
Floating Point
어떻게 표현하는지
case 3개
변환방식
rounding
2진수를 유효숫자 형태로 표현한 것
(-1)$^s$M2$^E$
- s : sign bit. signed integer와 동일하게 0이면 양수, 1이면 음수이다.
- M : significand(유효숫자). 일반적으로 [1.0, 2.0)의 범위를 가진다.
- E : exponent(승수). 2의 승수를 나타낸다.
Floating Point to Number
- 수를 정해진 형식에 따라 sign bit, exp bit, frac bit로 분류한다.
- exp bit, frac bit을 이용해 normalized / denormalized / special 분류를 한다.
- exp bit로 E값을, frac bit로 M값을 구한다.
- (-1)$^s$M2$^E$에 값을 넣어 수를 구한다.
Number to Floating Point
- 수를 2진수의 급수 형태로 표현한다.
- (-1)$^s$M2$^E$ 형식으로 변환한다.
- 정해진 bit의 개수에 따라 bias를 구하고, E와 bias를 이용해 exp bit를 구한다. 이 때 rounding을 하며, overflow 발생 시 exp값을 조정한다.
- M값으로 frac bit를 구한다.
Byte Ordering
종류 2가지
byte ordering이란 컴퓨터가 메모리에 값을 저장하는 방식
Big Endian : LSB가 high address에 저장되는 방식
Little Endian : LSB가 low address에 저장되는 방식
Calling Convention
procedure P가 Q를 호출했을 때 일어나는 일
control, data, local data
- caller-saved register의 값들을 caller stack frame에 저장한다. (push)
- return address를 caller stack frame에 저장한다. (push)
- %rbp, %rsp register의 값이 변경되었으므로 callee procedure로 제어권이 넘어간다.
- callee saved register의 값들을 callee stack frame에 저장한다. (push)
- callee procedure를 실행한다.
- ...
- callee procedure 종료 시, callee saved register를 callee stack frame에서 가져온다. (pop)
- return value를 %rax에 저장한다.
- caller stack frame에서 %rbp를 복구한다. (pop)
- caller procedure로 복귀한다.
Buffer Overflow
언제 발생하는지
왜 문제가 되는지
어떻게 막는지
데이터의 크기가 할당된 범위보다 더 클 때 원래 입력되어 있던 값들이 오염되는 현상을 buffer overflow라 한다.
return address가 다른 값으로 변경될 수 있다. return address가 위치해 있는 assembly는 무조건 실행되기 때문에 segmentation fault가 나거나, 또는 사용자가 원하는 instruction을 실행시킬 수도 있다.
- stack canari 사용 : 특정 data를 return address 다음 stack에 집어넣어 이 값이 바뀌지 않았을 때만 코드를 계속 실행하는 방법.
- safe function 사용 : string 입력 시 길이 제한을 두는 방법. gets() 대신 fgets()를 쓰면 된다.
- non-executable code segment ; 각 memory section에 control bit를 추가해 data section code를 readonly로 바꾸어 코드를 실행 불가능하게 만드는 방법.
- randomized stack offset : stack의 시작 주소를 randomized해 return address를 바꾸지 못하게 하는 방법.
Cache
locality 2종류
memory hierarchy와 cache의 개념
cache miss 3종류, cache
cache 구조 : set, line, tag, block
cache 접근 방식
set index가 가운데 있는 경우
종류 3가지
locality는 프로그램이 최근에 참조한 주소와 그 근처의 주소에 반복적으로 참조하는 경향이다.
- temporal locality : 최근에 참조된 주소를 반복적으로 참조하는 것을 의미한다.
- spatial locality : 최근에 참조한 주소 근처의 주소를 참조하는 것을 의미한다.
cache는 level k의 memory를 level k+1 memory의 임시 저장소처럼 작동시켜 데이터에 더 빨리 접근할 수 있는 기법이며, locality와 memory hierarchy 때문에 작동한다.
miss 종류
- cold miss : cache가 비어있는 경우. 첫 번째 참조일 때 발생한다.
- capacity miss : d가 cache의 크기보다 더 큰 경우.
