GPU의 memory
heterogeneous computing은 serialize한 부분과 parallel한 부분이 나뉜다. serialize한 부분은 CPU가, parallel한 부분은 GPU가 실행한다.
Heterogeneous Computing의 단계
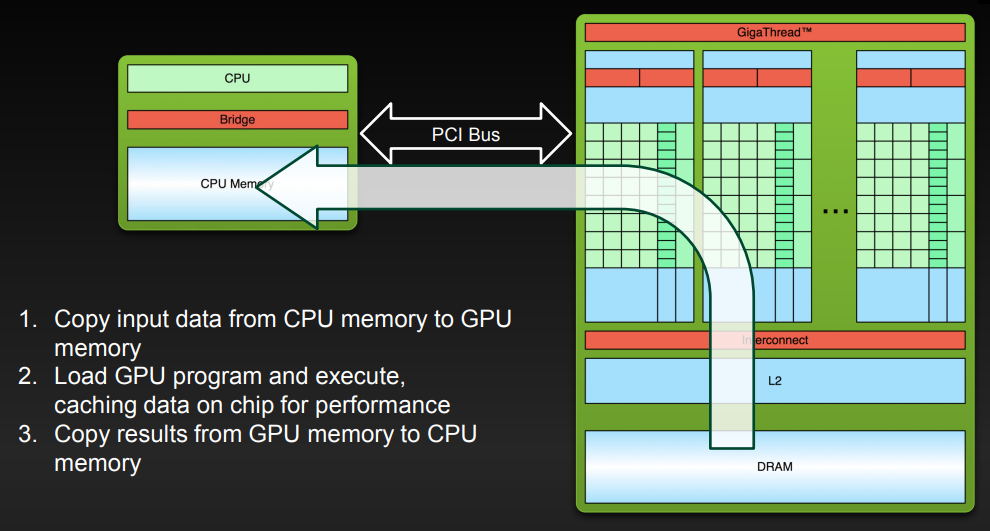
실행되는 방법은 크게 아래와 같다.
- CPU memory에 있는 data를 GPU로 옮긴다.
- kernel(GPU program)을 실행한다. 그러면 GPU는 안에 있는 cache에 값을 쓴다.
- 필요 시 GPU memory에 있는 결과를 CPU로 옮긴다.
CUDA Programming
Hello World!
__global__ void mykernel(void) {
}
int main(void) {
mykernel<<<1,1>>>();
printf("Hello World!\n");
return 0;
}위 코드에서 `__global__`로 선언한 함수가 GPU에서 실행된다. 이를 호출하기 위해서는 기본적인 function call과 동일하지만 `<<<>>>`를 추가해야 한다. 여기에 들어가는 숫자는 grid의 크기, thread block의 크기이며 작업을 어떤 단위로 나눌지에 대한 숫자인데, 후술하겠다.
이 코드가 컴파일되면 `__global__`이 붙은 부분은 nvcc가 컴파일하며, GPU에서 실행시키기 위해 한 binary executable file로 바뀐다. 나머지 부분은 gcc가 컴파일하며, CPU에서 실행시키기 위해 또다른 binary executable file로 바뀐다.
`mykernel<<<1,1>>>()` 이 부분을 kernel launch라고 하며, 이 코드가 GPU에서 실행된다.
Vector Addition
__global__ void add(int *a, int *b, int *c) {
*c = *a + *b;
}vector addition을 위해서는 위와 같이 코드를 쓴다.
이 때 a, b, c는 GPU에서 실행되기 때문에 device memory에 올라가 있어야 한다. 따라서 GPU에 미리 값을 올려 두어야 한다.
Memory Management
host memory와 device memory는 별개이다.
즉, host memory에 있는 값들은 device로 전달되거나 받아올 수 있지만 device에서 dereference되지 않는다. 같은 이유로 device memory에 있는 값들은 host로 전달되거나 받아올 수 있지만 host에서 deference되지 않는다.
이를 위해 `cudaMalloc()`, `cudaFree()`, `cudaMemcpy()`를 사용해 device memory를 할당하고, 해제하고, 복사한다. C의 malloc(), free(), memcpy()와 동일하다.
