![[N2T] 리팩토링 기록](https://img1.daumcdn.net/thumb/R750x0/?scode=mtistory2&fname=https%3A%2F%2Fblog.kakaocdn.net%2Fdn%2FIyFuO%2FbtstayuPzGW%2FxmSCqDvdiPGDFMLFD2Xjuk%2Fimg.png)
리팩토링 하게 된 계기
개발 동기
Naver2Tistory는 사실 내가 사용하기 위해 만든 프로그램이다. 2022년 10월쯤에 개발 블로그를 네이버에서 티스토리로 옮기기로 결정하면서 안에 있는 포스팅들을 다 가져오고 싶었는데, 그동안 작성했던 포스팅이 약 300개 가량 되다 보니 수작업으로 일일히 옮길 수 없었다. 이를 위해 Naver2Tistory를 당시 내가 구현할 수 있는 수준으로 만들었었다. 만들다 보니 블로그를 나만 옮기는 게 아니니까 다른 사람들도 쓸 수 있겠다 싶어 리드미도 열심히 꾸몄고 형식을 맞춰서 오픈소스로 배포도 했다.
기존 Naver2Tistory의 문제점
이후에 Clean Code, Clean Architecture 같은 개발 서적을 읽고, 객체지향의 5대 원칙을 공부하면서 내가 짰던 코드가 많이 부족함을 느꼈다. 리팩토링을 시작했을 때 코드를 읽어봤을 때 모듈화만 적당히 잘 되었지 아래와 같은 단점들이 보였다.
- 필요없는 주석들이 너무 많았다. 주석은 유지보수되지 않는 경우가 대부분이므로 없는 것이 더 낫다.
- 예외처리가 너무 난잡하다. try-catch문을 너무 많이 사용해 가독성이 떨어진다는 느낌을 받았다.
- concrete class에 의존한다. 때문에 확장성이 없다시피 했으며 유지보수도 힘들었다.
- if-else문으로 대부분의 로직을 처리한다.
- 테스트 코드가 없다. 때문에 소스코드를 수정한 후 검증하는 과정이 오래 걸린다.
예시 - 너무 긴 if-else문
public class Converter {
/**
* Traverse childs of given parameter 'elements'.
* While traversal, reform it's HTML element to Tistory style.
*
* @param elements is which want to traverse.
* @see Converter#convertTable(Element)
* @see Converter#convertQUOTATION(Element)
* @see Converter#convertTEXT(Element)
* @see Converter#convertCODE(Element)
* @see Converter#convertIMAGE(Element)
* @see Converter#convertHORIZONTALLINE(Element)
* @see Converter#convertLINK(Element)
*/
private void dfsDOM(Elements elements) {
for(Element element : elements){
ContentType elementContentType = getContentType(element);
// If section type exists, then stylize
if(elementContentType == ContentType.TABLE){
this.convertTable(element);
}
else if(elementContentType == ContentType.QUOTATION){
this.convertQUOTATION(element);
}
else if(elementContentType == ContentType.TEXT){
this.convertTEXT(element);
}
else if(elementContentType == ContentType.CODE){
this.convertCODE(element);
}
else if(elementContentType == ContentType.IMAGE){
this.convertIMAGE(element);
}
else if(elementContentType == ContentType.HORIZONTALLINE){
this.convertHORIZONTALLINE(element);
}
else if(elementContentType == ContentType.LINK){
this.convertLINK(element);
}
// else then traverse deeper.
else{ // elementContentType == ContentType.NOTHING
dfsDOM(element.children());
}
}
}
// ...
}기존에는 table, quotation, text, code, image, horizontal line, link 정도의 스타일을 지원했다. 이 때 버전업을 하면서 새로운 스타일을 추가한다고 하자. 그러면 if문에 또 붙어야 하고, 해당하는 함수를 만들어야 한다. 숫자가 적을 때는 괜찮겠지만, 만약 모든 HTML의 스타일을 사용하게 된다면? if-else문만 엄청나게 길어질 것이다.
수정을 할 때 Converter 객체를 직접 수정해야 하기 때문에 SOLID 원칙에도 위배된다.
목표
이러한 문제들을 해결하기 위해 다음과 같은 목표를 세우고 리팩토링했다. 클린 코드에서 읽었던 [주석 최소화, 경계 처리, 테스트 코드 작성]을 적용하고자 했다.
- 주석 삭제. 의도를 설명한 주석, 유지보수 시 참고가 될 만한 주석만 남기고 모두 삭제. JavaDoc은 필요한 public 함수에만 남기고자 했다.
- 예외처리를 간소하게. 곳곳에 퍼져 있는 try-catch문을 응집시키고자 했다.
- 최대한 의존성을 줄이고 확장성 있게 코드를 작성하고자 했다.
- 이 프로그램은 Naver2Tistory이지만 추후에 Naver2Notion처럼 목적지 블로그를 추가할 수도 있고, Medium2Tistory처럼 출발지 블로그를 추가할 수도 있다고 가정했다.
- 현재 지원하는 스타일 이외에 다른 스타일들이 추가될 수 있다고 가정했다.
- 의존성을 줄이기 위해서 interface나 abstract class를 사용하고, if-else문을 줄이기 위해 map을 사용하는 방식을 채택했다.
- 테스트 코드 작성. 사용자 아이디/패스워드가 필요한 TistoryClient와 TistoryClient를 사용하는 class를 제외하고는 최대한 unit test를 진행하고자 했다.
리팩토링 결과
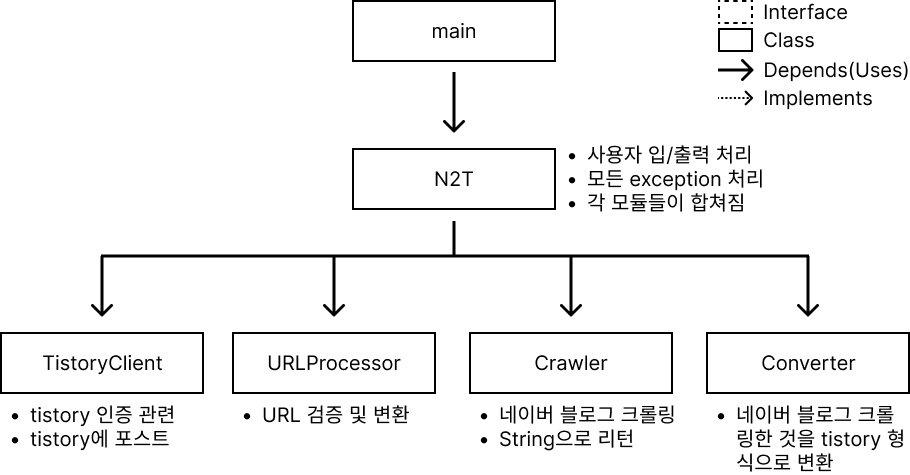
지금부터 어떻게 리팩토링했는지 각 module에 대해 인상깊었고, 기억해 둘 만한 변경점만 기술할 것이다.
Migrator

기존에는 N2T class로 묶었던 것을 목적지 블로그/출발지 블로그가 추가될 수 있다고 가정했기 때문에 명칭을 더 포괄적으로 바꾸었다. 그리고 각 module들에도 변화가 생겼고, 각 module들은 VO를 사용해 통신한다.
각 module들은 exception을 던지기만 하고, Migrator class에서 이를 받아 처리한다.