- conflict miss : cache의 크기는 충분한데도 eviction이 계속 발생해 miss가 계속 발생하는 경우
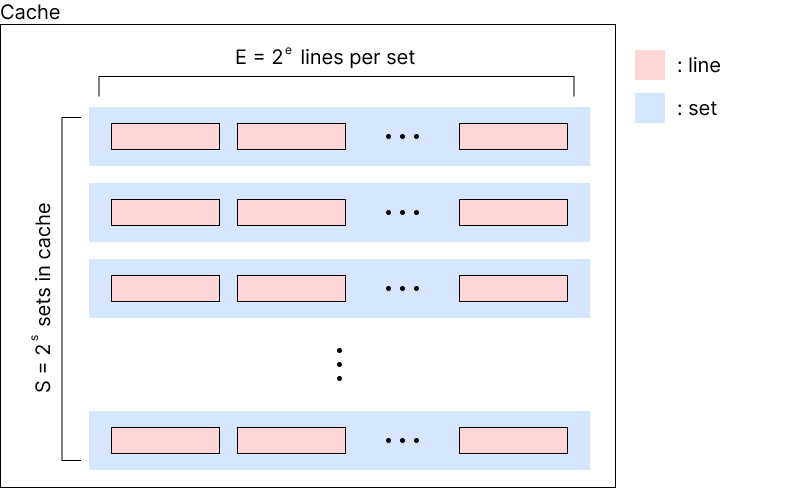


address가 M(=2$^m$)개의 bit로 이루어진다고 가정하자.
cache는 총 S(=2$^s$)개의 set으로 이뤄지며, 각 set은 E(=2$^e$)개의 line으로 이루어져 있다. 하나의 line은 v bit + tag bit + B(=2$^b$)개의 block으로 구성되어 있으며, 하나의 block은 1 byte의 정보를 담는다. 이 때 v는 해당 cache가 valid한지 여부이며, tag는 cache line의 식별자이다. 따라서 total cache size = S * E * B = 2$^{s+e+b}$이다.
접근 방식
address를 tag / set index / block offset으로 크게 3부분으로 나누며 이를 통해 cache에 접근한다.
- set index bit를 이용해 cache set에 접근한다.
- set에 있는 모든 line에 대해 tag bit를 비교한다.
- 모든 line에 대해 tag bit가 일치하는 line이 없는 경우 cache miss이다.
- 있는 경우 valid bit가 1인지 살펴본다.
- not valid라면 cache miss이다.
- valid라면 cache hit이다. block offset을 이용해 line에 있는 block에 접근한다.
set index가 가운데인 이유 : 인접해 있는 memory block들이 같은 set에 들어가게 된다.
종류
- fully associative : 단 1개의 set만 존재
- E-way set associative : 각 set당 E개의 line이 존재
- direct mapped : 각 set당 1개의 line만 존재
Exception의 종류
async - interrupt, signal
interrupt : process 외부에서 발생하는 exception (time interrupt)
signal : event call과 비슷한 개념.
sync - trap, fault, trap
trap : instruction 실행 중 의도적으로 발생하는 exception (system call)
fault : 의도적이지 않은 복구 가능한 에러에 의한 exception (page fault)
abort : 의도적이지 않은 복구 불가능한 에러에 의한 exception
Dynamic Memory Allocation
정의
fragmentation 2종류
fit 종류 3가지
segmentation vs paging
memory에 프로그램을 올리기 위해 memory를 관리하는 기술
Fragmentation
- internal fragmentation : 할당된 block이 data보다 클 때를 의미한다. 보통 자주 발생하며, alignment로 인한 padding 등 다양한 원인으로 인해 발생하며 측정하기 쉽다.
- external fragmentation : heap memory에는 충분한 공간이 있지만 큰 하나의 free block이 없어 메모리를 할당할 수 없는 상황을 의미한다.
Fit
- first fit : free block list를 처음부터 검색해서 할당할 block size보다 크기가 큰 첫 번째 free block에 할당한다.
- next fit : first fit과 유사하지만 free block list를 처음부터 찾는 대신 이전에 검색이 종료된 지점부터 검색을 시작한다.
- best fit : 모든 free block을 검사해 할당할 block size보다 크기가 큰 block 중 제일 작은 free block에 할당한다.
segmentation : address space 단위로 구분하는 방식. external fragmentation 비중 높아진다.
paging : page 단위로 관리하는 방식. internal fragmentation 비중 높아진다.
