![[개발서적] Clean Architecture 정리](https://img1.daumcdn.net/thumb/R750x0/?scode=mtistory2&fname=https%3A%2F%2Fblog.kakaocdn.net%2Fdn%2Fb24ufD%2Fbtr5Q4wgKF9%2FK7HO1Tbr9WTxAmKdEUKKN1%2Fimg.png)
Clean Code, The Pragmatic Programmer에 이어 Clean Architecture를 읽었다. Clean Architecture는 처음부터 끝까지 의존관계를 줄이는 방법을 소개하며 이를 통해 Open Closed Principle을 만족하는 유연한 프로그램을 작성하는 방법을 알려준다. 아직까지 느낀 점은 결국 중복을 없애고 DIP를 통해 추상화에 의존하게 작성하면 그것이 좋은 구조다는 것이다. 처음부터 끝까지 dependency에 관해 일관성 있게 이야기하기 때문에 하나 이상의 개발 프로젝트를 진행했던 개발자라면 자신이 진행했던 프로젝트의 구조와 dependency를 생각해 보는 계기가 될 것이다.
앞선 포스팅과 마찬가지로 감명깊게 읽은 부분, 필요하다고 생각하는 부분, 중요하다고 생각하는 부분만 간단하게 정리했다.
Ch 1. 설계와 아키텍처란?
이 장에서는 설계와 아키텍처에 대한 필요성을 다룬다.
소프트웨어는 변경하기 쉬워야 한다.
이 책이 대전제로 설정하는 목적이다. 이 대전제를 달성하기 위한 주 방법이 의존성을 낮추는 방법이며 주로 Dependency Inversion Principle을 이용해 이 목적을 달성한다.
코드는 나중에 정리하면 돼. 당장은 시장에 출시하는 게 먼저야!라는 흔해 빠진 거짓말에 속는다.
이렇게 속아 넘어간 개발자라면 나중에 코드를 정리하는 경우는 한 번도 없는데, 시장의 압박은 절대로 수그러들지 않기 떄문이다.
개발자로서 지켜야 할 것들 중 하나. 시장의 압박은 절대로 수그러들지 않는다는 말이 크게 와닿았다. 따라서 언제나 코드를 깔끔하게 정리해야 한다.
효율적인 SW 개발팀은 뻔뻔함을 무릅쓰고 다른 이해관계자들과 동등하게 논쟁한다. 소프트웨어 개발자인 당신도 이해관계자임을 명심하라. 당신은 소프트웨어를 안전하게 보호해야 할 책임이 있다.
개발자는 개발하는 것이 주 업무이다. 개발 효율성이 높아야만 요구사항을 빠르게 반영할 수 있고, 고객을 만족시킬 수 있다. 따라서 개발자는 개발 효율성을 언제나 높게 유지해야 할 것이며 이것이 개발자의 주 업무이다.
Ch 2. 벽돌부터 시작하기: 프로그래밍 패러다임
프로그래밍 패러다임은 procedural - object oriented - functional 순으로 발전해 왔다. 각 패러다임은 무엇을 해서는 안 되는지 강조하여 이에 대한 추가 규칙을 부여한다.
- procedural programming은 flow of control의 직접적인 전환에 부과되는 규칙이다. (goto 금지)
- object-oriented programming은 flow of control의 간접적인 전환에 부과되는 규칙이다. (polymorphism)
- functional programming은 변수 할당에 부과되는 규칙이다. (immutable variable)
객체지향 Object-Oriented
객체지향 프로그래밍 포스트에서 object oriented programming의 4가지 특징인 abstraction, encapsulation, inheritance, polymorphism을 살펴봤었다. 그러나 이 책은 이 특징에 대해 부정한다.
- abstraction은 일반화를 통해 공통된 속성이나 행위를 추출해 세부 구현을 숨기고 중요한 정보만을 보여주는 것이다. 그러나 이는 procedural programming에서도 구현 가능하다.
- encapsulation은 데이터와 함수를 숨기는 것이다. 그러나 procedural 언어는 header 파일에 method와 데이터 형식을 기술하는데, 이를 통해 encapsulation이 가능하다.
- inheritance는 존재하는 class로부터 새로운 class를 생성하는 것이다. c언어의 struct 안에 struct를 넣는 방법이나, 코드를 복사+붙여넣기 하는 방식으로 상속을 구현할 수 있긴 했다. 그러나 object-oriented는 이를 편리한 방식으로 확실히 제공한다.
- polymorphism은 object-oriented만의 특징이다. c언어의 경우 pointer를 이용해 polymorphism 함수에 접근한다. 그러나 이는 잘못된 메모리에 접근할 가능성이 매우 크기 때문에 매우 위험한 방식이다. 그러나 object-oriented는 function pointer 없이 함수에 접근할 수 있다.
따라서 polymorphism이 object-oriented의 가장 강력한 힘이라 설명한다.

polymorphism이 존재하기 전에는 위 그림처럼 소스코드의 dependency가 flow of control을 무조건적으로 따르게 되었다.

그러나 polymorphism의 등장으로 dependency와 flow of control이 반대가 된다. Dependency Inversion Principle 포스팅에서도 소개한 것과 같이 기존 방식과는 다르게 dependency와 flow of control이 반대가 되므로 이를 dependency inversion이라 부른다.
이를 이용해 추상화 수준이 높은 business logic에 세부사항(UI나 DB 등)이 의존하게 만들 수 있다. 즉 세부사항이 business login의 plug-in이 되는 것이다! UI나 DB 등 세부사항의 변경사항은 busniess login에 영향을 줄 수 없다.(dependency가 없기 때문에) 그러나 그 역은 성립한다.