먼저 각 module들을 살펴보고 다시 Migrator를 살펴볼 것이다.
UrlProcessor
기존에는 네이버 블로그만 처리할 수 있었던 URLProcessor를 UrlProcessor, BlogUrlProcessor로 나누었다. 명명도 Java naming convention에 따라 UrlProcessor로 바꾸었다.
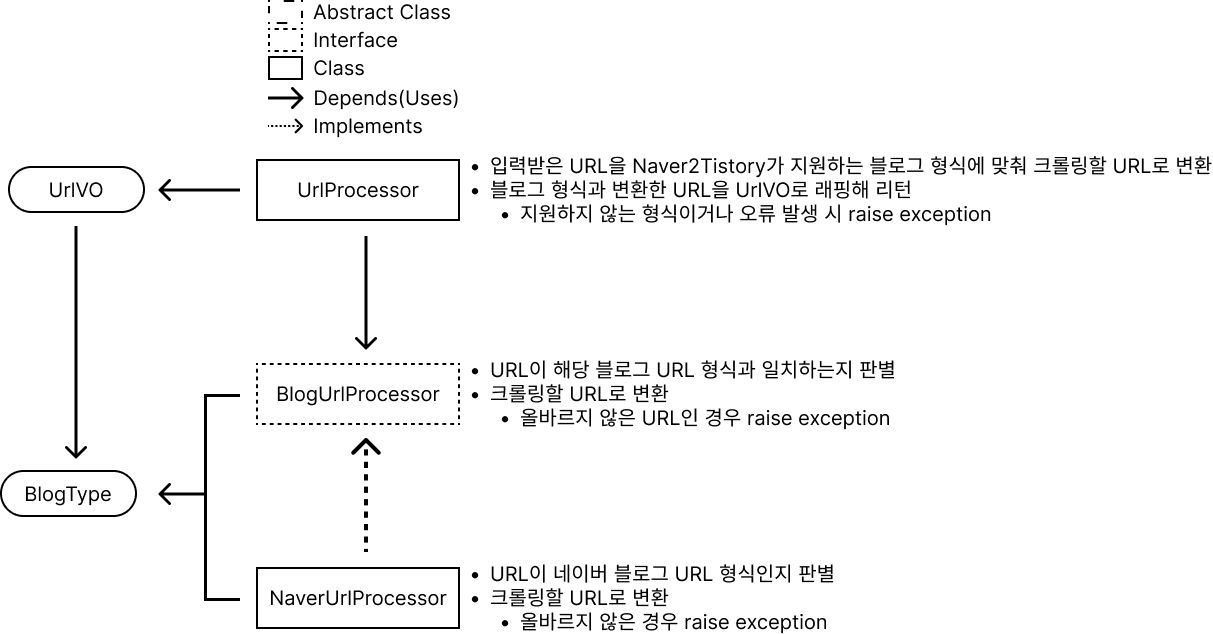
위 그림에 적혀 있듯 UrlProcessor는 Naver2Tistory가 지원하는 블로그 형식에 맞춰 크롤링할 URL로 변환하고, 블로그 형식과 변환한 URL을 UrlVO로 래핑해 리턴한다. 만약 지원하지 않는 형식이거나 크롤링 중 오류가 발생할 경우 exception을 날린다.
분명 dependency를 줄이겠다고 했는데, UrlProcessor는 abstract class가 아니라 concrete class로 구현했다. 이렇게 구현한 이유는 UrlProcessor는 추상화 수준이 매우 높게 설계했기 때문이며, 따라서 내부 로직이 변하지 않을 것으로 예측된다. 만약 다른 종류의 블로그가 추가되면 BlogUrlProcessor의 구현체를 추가하고, UrlProcessor의 blogUrlProcessors에 추가만 하면 된다.
UrlVO는 해당 URL이 어떤 블로그의 URL인지, 그리고 URL 처리 결과 2개의 attribute가 있다.
디자인 패턴으로는 UrlProcessor는 BlogUrlProcessor를 생성하므로 Template method pattern을, 블로그 종류에 따라 다른 BlogUrlProcessor interface의 구현체를 호출해 URL을 처리하므로 Strategy pattern을 사용한다.
SOLID 원칙을 생각해 보면, UrlProcessor는 [inputUrl을 UrlVO로 변환한다]는 역할만 수행하므로 SRP를 만족하는 것 같다. UrlProcessor의 생성자만 수정하면 다른 종류의 BlogUrlProcessor를 추가할 수 있기 때문에 OCP도 만족하는 것 같다. interface에 의존하고 있기 때문에 DIP도 만족하는 것 같다. LSP는 해당 사항 없는 것 같고, BlogUrlProcessor interface의 모든 method를 사용하므로 ISP도 만족하는 것 같다.
public class UrlProcessor {
private static final List<BlogUrlProcessor> blogUrlProcessors = new ArrayList<>();
public UrlProcessor(){
blogUrlProcessors.add(new NaverUrlProcessor());
// Append other blog url processors here
}
public UrlVO process(String inputUrl) throws Exception {
for(BlogUrlProcessor blogUrlProcessor : blogUrlProcessors){
if(blogUrlProcessor.matches(inputUrl)){
return new UrlVO(blogUrlProcessor.getUrlType(), blogUrlProcessor.process(inputUrl));
}
}
throw new Exception("[Url 작업 중 오류] : 지원하지 않는 블로그의 Url입니다.");
}
}// Implement this interface to preprocess other types of blog URLs.
public interface BlogUrlProcessor {
/**
* @return blog type of each url processor
*/
public BlogType getUrlType();
/**
* Return true if inputUrl matches type of blog URL format, otherwise false.
*/
Boolean matches(String inputUrl);
/**
* Process inputUrl to crawlable URL and return.
* @throws Exception when error occurs while processing URL.
*/
String process(String inputUrl) throws Exception;
}코드는 위와 같으며 다음 링크에서 열어볼 수도 있다. UrlProcessor 코드, BlogUrlProcessor 코드
고민했던 점
BlogUrlProcessor를 interface로 사용할지, abstract class로 사용할지 고민했다. 둘 다 구현체/상속체에게 특정 method의 구현을 강제할 수 있으며 polymorphism을 사용할 수 있기 때문이었는데, 여기서는 BlogUrlProcessor들이 공통 기능이 필요하지 않다고 생각했기 때문에 interface를 사용했다.
Scrapper
기존에는 네이버 블로그에서 크롤링한 결과를 바로 티스토리 형식으로 바꾸었는데, 출발지/목적지 블로그가 추가될 수 있다고 가정했기 때문에 기존 Converter를 Scrapper와 Converter 2가지로 나누었다. Scrapper는 출발지 블로그에서 크롤링한 후 공통 형식으로 바꾸고, Converter는 공통 형식을 목적지 블로그로 변환하는 역할을 한다. 일단 Scrapper부터 먼저 보자.
기존에는 크롤링만 수행했기 때문에 Crawler였지만, 이제는 크롤링한 후 정보를 가공하는 부분까지 진행하기 때문에 Scrapper로 명명했으며 내부적으로 크롤링과 파싱을 진행한다.

Scrapper는 UrlVO를 입력으로 받아 BlogType에 해당하는 BlogScrapper abstract class의 변환 method를 호출한다. 만약 지원하지 않는 형식이거나 크롤링 중 오류가 발생할 경우 exception을 날린다.