Garbage Collection - Mark & Sweep
뭔지, 어떻게 작동하는지
application이 직접 free하지 않고 사용하지 않는 dynamic allocated space를 자동적으로 free해주는 기법
memory와 pointer를 하나의 graph로 보아 root로부터 reachable한 것은 아직 사용중인 allocated block이고, unreachable한 것은 더 이상 사용하지 않는 garbage로 보아 이러한 block들을 free하는 방식
Process
정의
process의 address space 4가지 + 각각에 어떤 것들이 올라가는지
PCB
concurrent
process state : ready / running / block
정의 : program의 instance이다.
address space
- stack - local variable, argument, return address 등이 올라간다.
- heap - 동적할당한 것들이 올라간다.
- global data/code - 초기화된 global variable이 올라간다.
- code - instruction들이 올라간다.
PCB : process context를 저장하기 위한 자료구조. PID, state, PC, register 등 정보를 가진다.
state
- running : 현재 실행 중인 process
- ready : CPU의 실행을 기다리고 있는 상태
- block : I/O나 resource 대기 등의 이유로 event를 기다리고 있는 상태
Process Context Switching
정의
작동 방식
언제 쓰는지
cost 종류
정의 : processor가 실행하고 있는 process를 바꾸는 것
process P0에서 P1으로 switch하기 위해서는 P0의 모든 정보를 PCB0에 저장하고, PCB1의 모든 정보를 꺼내 와 실행해야 한다.
context switching overhead는 매우 크기 때문에, I/O를 기다리는 상황 등 process를 실행하지 않는 상황에서 다른 process로 제어권을 넘긴다.
cost는 크게 2가지, direct cost(save/restore)와 opportunity cost(cache miss cost)가 있다.
Fragmentation
internal fragmentation : 할당한 block이 data보다 클 때
external fragmentation : 하나의 큰 free block이 없어 할당하지 못하는 상황
Process Scheduling
process state transition을 관리하는 것.
job, ready, wait 3가지의 queue가 있다.
Thread
정의
어떤 address space 가지는지
장점
TCB
thread state
정의 : process 내의 실행 단위
thread의 address space의 경우, stack만 고유하게 가지며, code, data, heap은 공유한다.
process에 비해 고유하게 가지는 memory가 적기 때문에 더 가볍고, 공유하고 있는 자원이 많기 때문에 context switch가 더 빠르다.
TCB : thread context를 저장하기 위한 자료구조
thread state : init, ready, running, waiting, exit 5종류가 있다.
Concurrency
동시에 실행되는 것처럼 보이는 기술.
Synchronization
정의
race condition
critical section
mutex lock
condition variable
semaphore
synchronization의 구현

synchronization : multi thread로 인해 발생하는 race condition을 막는 것.
race condition : shared data에 접근할 때 순서에 따라 다른 결과가 나올 수 있는 상태
critical section : 오직 하나의 thread만 실행되는 것이 보장되는 영역
lock의 특징
- safe & mutual exclusion : 해당 thread만 실행하는 것이 보장됨
- progress : 아무도 lock을 가지고 있지 않다면 바로 lock을 얻을 수 있다.
- bounded wait : 언젠가는 lock을 얻는다.
mutex lock
- acquire() : lock이 free될 때까지 기다리며, free가 되면 lock을 가져온다.
- release() : lock을 release하고 lock을 기다리는 thread를 깨운다.
condition variable : lock을 가진 도중 sleep할 수 없는 문제를 해결하기 위해 만들어진 것. lock의 보조 도구 느낌으로 쓴다.
- wait() : [lock release + sleep]한 후, 누군가가 깨우면 lock을 얻는다.
- signal() : waiting thread가 있다면 깨운다.
- broadcast() : 모든 waiting thread를 깨운다.
semaphore : 일반화된 lock으로 여러 thread가 critical section에 접근할 수 있게 해 준다.
- P() : 값이 양수가 될 때까지 기다리며, 양수가 되면 1을 뺀다. wait()와 유사.
- V() : 값에 1을 더하고 P()를 호출한 thread가 있다면 깨운다. signal()과 유사.
- 만약 값을 1로 초기화하면 mutex처럼 쓸 수 있고, 0으로 초기화하면 coordination을 위해 쓸 수 있다. (scheduling constraints)
synchronization 구현은, uniprocessor에서는 interrupt로 쓰면 좋다. 그러나 multiprocessor인 경우 ready-modify-write instruction(memory에서 값을 읽고 수정하고 다시 쓰는 instruction)인 atomic function을 사용해 이를 구현한다.
