[이종병렬컴퓨팅] Accelerators for Deep Learning
이 글은 포스텍 성효진 교수님의 이종병렬컴퓨팅(CSED490C) 강의를 기반으로 재구성한 것입니다.
이 글에서는 deep learning을 위한 가속의 motivation, domain-specific accelerator의 기본, efficiency metric 그리고 4가지 case study(Google TPU, GraphCore, DianNao series, Reconfigurable accerlerator)를 살펴본다.
heterogeneity의 Motivation
single core CPU의 경우 moore의 법칙/dennard의 scaling이 거의 끝이 났을 정도로 발전이 끝에 다다랐다.
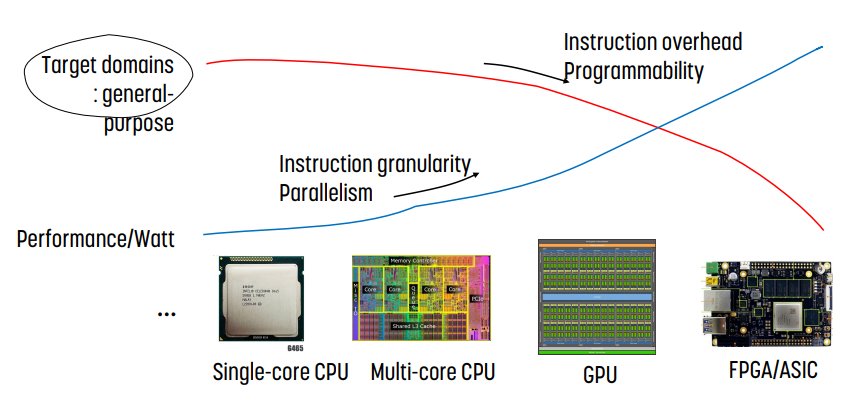
때문에 performance와 watt를 향상시키기 위해 single core CPU를 넘어, multi core CPU, GPU, FPGA 등으로 나아가고 있다. 그러나, CPU의 경우에는 target domain이 general purpose, 범용성을 가지는 것이 목표인데, GPU는 범용으로 사용할 수 없다.
Domain Specific Accelerator
domain specific accelerator는 그래픽, 딥러닝, 시뮬레이션 등 특정 분야에 특화된 하드웨어를 말한다.
특정 분야에 특화되었기 때문에 전문화된 연산, parallelism, 효율적인 메모리 시스템, 오버헤드 감소 등으로 성능이나 소모 전력량이 훨씬 향상되었다.
domain specific accelerator 설계와 parallel program을 작성하는 것의 주된 차이는 cost model이다.
일반적으로 arithmetic이나 logical 연산은 무시할 수 있을 정도로 빠르기 때문에 memory가 dominate한다. 따라서 효율성을 최대화하기 위해서는 프로그램을 재구성해야 하며, granularity나 memory footprint에서 차이가 만들어진다.
Acceleration의 source
- data specialization
- 특정 domain에 특화된 hardware operator set을 제공한다.
- 이를 통해 overhead를 줄이고 에너지를 아낄 수 있다.
- overhead 감소로 인해 area와 power는 memory에 의해 dominate되는데, 따라서 global memory access를 줄이는 것이 domain specific accelerator의 핵심이다. 따라서 domain specific accelerator는 algorithm과 동시에 설계되어야 한다.
- parallelism
- parallelism을 domain에 특화시키는 방식이다. 이를 통해 PE의 synchronization과 communication이 단순화되고, 이를 통해 overhead를 줄이고 utilization을 높일 수 있다.
- Local and Optimized memory
- 계산은 작은 local memory에서 수행해야 한다.
- 높은 bandwidth를 얻기 위해 global memory로의 access pattern을 최적화한다.
- 특정 데이터 구조를 앞축해 local memory의 유효 크기와 bandwidth를 올리는 방식도 있다.
- memory access를 load balance해서 memory utilization을 최대화하는 것이다.
- reduce overhead
- instruction overhead가 높기 때문에 복잡하고 전문화된 특수 instruction을 만든다.
Balancing Specialization and Generality
일반성과 효율성은 tradeoff를 가진다.
special instruction vs special engine
- special instruction은 general purpose processor에 추가되었다.
- dedicated accelerator는 on chip memory에서 data stating이나 data 이동을 최적화하는 데 효과적이다.
Accelerator 프로그래밍
domain specific accelerator는 firmware와 software 개발 인터페이스가 필요하다. API based 또는 compiler based이다.