UrlProcessor과 마찬가지로 Scrapper도 추상화 수준을 매우 높게 설계했기 때문에 내부 로직이 바뀌지 않을 것으로 예상한다. 만약 다른 종류의 블로그가 추가되면 BlogScrapper의 derived class를 추가하고, BlogScrapper의 blogScrapperMap에 추가만 하면 되기 때문이다.
BlogPost는 게시글 제목, 그리고 HTML DOM 트리를 커스텀한 ConvertedTree의 root node 2개의 attribute를 가진다.
ConvertedTreeNode는 해당 node가 어떤 스타일을 가지는지, 내용은 어떤 것인지, 그리고 child node list를 attribute로 가진다.
디자인 패턴으로는 UrlProcessor과 마찬가지로 BlogScrapper를 사용하므로 Template method pattern을 사용하고, 블로그 종류에 따라 다른 BlogScrapper abstract class의 derived class를 호출해 URL을 처리하므로 Strategy pattern을 사용한다.
SOLID 원칙을 생각해 보면, Scrapper는 [UrlVO를 입력으로 받아 크롤링/파싱한다]는 역할만 수행하므로 SRP는 만족하지 않는 것 같다. 그러나 SRP를 만족시키기 위해 크롤링 기능을 분리하는 것에는 overhead가 더 크다고 생각했는데, 그 이유는 아래의 고민했던 점에서 설명하겠다. 다른 종류의 BlogScrapper를 추가하기 위해서는 BlogScrapper를 상속해 구현하고 Scrapper의 생성자에만 추가하면 다른 종류의 BlogScrapper를 추가할 수 있기 때문에 OCP도 만족하는 것 같다. Scrapper는 abstract class인 BlogScrapper에 의존하므로 DIP도 만족하는 것 같다. LSP는 해당사항 없는 것 같고, ISP BlogScrapper의 모든 method를 사용하므로 만족하는 것 같다.
public class Scrapper {
private static Map<BlogType, BlogScrapper> blogScrapperMap = new HashMap<>();
public Scrapper(){
blogScrapperMap.put(BlogType.NAVER, new NaverScrapper());
// Append other blog scrappers here
}
public BlogPost scrap(UrlVO urlVO) throws Exception {
BlogType blogType = urlVO.getUrlType();
String url = urlVO.getUrl();
if(blogScrapperMap.containsKey(blogType)){
BlogScrapper blogScrapper = blogScrapperMap.get(blogType);
return blogScrapper.scrap(url);
}
throw new Exception("[스크래핑 중 오류] : 지원하지 않는 블로그입니다.");
}
}// Inherit this abstract class to scrap other types of blogs.
public abstract class BlogScrapper {
private static final String defaultErrorMessage = "스크래핑 중 알 수 없는 오류가 발생했습니다.";
protected BlogScrapper(){
initializeErrorMessages();
}
public BlogPost scrap(String url) throws Exception{
Document document = crawl(url);
return parse(document);
}
protected Document crawl(String url) throws Exception {
try{
Connection con = Jsoup.connect(url).timeout(5000).ignoreHttpErrors(true);
Response response = con.execute();
if (response.statusCode() == 200) {
return con.get();
}
else{ // page not found
throw new Exception(getErrorMessage(response.statusCode()));
}
} catch(IOException e) { // 이외 connection 중 발생하는 오류
throw new Exception(getErrorMessage(500));
}
}
protected abstract BlogPost parse(Document document) throws Exception ;
protected HashMap<Integer, String> errorMessages = new HashMap<Integer, String>();
protected abstract void initializeErrorMessages();
protected String getErrorMessage(int statusCode){
if(errorMessages.containsKey(statusCode)){
return errorMessages.get(statusCode);
}
return defaultErrorMessage;
}
}코드는 위와 같으며 다음 링크에서 열어볼 수도 있다. Scrapper 코드, BlogScrapper 코드
고민했던 점
앞서 크롤링 기능 Scrapper에서 분리하는 것에는 overhead가 더 크다고 생각했는데, 그 이유를 여기에서 설명하겠다.
public class NaverScrapper extends BlogScrapper {
@Override
protected void initializeErrorMessages() {
errorMessages.put(204, "[네이버 블로그 오류] : 삭제되거나, 존재하지 않거나, 비공개 글이거나, 구버전 포스팅입니다.");
errorMessages.put(404, "[네이버 블로그 오류] : 유효하지 않은 요청입니다. 해당 블로그가 없습니다. 블로그 아이디를 확인해 주세요.");
errorMessages.put(500, "[네이버 블로그 오류] : 예상치 못한 에러가 발생했습니다.");
// Append other blog error code and message mapping here
}
private Elements extractPost(Document document) throws Exception {
Elements post = document.select(".se-viewer"); // naver blog 포스트 부분
if(post.size() == 0){
throw new Exception(getErrorMessage(204));
}
return post;
}
private String extractTitle(Elements post) throws Exception {
Elements head = post.select(".pcol1"); // naver blog 제목
if(head.size() == 0){
throw new Exception(getErrorMessage(204));
}
return head.text();
}
...
}위 코드는 NaverScrapper의 코드 일부분이며, 다음 링크에서 열어볼 수도 있다. NaverScrapper 코드
initializeErrorMessage()에서 네이버 블로그에서 사용하는 에러 메시지들을 초기화하고 있다. extractPost()와 extractTitle()은 크롤링 결과로부터 필요한 정보를 따 오는 것이므로 Crawler에 들어가는 것이 아니라 Parser에 들어갈 것이다.
반면, BlogScrapper의 crawl() method를 보자. 내부적으로 getErrorMessage()를 호출하는데, 여기에서 사용할 메시지들이 initializeErrorMessage()에서 초기화한 에러 메시지들이다.
만약 Crawler와 Parser 2개로 나눈다면 에러 메시지를 중복해서 적어야 한다! 중복된다면, 필연적으로 관리하기 어려워진다. 만약 에러 메시지를 공유한다고 치면, 어디서 관리할 것인가? Crawler와 Parser 2개 class만 사용하는데 Migrator에서 이를 관리할 수도 없고, Crawler에서 에러 메시지를 초기화하고 Parser에게 건네주는 방식이라면 두 클래스가 아주 강한 의존관계를 지니게 된다고 생각했다. 때문에 Scrapper를 Crawler와 Parser로 분리하는 것보다 일원화해서 관리하는 편이 더 좋다고 생각했다. Scrapping이라는 명칭의 역할도 달성할 수 있다는 부가적인 효과도 있다.
이후 따라온 고민은 BlogScrapper를 interface로 사용할지, abstract class로 사용할지였다. BlogScrapper의 parse()는 derived class에서 구현되어야 하는 것이 명확했다. 그러나 crawl() method가 애매했다. HTTP status code가 200인 경우 크롤링에 성공한 것이 99.9% 확정이기 때문에, BlogScrapper를 interface로 두면 crawl() method의 구현이 거의 중복될 것이라 예측했다. 때문에 BlogScrapper를 abstract class로 두었고, 꼭 구현해야 하는 initializeErrorMessage()와 parse()만 abstract method로 두었다.