- test-and-set : lock을 BUSY로 바꾸고 기존 lock 값을 가져오는 방법. 이 자체가 atomic instruction이고 HW에서 보장한다. 기존 lock이 FREE면 acquire하는 식이다.
- test-test-and-set : lock을 얻기 위해 lock의 값을 확인하는 단계를 거친다. 때문에 성능상 실행 시간이 더 줄고, test-and-set은 cache를 계속 갱신하므로 overhead가 크다. test-test-and-set은 얻을 수 있을 때만 test-and-set을 하므로 그 간극을 줄일 수 있다.
java monitor는 하나의 lock과 0개 이상의 condition variable을 사용해 shared data에 대산 concurrent한 접근 관리를 위한, 높은 추상화를 가진 도구이다. shared object와 유사하지만 명시적으로 lock을 사용할 필요가 없어 더 쉽게 synchronization을 처리할 수 있다. lock은 mutual exclusion을 위해, condition variable은 scheduling을 위해 사용한다.
lock에 대한 방법 : queueing lock으로 구현하는 것이 효율적.


Multiprocessor Synchronization
lock contention
cache ping
cache coherence
mutliprocessor에서 test-and-set의 문제점과 해결방법
lock contention : 한 번에 하나의 thread만 lock을 가질 수 있기 때문에 경쟁이 더 심해진다.
cache ping : context switch가 일어나며 shared variable의 cache가 여러 번 갱신되고, cache coherence를 유지하기 위해 해당 cache를 invalidate하기 때문에 cache 효율이 떨어진다.
cache coherence : 각 processor의 cache가 일관성있게 유지되어야 하는 것을 의미한다.
multiprocessor에서 test-and-set의 문제점
- test-and-set은 shared variable의 값을 계속 cache에 값을 쓰기 때문에, 다른 processor들이 참조하고 있는 cache를 invalidate한다. 따라서 test-test-and-set을 쓰면 효율이 좀 더 좋아진다.
- lock의 starvation이 일어날 수 있다.
이를 해결하기 위해 ticket lock이나 MCS lock 등 해결 방법을 사용한다.
- ticket lock은 이름처럼 ticket을 뽑고, 자신의 차례가 올 때까지 기다리는 방식이다.
- MCS lock은 cache coherence 문제를 해결하는 방식으로, compare-and-swap과 queue로 lock을 관리하는 방식이다. lock 획득 시 이전 thread가 쓴 데이터를 읽고, 때문에 cache miss가 나도 오직 1개의 process에서만 나게 된다.
Deadlock
정의
조건 4가지
처리 방식 3가지
정의 : 2개 이상의 작업이 resource를 할당받기 위해 circular waiting을 하고 있는 상태. resource는 CPU, disk 공간, memory, lock 등.
조건
- mutual exclusion : 한 번에 하나의 thread/process만 resource에 접근할 수 있다.
- non preemption : 다른 process의 resource를 뺏을 수 없다.
- hold and wait : resource를 가진 채로 다른 resource를 기다린다.
- circular wait : resource를 기다리는 것들이 circular해야 한다.
처리 방식
- prevent : 발생 자체를 막는 방식
- avoid : deadlock이 발생할 수 있지만 순서를 조절하는 방식
- banker algorithm : 현재 사용할 수 있는 resource, 각 process가 필요한 resource에 대한 정보들을 모아둔 후각 process에세 필요한 resource를 줘 보고 safe한지 검사하는 방식으로, simluation을 돌려보는 방식.
- detect & cover : 발생하면 감지하고 복구하는 방식
Process Scheduling
목표와 몇 가지 scheduling 방법
목표 : throughput 최대화, fairness
- FIFO
- SJF : optimal but unfair
- RR : time quantum만큼 실행한 후 queue의 맨 뒤로 넣는 방식. 같은 길이 task 여러개면 오래 걸린다.
- MFQ : 여러 개의 RR queue를 두는 방식. 각 RR queue의 time quantum이 다르다.