- cudaMalloc ( void** devPtr, size_t size ) : device의 global memory에 memory를 할당한다.
- cudaFree ( void* devPtr ) : device의 global memory에서 memory를 할당 해제한다.
- cudaMemcpy ( void* dst, const void* src, size_t count, cudaMemcpyKind kind ) : host memory와 device memory에서 정보를 옮긴다. asynchronous하다!
- cudaMemcpyKind는 `cudaMemcpyDeviceToHost`와 `cudaMemcpyHostToDevice`, `cudaMemcpyDeviceToDevice`가 있다.
기본적인 틀
__global__ void add(int *a, int *b, int *c) {
*c = *a + *b;
}
int main(void) {
// 1.
int a, b, c; // host copies of a, b, c
int *d_a, *d_b, *d_c; // device copies of a, b, c
int size = sizeof(int);
// 2. Allocate space for device copies of a, b, c
cudaMalloc((void **)&d_a, size);
cudaMalloc((void **)&d_b, size);
cudaMalloc((void **)&d_c, size);
// 3. Setup input values
a = 2;
b = 7;
// 4. Copy inputs to device
cudaMemcpy(d_a, &a, size, cudaMemcpyHostToDevice);
cudaMemcpy(d_b, &b, size, cudaMemcpyHostToDevice);
// 5. Launch add() kernel on GPU
add<<<1,1>>>(d_a, d_b, d_c);
// 6. Copy result back to host
cudaMemcpy(&c, d_c, size, cudaMemcpyDeviceToHost);
// 7. Cleanup
cudaFree(d_a); cudaFree(d_b); cudaFree(d_c);
return 0;
}위 코드와 같으며, 글로 표현하면 다음과 같다. 각 method의 사용 방법은 공식 문서를 찾아보는 것이 좋다.
- host에 할당될 변수, device에 할당될 변수를 선언한다.
- cudaMalloc을 사용해 device에 memory를 할당한다.
- host에 값을 쓴다. (필요 시 host에 memory를 할당하고 값을 써야 할 수도 있다.)
- cudaMemcpy()를 사용해 host에서 device로 값을 복사한다.
- kernel을 호출한다.
- kernel의 실행 결과는 device에 있으므로, 이 값을 host로 옮겨온다.
- cudaFree()를 사용해 device에 할당한 memory를 해제한다.
Parallel하게 실행하는 방법
Block
__global__ void add(int *a, int *b, int *c) {
c[blockIdx.x] = a[blockIdx.x] + b[blockIdx.x];
}
add<<<N, 1>>>();위 코드처럼 `add<<<1, 1>>>()` 대신 `add<<<N, 1>>>()`로 호출하면 add()를 N번 병렬로 실행한다.
이 때 add() 함수의 parallel한 호출을 block이라고 하며, block의 집합을 grid라고 한다. 여기서 N은 block 개수를 의미한다.
이 때 각 호출에서 `blockIdx.x`를 사용해 thread index를 잡을 수 있다.

Thread
각 block은 thread로 구성되고, block 내의 thread 또한 parallel하게 동작한다.
__global__ void add(int *a, int *b, int *c) {
c[threadIdx.x] = a[threadIdx.x] + b[threadIdx.x];
}
add<<<1, N>>>();위 코드처럼 `add<<<1, N>>>()`로 호출해도 add()는 N번 병렬로 실행한다.
단, 위의 경우는 block-parallel이었지만 여기서는 thread-parallel이다. 때문에 위에서 `blockIdx.x`를 사용한 대신 여기서는 `threadIdx.x`를 사용한다.
Block과 Thread 합치기
그 전에 앞에서 살폈던 개념을 합쳐보자.
- thread : sequential한 실행 단위. 따라서 thread는 parallel하게 동작하며, 같은 sequential program을 실행한다.
- thread block : thread들의 그룹이다. 하나의 SM - streaming multiprocessor - 에서 실행되며, block 내의 thread는 synchronize할 수 있고, shared memory를 사용해 communication할 수 있기에 synchronization과 data 교환이 빠르다.
- grid : thread block의 집합.