NaverScrapper
앞서 Template method pattern과 Strategy pattern을 사용했었는데, NaverScrapper도 마찬가지이다. 예를 들어 image에 해당하는 section에서는 src를 추출해 이미지를 다운로드 해야 하고, table에 해당하는 section에서는 row/column/content를 추출해야 하는데, 이렇듯 section의 종류에 따라 공통 형식으로 변환하는 형식이 다르기 때문에 앞과 같은 방법을 사용했다.
SOLID 원칙을 생각해 보면, NaverScrapper는 Scrapper와 같은 역할을 가지므로 SRP는 조금 애매하다. 그러나 crawl() method는 Scrapper에서 처리하고, NaverScrapper는 네이버 블로그의 DOM tree를 파싱만 하므로 SRP를 만족하는 것 같다. 다른 종류의 SectionParser를 추가하기 위해서는 SectionParser의 구현체를 생성자에만 추가하면 되므로 OCP도 만족하는 것 같다. abstract class인 SectionParser에 의존하므로 DIP도 만족한다. NaverScrapper는 Scrapper의 자리에 들어가 사용될 수 있기 때문에 LSP 또한 만족한다. ISP는 해당 사항이 없다.
디자인 패턴으로는 SectionParser를 사용하므로 Template method pattern을 사용하고, 블로그 종류에 따라 다른 BlogScrapper abstract class의 derived class를 호출해 URL을 처리하므로 Strategy pattern을 사용한다.
public class NaverScrapper extends BlogScrapper {
private static Map<String, SectionParser> parserMap = new HashMap<>();
private static final String DEFAULT = "";
static{
initializeParserMap();
}
private static void initializeParserMap(){
parserMap.put("table", new TableParser());
parserMap.put("quotation", new QuotationParser());
parserMap.put("text", new TextParser());
parserMap.put("code", new CodeParser());
parserMap.put("image", new ImageParser());
parserMap.put("horizontalLine", new HorizontalLineParser());
parserMap.put("oglink", new OglinkParser());
parserMap.put(DEFAULT, new DefaultParser());
// Append other [naver blog section name to StyleType mapping] here
}
@Override
protected BlogPost parse(Document document) throws Exception {
Elements post = extractPost(document);
String title = extractTitle(post);
Element content = extractContent(post);
ConvertedTreeNode root = parseToTree(content);
return new BlogPost(title, root);
}
private ConvertedTreeNode parseToTree(Element curElement){
ConvertedTreeNode rootNode = ConvertedTreeNode.builder().type(StyleType.NONE).build();
for(Element child : curElement.children()){
Element sectionElement = child.child(0).child(0);
if(isSection(sectionElement)){
SectionParser sectionParser = getSectionParser(getSection(sectionElement));
ConvertedTreeNode sectionNode = sectionParser.parseToTreeNode(sectionElement);
rootNode.appendChild(sectionNode);
}
}
return rootNode;
}
private static final Pattern sectionPattern = Pattern.compile("se-section se-section-([A-za-z]*)");
private Boolean isSection(Element element){
Matcher sectionMatcher = sectionPattern.matcher(element.className());
if(sectionMatcher.find()) return true;
return false;
}
private String getSection(Element element){
Matcher sectionMatcher = sectionPattern.matcher(element.className());
if(sectionMatcher.find()){
return sectionMatcher.group(1);
}
return DEFAULT;
}
private SectionParser getSectionParser(String section){
return parserMap.getOrDefault(section, parserMap.get(DEFAULT));
}
...
}코드는 위와 같으며 다음 링크에서 열어볼 수도 있다. NaverScrapper 코드
고민했던 점
// Inherit this abstract class to parse other types of naver blog sections.
public abstract class SectionParser {
abstract public ConvertedTreeNode parseToTreeNode(Element element);
// Regular expression filtering [se-text-paragraph se-text-paragraph-{ALIGN-TYPE}] format
private static final Pattern paragraphPattern = Pattern.compile("se-text-paragraph se-text-paragraph-align-([A-za-z]*)");
private static Map<String, StyleType> styleMap = new HashMap<>();
static{
initializeStyleMap();
}
private static void initializeStyleMap(){
styleMap.put("", StyleType.PARAGRAPH_DEFAULT);
styleMap.put("right", StyleType.PARAGRAPH_RIGHT);
styleMap.put("justify", StyleType.PARAGRAPH_LEFT);
styleMap.put("center", StyleType.PARAGRAPH_CENTER);
styleMap.put("a", StyleType.LINK);
styleMap.put("b", StyleType.BOLD);
styleMap.put("i", StyleType.TILT);
styleMap.put("u", StyleType.UNDERLINE);
styleMap.put("strike", StyleType.STRIKE);
// Append other [naver blog style to StyleType mapping] here
}
protected ConvertedTreeNode parseTextModule(Element textModule) { // se-module-text
ConvertedTreeNode textNode = ConvertedTreeNode.builder().type(StyleType.TEXT).build();
for(Element textParagraph : textModule.children()){ // se-text-paragraph
String align = getAlignFromElement(textParagraph);
StyleType alignType = getAlignTypeFromMap(align);
ConvertedTreeNode paragraphNode = parseTextParagraph(textParagraph, alignType);
textNode.appendChild(paragraphNode);
}
return textNode;
}
private ConvertedTreeNode parseTextParagraph(Element textParagraph, StyleType alignType){
ConvertedTreeNode paragraphNode = ConvertedTreeNode.builder().type(alignType).build();
for(Element spanElement : textParagraph.children()){
paragraphNode.appendChild(parseSpanElementToTreeNode(spanElement));
}
return paragraphNode;
}
// span 이하 element들에 대해 DFS 이후 tagname을 style로 지정한 tree node return
private ConvertedTreeNode parseSpanElementToTreeNode(Element element){
StyleType styleType = getTextStyleFromMap(element.tagName());
if(element.childrenSize() == 0){
String content = element.text();
return ConvertedTreeNode.builder().type(styleType).content(content).build();
}
ConvertedTreeNode curNode = ConvertedTreeNode.builder().type(styleType).build();
for(Element child : element.children()){
curNode.appendChild(parseSpanElementToTreeNode(child));
}
return curNode;
}
private String getAlignFromElement(Element textParagraph){
Matcher paragraphMatcher = paragraphPattern.matcher(textParagraph.className());
if(paragraphMatcher.find()){
return paragraphMatcher.group(1);
}
return "";
}
private StyleType getAlignTypeFromMap(String align){
return styleMap.getOrDefault(align, StyleType.PARAGRAPH_DEFAULT);
}
private StyleType getTextStyleFromMap(String style){
return styleMap.getOrDefault(style, StyleType.CONTENT);
}
}위 코드는 SectionParser 코드의 일부분이며, 다음 링크에서 열어볼 수 있다. SectionParser 코드
사실상 리팩토링하면서 제일 힘들었던 부분이고, 마땅히 좋은 해결책을 찾지 못해서 조금 맘에 들지 않는다.
네이버 블로그의 HTML 구조는 다음과 같다.