더 유연한 domain specific language를 지원하는 accelerator는 domain specific compiler에 backend를 추가한다.
Efficiency Metrics
효울적인 deep neural network를 처리하기 위해서는 다음과 같은 것들을 고려해야 한다.
- 어떤 것을 측정하고 비교해야 하는지 (metric)
- 어떤 것이 주요 과제인지 (challenge)
- 설계 고려사항과 tradeoff (consideration, tradeoff)
Key Metrics
- accuraty : 결과의 품질
- throughput : 큰 데이터를 가진 것들에 대해
- latency : interactive한 것들에 대해
- energy and power : embedded device는 한정된 배터리를 가지고 있기 때문. 또한 data center는 cooling cost가 있다.
- hardware cost
- flexibility : deep neural network model의 작업 범위
- scalability : resource 양에 따른 성능의 확장
Key Operation
weighted sum을 계산하기 위한 multiply and accumulate (MAC)가 중요하다. 계산의 90% 이상을 차지하기 때문.
deep neural network SW/HW의 핵심 설계 목표
- throughput을 증가시키고 latency를 최소화하는 것이다.
- MAC 연산의 reduce를 줄이는 것. critical path를 줄임으로써 overhead를 줄일 수 있다.
- 필요 없는 MAC 연산을 줄여 cycle을 아끼는 것
- processing element (PE)의 개수를 늘리는 것. 이를 통해 더 많은 MAC 연산을 병렬로 수행할 수 있다.
- PE utilization을 증가시키는 것. 가능한 한 많은 PE에 작업을 분산하고, 부하를 균형있게 유지해 utilization을 높게 유지하는 것이다. 추가로 PE에 작업을 전달하기 위한 memory bandwidth
- 낮은 latency는 작은 batch size를 가져야 한다는 제약이 있다.
- 전력 소비량 감소
- 에너지 소비를 dominate하는 data 이동을 줄이기
- MAC 연산당 소모 전력 줄이기
- 필요 없는 MAC 연산 없애기
- 전력 소비는 열 방출에 의해 제한되어 있으며, 이는 parallel하게 수행할 수 있는 최대 MAC 연산의 개수를 한정한다.
Metric 측정을 위한 명세
- accuracy : dataset 작업의 어려움을 고려해야 함. 어려운 작업은 더 복잡한 deep neural network model을 필요로 한다.
- throughput : utilization과 processing element의 개수, 특정 deep neural network model의 수행시간
- latency : 평가를 위한 batch size
- energy와 power : 특정 deep neural network model을 수행할 때 전력 소모량, off chipe memory access
- hardware cost : on chip storage, processing element의 개수, chip area와 process 기술
- flexibility : 다양한 deep neural network에 대한 성능 비교
이 때 모든 metric은 설계 tradeoff를 공정하게 비교해야 한다. 특정 metric이 생략되었을 때는 문제가 발생하기 때문
- accuracy는 주어진 작업을 정확하게 수행하는지,
- latency와 throughput은 작업이 빠르고 실시간으로 수행되는지,
- energy와 power consumption은 기기 형태에 따라 결정되며,
- cost는 chip area에 의해 결정되며 각 solution에 얼마인지 결정되며
- flexibility는 작업 범위를 말한다.
비교
GPU의 경우

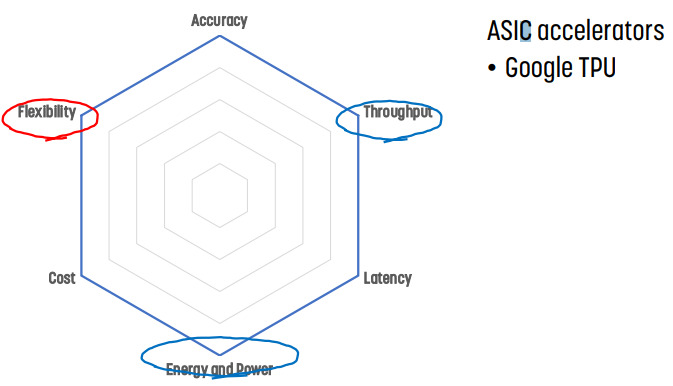
ASIC accelerator의 경우
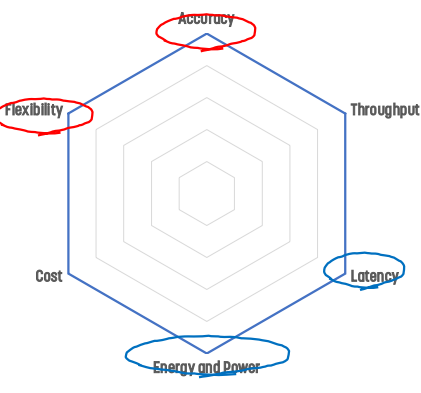
FPGA/CGRA accelerator의 경우

GraphCore의 경우

In memory computing의 경우
Case study : Google TPU
Systolic array
목표는 다음 요건들을 달성하는 accelerator를 만드는 것이다.