- grid의 thread block은 여러 개의 SM에서 실행된다.
- thread block끼리는 synchronization이 일어나지 않는다.
- thread block끼리 communication cost는 매우 높다.
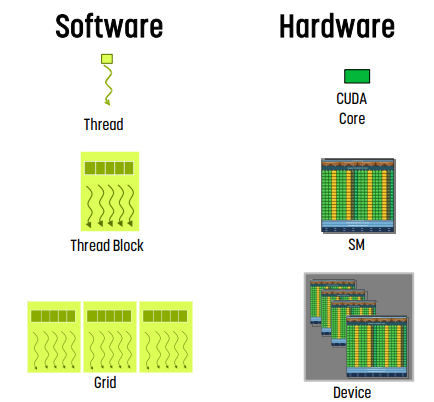
- thread는 core에 매핑된다. - core에서 실행된다.
- thread block은 SM에 매핑된다 - SM에서 실행된다.
- grid는 device에 매핑된다. - device에서 실행된다.
Block끼리는 independent
block끼리는 indepdent여야 한다. synchronization과 communication cost가 매우 높기 때문에 dependency가 없어야 한다. dependency가 없는 경우 순서 없이, parallel하게 실행할 수 있기 때문이다.
ID와 Dimension
thread는 1D, 2D, 3D ID를 가질 수 있으며, block 내부에서 고유하다.
block도 동일하게 1D, 2D, 3D ID를 가질 수 있으며 grid 내부에서 고유하다.
이 dimension은 kernel을 시작할 때 결정한다.
아래와 같은 내장 변수들이 있으며, 이를 사용해서 n차원에 대한 memory addressing을 단순화한다.
- threadIdx : `threadIdx.x`, `threadIdx.y`, `threadIdx.z`로 표기하며, 각각 block 내부의 thread index를 의미한다.
- blockIdx : `blockIdx.x`, ` blockIdx.y`, ` blockIdx.z`로 표기하며, 각각 grid 내부의 block index를 의미한다.
- blockDim : `blockDim.x`, ` blockDim.y`, ` blockDim.z`로 표기하며, block에 있는 thread의 개수를 의미한다.
- gridDim : `gridDim.x`, ` gridDim.y`, ` gridDim.z`로 표기하며, grid에 있는 block의 개수를 의미한다.
`dim3` type을 가진 변수들은 dimension을 초기화하기 위해 사용한다. 값을 넣지 않은 것들은 1로 초기화된다. 예를 들어 dim3 `gridDim(256)`이라고 했으면 gridDim.x는 256, gridDim.y와 gridDim.z는 1이다.
예시
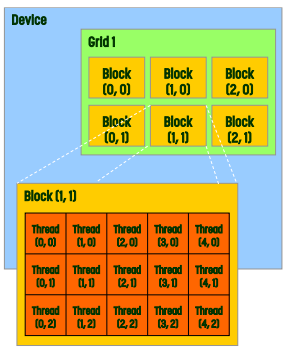
위 예시에서 grid 1에는 총 6개의 block이 있다.
- gridDim : gridDim.x는 3, gridDim.y는 2, gridDim.z는 1
- blockDim : blockDim.x는 5, blockDim.y는 3, blockDim.z는 1
- blockIdx와 threadIdx는 그림에 적혀 있다.
Kernel Launch에서 ID
그럼 `func<<<gridDim, blockDim>>>();`를 살펴보자.
- gridDim은 grid에 있는 block의 개수를 정의한다.
- blockDim은 block에 있는 thread의 개수를 정의한다.
예시
dim3 threadPerBlock(16, 16);
dim3 numBlocks(N/threadsPerBlock.x, N/threadsPerBlock.y);
MatAdd<<<numBlocks, threadsPerBlock>>>(A, B, C);예를 살펴보자. input은 N by N의 matrix이다.
threadPerBlock, 즉 blockDim은 각 block에 thread를 16 by 16으로 정의하겠다는 것이고,
numBlocks, 즉 gridDim은 grid에 block을 N/blockDim.x by N/blockDim.y로 정의하겠다는 것이다. - 이거는 input을 이렇게 나누어야 모든 input을 처리할 수 있기에 이렇게 두는 것이다.