- se-main-container # main text
- se-component se-[TYPE]
- se-component-content
- se-section se-section-[TYPE]
- se-module se-module-text # text
- se-text-paragraph # paragraph
- se-module se-module-code # source code
- se-code-source
- __se_code_view
- se-module se-module-image # image
se-module se-module-text se-caption # image caption
- se-module se-module-horizontalLine # horizontal line
- se-module se-module-oglink # auto generated shortcut
- se-quotation-container # quotation container
- se-module se-module-text se-quote # quote
- se-module se-module-text se-cite # cite
- se-table-container # table container
- se-table-content # table body[se-main-container - se-component se-type - se-component-content - se-section se-section-type] 이후에 module이 오는 형태인데, image module의 경우 se-section 아래에 se-module-image와 se-module-text가 같이 오기 때문에, 글의 구성요소를 section으로 판정해야만 했다. 문제는 이미지 캡션, 인용구, 표의 각 셀 등 모든 평문이 들어가는 부분은 se-module-text로 구성되어 있다는 것이다. 즉, TextParser가 TableParser나 ImageParser 내부에 들어가야 한다. SectionParser interface의 구현체에 TextParser가 들어가야 하는 것인데... 네이버 블로그 HTML의 구성상 의존성이 있는 것은 맞지만, 이것이 너무 마음에 들지 않아서 다른 방법을 생각했다.
내가 제시한 방법은 TextModule을 파싱하는 부분이 공통으로 사용되므로, SectionParser를 abstract class로 바꾸는 것이었다. 때문에 SectionParser는 각 section을 파싱하는 parseToTreeNode() method를 강제함과 동시에 text module을 파싱하는, 2가지 역할을 가지게 된 것이다.
디자인 패턴으로는 딱히 적용된 게 없다. Strategy patten이 적용된 것 같은데, 구현이 encapsulation되지 않았기 때문에 그렇다고 볼 수 없다. Template method pattern은 맞다고 볼 수 있다. SectionParser의 derived class들이 parseToTreeNode()의 동작을 다르게 구현하기 때문이다.
SOLID 원칙을 생각해 보면, SectionParser는 abstract class의 역할과 text module을 파싱하는 역할 2개를 수행하므로 SRP는 만족하지 않는 것 같다. 이를 위배한 이유는 위와 같이 설명했지만, 더 좋은 방법을 찾지 못한 것이 아쉽다. 이외에 다른 OCP, LSP, ISP, DIP는 딱히 해당사항 없는 것 같다.
AuthClient & Converter
AuthClient
앞서 [공통 형식]을 목적지 블로그에 맞는 형식으로 변환하는 역할을 Converter가 한다고 했다. Converter를 살펴보기 전에 먼저 AuthClient부터 살펴보겠다.

// Implement this interface to post other types of blogs.
public interface AuthClient {
/**
* Authorize to upload post
*/
public void authorize() throws Exception;
/**
* Upload post in each blog.
* @param title : post title
* @param content : post content
*/
public void post(String title, String content) throws Exception;
}AuthClient는 authorize()와 post() 2개의 method만 가진다.
디자인 패턴으로는 딱히 적용된 것이 없다.
SOLID 원칙을 생각해 보면, AuthClient는 [목적지 블로그의 API를 사용한다]는 역할만 수행하므로 SRP를 만족하는 것 같다. AuthClient의 구현체는 AuthClient를 수정하지 않고 interface method를 구현해야 하므로 확장할 수 있기 때문에 OCP도 만족하는 것 같다. interface를 사용하므로 DIP도 만족하는 것 같다. LSP나 ISP는 해당 사항 없는 것 같다.
Converter
다음으로 Converter를 살펴보자. Converter는 BlogPost를 받아 목적지 블로그 형식으로 변환한다. 오직 하나의 함수만 있으면 되므로 interface로 이를 구현했다.
// Implement this interface to convert ConvertedTreeNode to other types of blogs.
public interface Converter {
public String convert(BlogPost blogPost);
}
TistoryConverter는 Converter의 구현체로, 입력으로 받은 BlogPost를 Tistory 형식으로 변환한다. 일단 눈여겨 볼 점은 TistoryClient에 의존하고 있다는 것인데, 이는 조금 이따 설명하겠다.
TistoryConverter는 ConvertedTree의 root부터 특정 StyleType이 나오면 해당 TypeConverter를 호출한다.
ConvertResultVO는 변환 결과 Element와 다음으로 탐색할 ConvertedTreeNode list 2개의 attribute를 가진다.
디자인 패턴으로는 TistoryConverter는 TypeConverter를 생성하므로 Template method pattern을 사용하고, StyleType에 따라 다른 TypeConverter interface의 구현체를 호출해 URL을 처리하므로 Strategy pattern을 사용한다.
SOLID 원칙을 생각해 보면, TistoryConverter는 [BlogPost의 ConvertedTree root를 String으로 변환한다]는 역할만 수행하므로 SRP를 만족하는 것 같다. TistoryConverter의 생성자만 수정하면 다른 종류의 TypeConverter를 추가할 수 있기 때문에 OCP도 만족하는 것 같다. interface에 의존하고 있기 때문에 DIP도 만족하는 것 같다. LSP는 해당 사항 없는 것 같고, TypeConverter interface의 모든 method를 사용하므로 ISP도 만족하는 것 같다.
public class TistoryConverter implements Converter {
private TistoryClient tistoryClient;
private static Map<StyleType, TypeConverter> converterMap = new HashMap<>();
public TistoryConverter(TistoryClient tistoryClient){
this.tistoryClient = tistoryClient;
initializeConverterMap();
}
private void initializeConverterMap(){
converterMap.put(StyleType.TABLE, new TableConverter());
converterMap.put(StyleType.ROW, new RowConverter());
converterMap.put(StyleType.COLUMN, new ColumnConverter());
converterMap.put(StyleType.QUOTATION, new QuotationConverter());
converterMap.put(StyleType.PARAGRAPH_DEFAULT, new DefaultParagraphConverter());
converterMap.put(StyleType.PARAGRAPH_LEFT, new LeftParagraphConverter());
converterMap.put(StyleType.PARAGRAPH_RIGHT, new RightParagraphConverter());
converterMap.put(StyleType.PARAGRAPH_CENTER, new CenterParagraphConverter());
converterMap.put(StyleType.CONTENT, new ContentConverter());
converterMap.put(StyleType.LINK, new LinkConverter());
converterMap.put(StyleType.BOLD, new BoldConverter());
converterMap.put(StyleType.TILT, new TiltConverter());
converterMap.put(StyleType.UNDERLINE, new UnderlineConverter());
converterMap.put(StyleType.STRIKE, new StrikeConverter());
converterMap.put(StyleType.CODE, new CodeConverter());
converterMap.put(StyleType.IMAGE, new ImageConverter(tistoryClient));
converterMap.put(StyleType.HORIZONTALLINE, new HorizontalLineConverter());
converterMap.put(StyleType.NONE, new DefaultConverter());
// Append other TypeConverter implements here
}
@Override
public String convert(BlogPost blogPost) {
Element convertedElement = traverseAndConvert(blogPost.getRoot());
return encodeToUTF8(convertedElement.outerHtml());
}
private Element traverseAndConvert(ConvertedTreeNode curNode){
TypeConverter typeConverter = getTypeConverter(curNode.getType());
ConvertResultVO convertResult = typeConverter.convertAndReturnNextNodes(curNode);
Element curElement = convertResult.getResult();
for(ConvertedTreeNode nextNode : convertResult.getNextNodes()){
Element nextElement = traverseAndConvert(nextNode);
curElement.appendChild(nextElement);
}
return curElement;
}
private TypeConverter getTypeConverter(StyleType supportType){
return converterMap.getOrDefault(supportType, converterMap.get(StyleType.NONE));
}
private String encodeToUTF8(String origin){
try{
return Utils.encodeToUTF8(origin);
}
catch(Exception e) {
Utils.printMessage(e.getMessage() + " 인코딩을 취소합니다.");
}
return origin;
}
}위 코드는 TistoryConverter 코드의 일부분이며, 다음 링크에서 열어볼 수 있다. TistoryConverter 코드
TypeConverter 코드는 아래와 같고, TypeConverter의 구현체들은 딱히 특이한 내용이 없으므로 생략하겠다.