Virtual Memory
정의
segmentation
demand paging
replacement policy
thrashing
address space : OS가 제공하는 physical memory의 abstraction. 각 process는 같은 address space를 바라보는 것 처럼 보이지만, OS 내부에서 다른 physical memory를 가리키게 처리해 준다. (address translation)
physical memory address를 사용하는 것이 아니라 virtual memory address를 사용해 유한한 크기의 memory를 무한하게 보이게 만드는 방법. 따라서 virtual address를 physical address로 바꾸는 address translation 과정이 필요하다. 여기서 cache 효율을 높이기 위해 TLB를 쓰기도 한다.
segmentation : base and bound를 사용해서 virtual memory의 address space를 segment로 나누고 translate하는 방식. + 권한 체크도
보통 demand paging을 쓴다. demand paging은 page가 필요할 때만 disk에서 꺼내와 memory에 올리는 방식이다.
- process에서 특정 page가 필요하면, memory에 있는 page table을 본다. page table은 virtual page와 physical page를 매핑하는 자료구조.
- page hit라면 해당 page를 요청하고 받는다.
- page fault가 나면 page fault handler가 victim page를 선택해 교체한다.(필요 시 write back) 이후 disk에서 page를 memory에 올리고 page table을 갱신한다.
교체 알고리즘
- FIFO
- LRU : 제일 오래된 것 요체, optimal에 근사
- LFU : 제일 적게 사용된 것 교체
- Clock Algorithm : 2nd change - 2번 걸리면 교체하는 방식
- Nth change Algorithm : n번 걸리면 교체
Thrashing : demand paging에서 page fault가 계속 발생해 I/O cost만 계속 사용하는 것. process가 너무 많거나, memory 크기보다 필요한 page 개수 크기가 더 많거나 등의 이유가 있다.
OS란?
HW와 SW 사이의 interface.
- HW를 abstract해서 SW가 사용하기 쉽게 만들어준다. CPU를 process/thread로, memory는 address space로, disk는 file로.
- resource를 관리한다.
kernel?
Process vs Thread
정의
공유 여부
cost
격리 여부
정의
process는 program의 instance
thread는 instruction flow
공유 여부
process는 process context를 저장하는 PCB, 4가지 address space를 가진다.
thread는 stack만 별개의 것을 가지며 heap code data는 thread끼리 공유한다.
때문에 process끼리 통신하기 위해서는 resource를 많이 써야 하는 반면 thread끼리는 resource를 적게 써도 된다. 때문에 process는 parallel하게, thread는 concurrent하게 쓰는 것이 일반적이다.
cost
stack의 경우 크기가 작으므로 context switching cost가 적고, 생성 cost가 더 적다.
격리 여부
process끼리는 완전히 격리되어 있어 하나의 process에서 문제가 생겨도 괜찮다. 반면 thread는 그렇지 않기 때문에 하나의 thread에서 오류가 생기면 다른 thread에 영향을 줄 수도 있다. (heap에 이상한 값 쓴다던가 등)
Concurrent vs Parallel
정의
parallel은 실제로 작업이 동시에 실행되는 것을 말한다. 예를 들어 process가 2개의 processor(CPU core)에서 동시에 돌아가면 parellel이다.
concurrent는 작업이 동시에 실행되지 않지만, 그렇게 보이는 것을 말한다. 실제로는 context switching이 일어나면서 동작한다.
일반적으로 thread가 concurrent를 구현하고, process가 parallel을 쓴다.
Zombie Process
정의
언제 생기는지
어떻게 해결해야 하는지
parnet process가 fork()를 call 하면 child process가 생긴다.
이 때 parent process가 wait()를 call하면 child process의 모든 자원을 정리한다. 그렇지 않고 parent process가 종료하는 경우 child process는 orphan process가 된다. 이후 init process가 종료될 때 모든 orphan process를 정리한다.
그러나, orphan process가 가지고 있는 resource는 계속 메모리에 남아 있게 되며, 이러한 process를 zombie process라고 한다. 따라서 parent process는 wait()를 explicitly 호출해야 한다.
'내가 하고싶은 것! > 취준' 카테고리의 다른 글
| 기타 면접대비 질문 (0) | 2023.10.04 |
|---|---|
| 자료구조 면접대비 질문 (0) | 2023.10.04 |
| 네트워크 면접대비 질문 (0) | 2023.10.04 |
| DB 면접대비 질문 (0) | 2023.10.01 |
| 2022년 1월 SW개발병 지원 및 면접 질문 (0) | 2022.10.05 |