Dimension 결정
- grid와 block의 크기를 설정하기 위해서는 다음과 같은 기준을 따라야 한다.
- 전체 입력을 처리하고, GPU를 busy한 상태로 처리하기 위해서는 충분한 양의 thread가 필요하다.
- block size의 선택은 warp 점유율과 관련한 최적화 단계이다.
- 무작정 크게 둔다고 좋은 것이 아니라, 한계도 있다.
- grid의 경우 (x, y, z)가 (2$^{31}$ - 1, 65535, 65535)
- thread block의 경우 (x, y, z)가 (1024, 1024, 64)
- block당 thread의 최대 개수는 1024개이다.
Indexing
자. 지금까지 block과 thread에 대해 살펴봤다. indexing을 해 보자.

위 예시는 block당 8개의 thread를 사용하고 block은 4개를 사용하는 상황이다. 즉 blockDim.x는 8이라는 말!
여기서 thread index를 원하는 위치에 잡는 방법은 `blockIdx.x * blockDim.x + threadIdx.x`이다. 아래 내용을 복기하면서, 왜 이렇게 나오나 생각해보자.
threadIdx : block 내부의 thread index를 의미
blockIdx : grid 내부의 block index를 의미
blockDim : block에 있는 thread의 개수를 의미
gridDim : grid에 있는 block의 개수를 의미
최종 형태
__global__ void add(int *a, int *b, int *c, int n) {
int index = threadIdx.x + blockIdx.x * blockDim.x;
if (index < n)
c[index] = a[index] + b[index];
}
add<<<(N + M-1) / M,M>>>(d_a, d_b, d_c, N);그러면 최종적으로 위와 같은 형태가 나온다. index를 검사하는 이유는, input이 blockDim의 배수가 아닌 경우가 많기 때문에 이에 대한 예외를 처리하기 위해서이다.
kernal launch는 `(N+M-1)/M, M`으로 되었는데, M은 block에 있는 thread의 개수이고, `(N+M-1)/M`은 N/M의 결과를 올림하기 위한 연산이다.
Managing Device
kernal launch는 asynchronous하다. 때문에 kernal launch 이후 control이 CPU로 바로 돌아온다.
따라서 결과를 사용하기 전에 synchonize를 무조건 해 주어야 한다.
- cudaMemcpy() : copy가 끝날 때까지 CPU 실행을 block한다. CUDA call이 끝나야 copy를 시작한다.
- cudaMemcpyAsync() : asynchronous하며, CPU를 block하지 않는다.
- cudaDeviceSynchronize() : CUDA call이 끝날 때 까지 CPU를 block한다.
기본적으로 host(CPU)가 device(GPU) memory를 관리한다.
Unified Memory Support
unified memory는 system의 모든 processor에서 접근할 수 있는 single address space이다. CPU와 GPU 둘 모두에서 해당 memory에 읽고 쓸 수 있다.
malloc()에 대한 호출을 cudaMallocManaged()로 호출한다.
__global__ void add(int n, float *x, float *y){
int index = blockIdx.x * blockDim.x + threadIdx.x;
int stride = blockDim.x * gridDim.x;
for (int i = index; i < n; i += stride)
y[i] = x[i] + y[i];
}
int main(void)
int N = 1<<20;
float *x, *y,
cudaMallocManaged(&x, N*sizeof(float));
cudaMallocManaged(&y, N*sizeof(float));
… // initialization
add<<<numBlocks, blockSize>>>(N, x, y);
…
}예시 코드는 위와 같다.
CUDA Device Memory Space Overview

- 각 thread들은
- thread별 register에 read/write할 수 있다.
- thread별 local memory에 read/write할 수 있다.
- block별 shared memory에 read/write할 수 있다.
- grid별 global memory에 read/write할 수 있다.
- grid별 constant memory나 texture memory에 read only이다.
- host는 global, constant, texture memory에 read/write할 수 있다.
잘못된 내용이나 오탈자에 대한 지적, 질문 등은 언제나 환영합니다.