// Implement this interface to convert other kind of StyleTypes.
public interface TypeConverter {
abstract public ConvertResultVO convertAndReturnNextNodes(ConvertedTreeNode node);
public static String convertContent(String content){
return content.isEmpty() ? System.lineSeparator() : content;
}
}
고민했던 점 - interface + static method
TypeConverter의 경우 static method를 사용했는데, ConvertedTreeNode를 변환할 때 content를 변환하는 로직은 모두 공통이기 때문이다. BlogScrapper나 SectionParser의 경우 이 경우와 같이 공통 로직이 있어 abstract class를 사용했다. 그러나 TypeConverter의 경우 interface를 쓰고 공통 로직에 static method를 사용했다.
Java의 경우 상속은 좋은 기능이지만 class 간 의존관계가 명확해지고, 다중상속이 허용되지 않기 때문에 class hierarchy보다는 interface를 사용하는 것이 좋다고 생각한다. 따라서 class hierarchy를 최소한으로 만들어야 했다.
그럼에도 불구하고 BlogScrapper나 SectionParser를 abstract class로 만든 이유는 공통 멤버 변수가 필요했기 때문이었다. BlogScrapper는 에러 메시지 처리를 위해 errorMessages, SectionParser는 평문의 스타일을 매핑한 styleMap을 사용했는데, 만약 interface로 사용하면 이들의 초기화 함수를 생성자에 넣는 과정을 implement할 때마다 추가해야 한다. 이는 번거로운 과정이며, 컴파일러가 경고하지 않기 때문에 초기화 함수를 구현했더라도 생성자에 넣지 않을 수 있기 때문에 초기화가 올바르게 되지 않을 가능성이 더 크다고 생각해 abstract class로 구현했다.
반면 TypeConverter의 경우 이러한 과정이 필요 없다. 단순히 input에 대해 비었는지 검사하고 없으면 System.lineSeparator()를 호출하는 함수가 필요했을 뿐이기에 interface + static method로 구현했다.
Migrator
Migrator는 사용자 입력을 받고, migration 작업을 수행하는 class이며, 각 module들을 조립한다. 제일 큰 class이며, 각 module
UrlProcessor나 Scrapper는 URL에 해당하는 BlogType에 따라 다른 구현체를 호출해야 하지만, 이 각각의 로직은 UrlProcessor와 Scrapper 내부에서 처리하므로 Migrator는 이 class들만 부르면 된다.
디자인 패턴으로는 TargetBlogConfigFactory를 사용하므로 Template method pattern을 사용하고, 목적지 블로그 종류에 따라 다른 TargetBlogConfigFactory의 구현체를 호출해 처리하므로 Strategy pattern을 사용한다.
SOLID 원칙을 생각해 보면, Migratior class는 Migrator 작업을 담당하므로 SRP를 만족한다고 볼 수 있지만, 사용자 입력과 파일 파싱, 모든 module 호출 등 여러 가지를 수행하므로 좀 애매하다. OCP는 만족하는데, 새로운 목적지 블로그가 추가되면 해당 TargetBlogConfigFactory만 구현하면 되기 때문이다. TargetBlogConfigFactory나 AuthClient, Converter를 사용하므로 ISP는 만족하고, LSP는 해당되는 부분이 없다. DIP는 반만 준수하는데, AuthClient나 Converter는 interface인 반면 UrlProcessor와 Scrapper는 concrete class이기 때문이다.
비록 DIP를 준수하지는 않지만 UrlProcessor나 Scrapper는 추상화 수준이 매우 높기 때문에 변경되지 않을 가능성이 농후하다. 때문에 유지보수에는 문제가 없을 것이라 예측된다.
public class Migrator {
private final UrlProcessor urlProcessor = new UrlProcessor();
private final Scrapper scrapper = new Scrapper();
private AuthClient authClient;
private Converter converter;
private final List<BlogType> targetBlogTypes = new ArrayList<>();
private final Map<BlogType, TargetBlogConfigFactory> targetBlogConfigFactoryMap = new HashMap<>();
public Migrator(){
targetBlogTypes.add(BlogType.NONE);
targetBlogTypes.add(BlogType.TISTORY);
// append other target blog types here
targetBlogConfigFactoryMap.put(BlogType.TISTORY, new TistoryConfigFactory());
// append other target blog factories here
}
public void migrate(){
BlogType targetBlogType = getTargetBlogType();
configureTargetBlog(targetBlogType);
List<String> urls = loadUrlList();
Utils.printMessage("[작업 시작] 작업을 시작합니다.");
for(String url : urls){
Utils.printMessage("[작업 중] : " + url);
migratePost(url);
}
Utils.getInput("[작업 완료] 작업을 완료했습니다. 프로그램을 종료합니다.");
}
private BlogType getTargetBlogType(){
Utils.printMessage("==============================");
printTargetBlogTypes();
Utils.printMessage("==============================");
String input = Utils.getInput("업로드할 블로그를 선택하세요. 종료를 원하면 0을 입력하세요.");
BlogType targetBlogType = parseInput(input);
if(targetBlogType == null){
Utils.getInput("지원하지 않는 블로그 유형입니다. 프로그램을 종료합니다.");
System.exit(1);
}
if(targetBlogType == BlogType.NONE){
Utils.getInput("사용자 입력으로 프로그램을 종료합니다.");
System.exit(1);
}
return targetBlogType;
}
private void configureTargetBlog(BlogType targetBlogType){
TargetBlogConfigFactory targetBlogConfigFactory = getTargetBlogConfigureFactory(targetBlogType);
if(targetBlogConfigFactory == null){
Utils.getInput("지원하지 않는 블로그 유형입니다. 프로그램을 종료합니다.");
System.exit(1);
}
this.authClient = targetBlogConfigFactory.createAuthClient();
this.converter = targetBlogConfigFactory.createConverter(this.authClient);
if(this.authClient == null || this.converter == null){
Utils.getInput("[오류 발생] 초기화 중 오류가 발생해 프로그램을 종료합니다.");
System.exit(1);
}
}
private TargetBlogConfigFactory getTargetBlogConfigureFactory(BlogType targetBlogType){
if(targetBlogConfigFactoryMap.containsKey(targetBlogType)){
return targetBlogConfigFactoryMap.get(targetBlogType);
}
return null;
}
private void migratePost(String url){
try{
BlogPost blogPost = scrapper.scrap(urlProcessor.process(url));
String title = blogPost.getTitle();
String convertedContent = converter.convert(blogPost);
authClient.post(title, convertedContent);
}
catch(Exception e){
Utils.printMessage(e.getMessage() + " " + url);
}
}
}위 코드는 Migrator 코드의 일부분이며, 다음 링크에서 열어볼 수 있다. Migrator 코드
고민했던 점 - TistoryClient에 의존하는 TistoryConverter
티스토리의 포스트 구조를 보면 이미지는 첨부 파일의 형식으로 올린 후 해당 첨부 파일을 미리 보는 replacer라는 것을 사용해 이미지를 표시한다. 따라서 이미지를 업로드하기 위해 Tistory API를 사용하는 TistoryClient에 의존해야만 했다. 반면 Migrator에서는 Converter와 AuthClient만 호출하는 상황이고, Converter와 AuthClient는 직접적으로 의존관계가 없다. 의존관계는 TistoryConverter와 TistoryClient에만 있다.