- 간단하고 규칙적인 설계
- 높은 concurrency
- 균형잡힌 computation과 I/O
핵심 아이디어는 하나의 processing element를 processing element의 regular array로 대체하고, processing element 간의 data flow를 잘 조절하는 것이다. 이를 통해 memory에서 가져온 input data를 출력하기 전에 변환한다.
이를 통해 memory에서 가져온 single data element에 대해 computation을 maximize한다.
장단점
- 장점 : memory bandwidth를 더 쓸 수 있고, concurrency를 높인다. 또한 regular한 설계이다.
- 단점으로는 irregular parallelism을 활용하는 데는 별로이고, specialize되었기 때문에 general하게 적용할 수 없다.
지난 10년간 lesson
- DNN은 memory와 compute에서 급격하게 성장했다.
- DNN 워크로드는 DNN의 혁신과 함께 성장했다.
- DNN을 compiler나 hardware만큼 최적화할 수 있다.
- inference slo는 batch size가 아니라 p99 latency에 의해 한정된다.
- production infernce는 multi tenacy이다.
- FLOPs가 아니라 memory의 문제다.
- DSA challenge : domain에 최적화하면서 flexible을 유지하기
- logic, wire, SRAM & DRAM은 불균등하게 개선된다.
- compiler를 최적화하고 ML 호환성을 유지해야 한다.
- TCO 대비 성능 대 CapEX 성능을 설계해야 한다.
Lesson 6: It's the memory
transistor의 수가 아니라 external memory access energy가 현대 칩의 한계를 결정한다. external memory access energy는 on chip memory access보다 100배 더 크고, arithmetic operation의 1만배 정도 더 크다.
memory access의 균형을 맞추기 위해 ALU를 추가해 FLOPs/s를 늘일 수 있다.
Lesson 7: DSA optimizes for domain while being flexible
TPU v2는 학습에 어려움이 있다.
- 더 많은 backpropagation, transpose, derivative
- 더 많은 memory : backpropagation을 위해 data를 유지한다.
- 더 넓은 operand : int8보다 더 큰 동적 범위가 필요하다.
- 어려운 parallelization : scale out 대신 scale up
- programmability
Lesson 8 : Unequal changes in semiconductor technology
logic은 무료이기 때문에 wire나 SRAM보다 더 빨리 발전한다.
VLIW XLA compiler
TPU v2와 이후 버전은 XLA 컴파일러에 의존한다.
- TPU v2와 v3는 322 bit의 VLIW instruction을 생성한다. 이를 통해 8개의 작업을 수행할 수 있다.
- 2개의 scalar, 2개의 vector ALU, vector load와 store, 행렬 곱셈 및 전치
- TPU v4 VLIW는 25% 더 넓다.
- compiler와도 호환된다.
표준 VLIW compilation 기술 사용 : loop unrolling, instruction scheduling, software pipelining
Reconfigurable Accelerators
Field Programmable Gate Array, FPGA
적은 개발 비용으로 custom hardware 기능을 구현할 수 있는 유연한 platform을 제공하는 판매용 프로그래밍 장치. logic block, programmable interconnection network, programmable input/output cell을 지원한다.
Coarse Grained Reconfigurable Architecture, CGRA
- domain specific flexibility
- general purposed와 fixed function 사이에서 flexibility를 유지한다.
- coarse grained level에서 재구성할 수 있다.
- hardware를 목적 domain에 맞게 재구성한다.
- spatial과 temporal computation의 결합
- spatial : 여러 processing element에서 병렬로 계산하고 데이터를 전공한다.
- temporal : 계산을 shared processing element에서 실행할 section으로 분할한다.
- data driven execution
잘못된 내용이나 오탈자에 대한 지적, 질문 등은 언제나 환영합니다.