이를 해결하기 위해 Factory method pattern을 사용했다.

Abstract factory pattern을 사용한다. UrlProcessor나 Scrapper는 URL에 해당하는 BlogType에 따라 다른 구현체를 호출해야 하지만, 목적지 블로그는 하나이므로 Converter와 AuthClient는 구현체를 바로 불러오면 된다. 이 때 TistoryConverter와 TistoryClient의 명시적인 의존성을 줄이기 위해 Abstract factory pattern을 사용했다.
public interface TargetBlogConfigFactory {
public AuthClient createAuthClient();
public Converter createConverter(AuthClient authClient);
}public class TistoryConfigFactory implements TargetBlogConfigFactory {
@Override
public AuthClient createAuthClient() {
try{
return new TistoryClient();
}
catch(Exception e){
Utils.printMessage(e.getMessage());
}
return null;
}
@Override
public Converter createConverter(AuthClient authClient) {
try{
return new TistoryConverter((TistoryClient) authClient);
}
catch(Exception e){
Utils.printMessage(e.getMessage());
}
return null;
}
}
테스트 코드

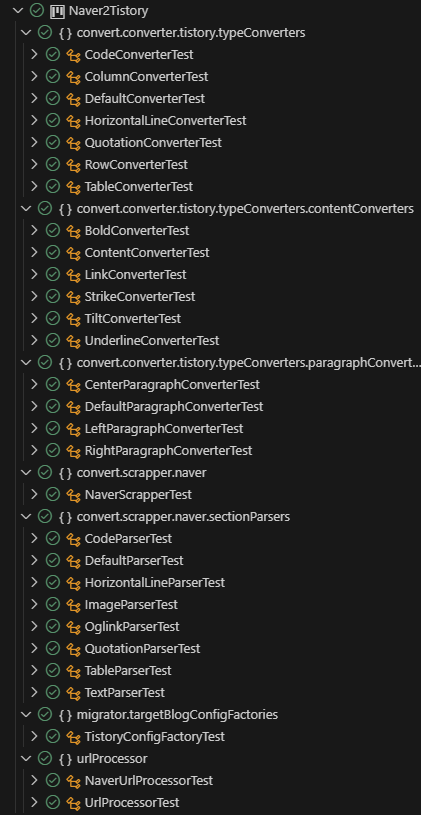
TistoryClient가 들어있는 부분 빼고는 가능한 한 많은 module들에 unit test code를 작성했다.
coverage를 측정하고 싶은데 순수 java 프로젝트는 jacoco test coverage를 확인할 수가 없어서, 임시로 maven 프로젝트를 하나 만들고 그 내부에서 jacoco coverage를 돌렸다. 패키지 앞의 aaaa.는 임시로 붙여둔 거니까 무시하고 생각하면 된다.

직접 API 통신을 해야 하는 auth 패키지, 전체를 통합하는 migrator 패키지, http 연결 등이 있는 util 패키지를 제외하고는 85%의 커버리지가 나온다. 낮게 나온 3가지 패키지를 확인해 보자.
scrappers 패키지



직접 블로그에서 scrap하는 동작이 없기 때문에 전체가 coverage 0%로 나온다. `BlogScrapper.java`는 오류 부분만 빨간 줄.
음.. 내가 작성한 것은 unit test고, 이쪽은 통합 테스트 쪽에 가까워서.. 추후 시간이 나면 통합 테스트를 작성하는 식으로 가야 하나 고민이 된다.
tistory 패키지 - TistoryConverter

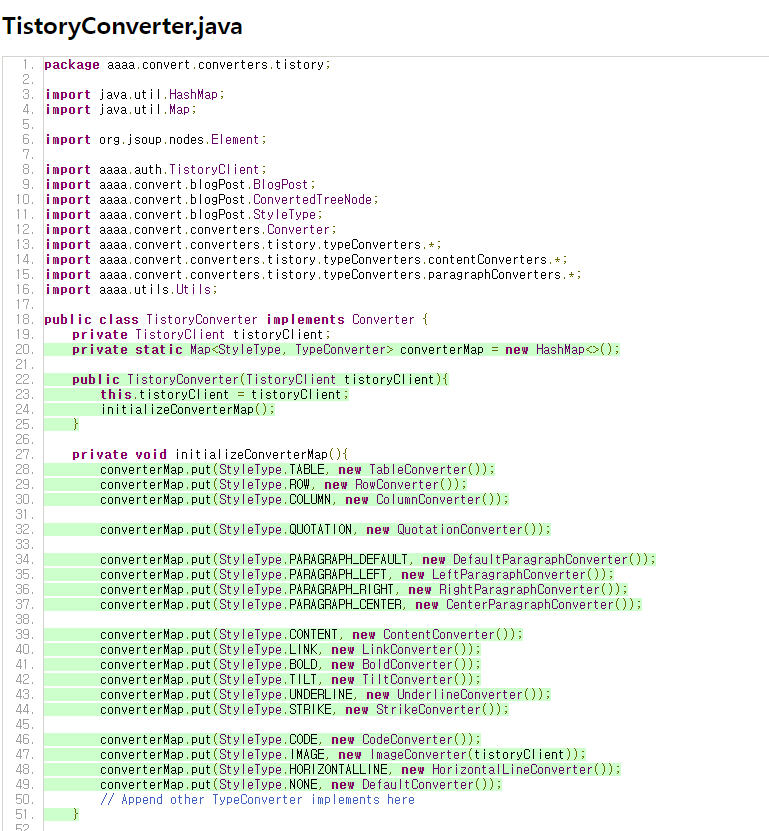
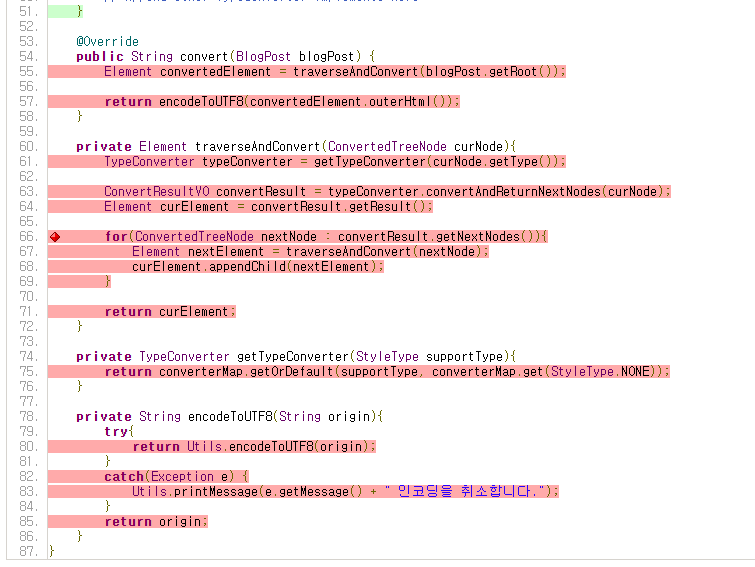
TypeConverter 패키지는 3항 연산자에서 하나를 확인 안해서 71%이고, `TistoryConverter.java`의 경우 위와 마찬가지로 통합 테스트가 없다보니 `convert()`가 호출되지 않아서 그런 듯 하다.
tistory.typeConverter
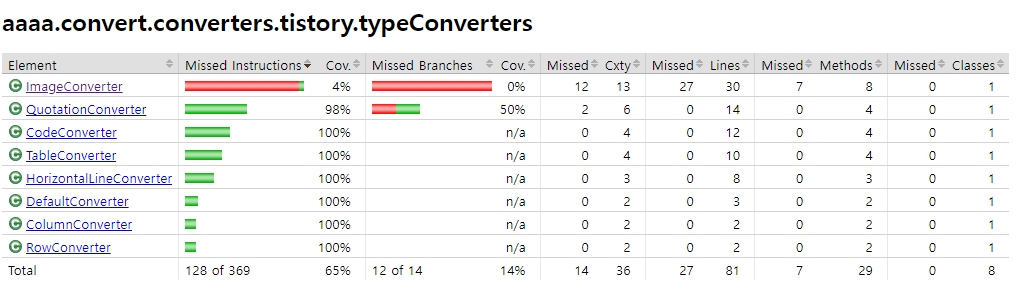

`ImageConverter`만 매우 낮게 나오는데, 다른 converter들은 string을 입력으로 받는 테스트 케이스를 작성했는데, image는 테스트 코드에 resource를 할당하지 않았기 때문이다. 그래서 동작만 확인해서 밑에 다 빨간 줄 나는 것 같다.
총평
시간이 나면 통합 테스트를 작성해서 전체 커버리지를 올릴 수 있도록 하는 게 좋을 것 같다.
후기
이렇게 모든 리팩토링한 내용을 살펴봤다. 코드를 짜면서 Clean Code를 읽으면서 느꼈던 읽기 좋은 코드, Clean Architecture를 읽으면서 느꼈던 유지보수하기 좋은 코드, SOLID principles를 보면서 배웠던 점들을 최대한 적용하려 고민했고, 그 결과로 마음에 드는 부분도, 배운 것도 많은 과정이었다.
목표 달성?
리팩토링을 시작했을 때 아래와 같은 4가지를 달성하고자 했었다.
- 주석 삭제. 의도를 설명한 주석, 유지보수 시 참고가 될 만한 주석만 남기고 모두 삭제. JavaDoc은 필요한 public 함수에만 남기고자 했다.
- 예외처리를 간소하게. 곳곳에 퍼져 있는 try-catch문을 응집시키고자 했다.
- 최대한 의존성을 줄이고 확장성 있게 코드를 작성하고자 했다.
- 이 프로그램은 Naver2Tistory이지만 추후에 Naver2Notion처럼 목적지 블로그를 추가할 수도 있고, Medium2Tistory처럼 출발지 블로그를 추가할 수도 있다고 가정했다.
- 현재 지원하는 스타일 이외에 다른 스타일들이 추가될 수 있다고 가정했다.
- 의존성을 줄이기 위해서 interface나 abstract class를 사용하고, if-else문을 줄이기 위해 map을 사용하는 방식을 채택했다.
- 테스트 코드 작성. 사용자 아이디/패스워드가 필요한 TistoryClient와 TistoryClient를 사용하는 class를 제외하고는 최대한 unit test를 진행하고자 했다.
일단 필요없는 주석들은 대부분 지웠고, 주석은 최대한 지우되 유지보수하는 사람의 입장에서 필요한 부분에만 남기고자 했다. 예를 들면 interface의 구현체를 어디에 추가하면 되는지 등등.
try-catch문도 상당히 응집시켰다. UrlProcessor, Scrapper, Converter, AuthClient들은 모두 Exception을 던지기만 하고, 이 module을 직접적으로 사용하는 TargetBlogConfigFactory와 Migrator에서 모든 Exception들을 받아 처리하게 만들었다.
interface, abstract class 등을 다양하게 사용해 의존성을 줄였고, strategy pattern을 사용해 확장하기 쉬운 코드를 작성했다.
테스트 코드도 작성했다!
초기에 설정한 목표들은 모두 달성한 것 같다.
배운 점들
interface와 abstract class의 사용 구분
일단 배운 점들 중 하나는 언제 interface/interface + static method/abstract class를 사용하는지 나름의 철학이 생겼다는 것이다.
- 일단 interface를 사용하고
- 공통 함수만 필요한 경우 static이나 default를 사용하고
- 만약 static으로 처리할 수 있는 변수면 interface를 사용한다.
- 만약 abstract class를 사용하는 것이 유지보수에 이점이 있다고 판단하면 abstract class를 사용한다.
- 멤버 변수가 필요한 경우 abstract class를 사용한다.
strategy pattern
다음으로 배운 것은 Strategy pattern이었다. 사용하면 코드 복잡도가 올라간다는 단점이 있지만, 유지보수가 매우 쉬워지고 시간복잡도가 O(n)인 if-else문에 비해 map을 사용하면 O(logn)으로 처리할 수 있다는 시간적 이점도 있었다.
한편, template method pattern과 abstract factory pattern도 사용했는데 이 둘의 차이점에 대해서도 알아야 할 것 같다.
template method pattern은 사실상 interface 구현체나 abstract class의 상속을 사용한 polymorphism을 사용하는 기법이고, abstract factory pattern은 object를 생성하는 기법이다... 이 정도.
느낀점
이렇게 확장성과 유지보수성을 신경쓰면서 코드를 짜니 닥치는 대로 구현하는 방식보다 배는 많은 시간이 들어갔다. 특히 초반에 설계 부분에서 많은 시간이 걸렸다. 그러나 이렇게 구조화하면서 짜니, 처음 설계가 어려웠지 코드 구현은 생각한 대로 쭉쭉 짜졌다. 물론 중간에 생각치 못했던 여러 이슈들이 있었지만(고민했던 점들) 모듈화가 잘 되어 있었기에 이들을 해결하기 쉬웠다.
또 하나 느낀 점은, unit test code를 꼭 작성해야 한다는 것이다. unit test를 실행함으로써 해당 module이 잘 작동한다는 것을 바로바로 알 수 있었기 때문에 테스트에 걸리는 시간이 확 줄게 되었다. 아무리 처음에 설계를 잘 짜더라도 구조를 조금씩 조금씩 바꿔가는 일이 무조건 생겼는데 unit test로 인해 원래 작동하던 것이 잘 작동함을 보장받으니 마음이 너무 편했다. 처음에 만드는 것은 귀찮았지만...
또, module을 쓰고 바로바로 테스트 코드를 돌리면서 결과를 볼 수 있었어서 더 좋았던 것 같다.
'Project > Project N2T' 카테고리의 다른 글
| [N2T] Naver2Tistory 리팩토링 시작 (0) | 2023.03.22 |
|---|---|
| [N2T] Tistory Open API 앱 등록 (0) | 2022.09.15 |
| [N2T] 네이버 에디터와 티스토리 에디터 분석 (0) | 2022.08.15 |
| [N2T] N2T - 네이버 블로그 이사 프로그램 (2) | 2022.08.15 |