이에 대해 책은 다음과 같이 설명한다.
polymorphism을 이용해 시스템의 소스 코드 의존성 전부에 대해 방향을 결정할 수 있는 절대적인 권한을 얻는다.
함수형 Functional
functional programming에서 변수는 변경되지 않는다. 따라서 race condition, deadlock, concurrent update 문제 등 가변 변수로 인해 생기는 문제를 해결할 수 있다. 이 점에 착안하여 application 내부의 component를 가변 component와 불변 component로 분리하며, 불변 component에서는 가변 변수가 사용되지 않으며 가변 component와 통신한다.
Event sourcing
상태(데이터, 변수 값)이 아닌 transaction을 저장하자는 전략이다. 이후 데이터가 필요하다면 특정 시점부터 발생한 transaction을 모두 처리하는 방식으로 정보를 계산하는 방식이다.
그러나 이 방식을 사용하면 transaction 수가 계속 증가하고 따라서 계산에 필요한 computing resource도 무한해야 할 것이다. 이에 대한 차선택으로 매일 특정 시간에 전체 상태를 계산한 후 저장한다. 이전에 있었던 transaction은 백업하고, 그 시간을 [현재 시점]으로 잡고 불변 상태로 두면 된다.
Ch 3. 설계 원칙
이 장에서는 clean code를 만들기 위한 원칙인 SOLID principle을 소개한다. SOLID principle을 준수함으로써 이해하기 쉽고 유연한 프로그램을 작성할 수 있다. SOLID principle은 이미 앞선 포스팅에서 정리했으므로 정의만 짚고 넘어가겠다.
- Single Responsibility Principle : 모든 module은 단 하나의 책임을 갖는다. 따라서 변경의 이유가 단 하나여야 한다.
- Open Closed Principle : 기존 코드를 변경하지 않으면서 기능 변경 또는 확장할 수 있어야 한다.
- Liskov Substitution Principle : subtype은 항상 supertype으로 치환할 수 있어야 한다.
- Interface Segregation Principle : 사용하지 않는 것에 의존하지 않아야 한다.
- Dependency Inversion Principle : dependency를 가질 때 concretion이 아니라 abstraction에 의존해야 한다. 즉 세부사항이 business logic에 의존해야 한다.
SOLID Principle을 지키면 모든 component dependency는 단방향으로 이루어지며, 저수준 component가 고수준 component에 의존하게 된다. 따라서 저수준 component의 변경이 고수준 component에 영향을 주지 않는다.
stable software architecture는 변동성이 큰 concretion에 의존하지 않고, stable한 abstract interface를 선호한다.
이를 위해 abstract factory method 등을 사용한다. 이 경우 dependency는 모두 abstraction쪽으로 향한다. 아래 예시를 보자.
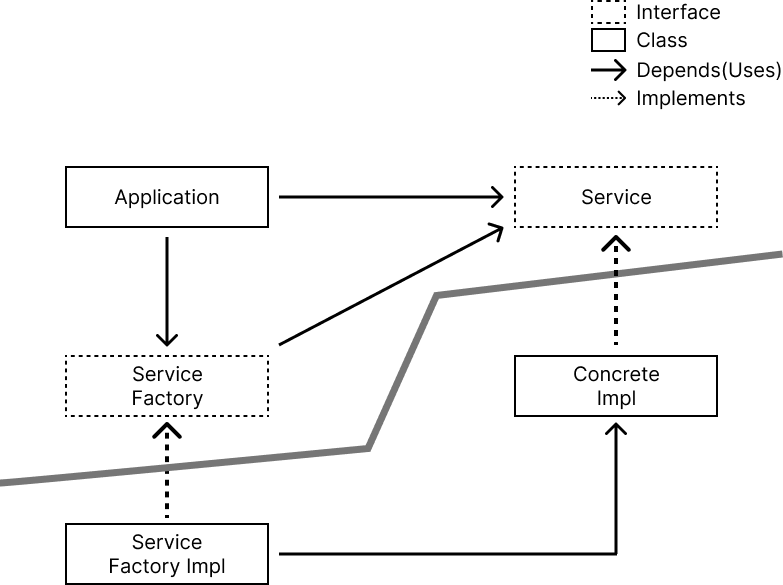
application은 ConcreteImpl을 사용하기 위해 Service interface를 사용한다. 이 때 어떻게든 ConcreteImpl을 생성해야 하는데, 직접 생성한다면 ConcreteImpl에 dependency를 가지게 된다. Dependency Inversion Principle 위반이다. 따라서 ServiceFactory interface를 만든다. ServiceFactory는 Service type으로 무언가를 리턴해 주며, 이를 구현하는 ServiceFactoryImpl에서 ConcreteImpl을 생성한 후 ConcreteImpl을 Service type으로 리턴한다.
이를 통해 application은 abstract component와 concrete component 2가지로 나뉘며, 소스 코드 dependency는 모두 abstraction쪽으로 향하게 된다.
이 때, ServiceFactoryImpl이 ConcreteImpl에 직접 의존한다. 이는 Dependency Inversion Principle 위반이지만, 모든 Dependency Inversion Principle 위반을 없앨 수는 없다. 따라서 Dependency Inversion Principle 위반 class를 concrete component 내부로 모으고 다른 부분과는 분리할 수 있으며, 보통 main에 모은다.
Ch 4. 컴포넌트 원칙
이 장에서는 component의 정의와 어떠한 원칙들을 지켜야 하는지, component dependency의 정량적 분석 방법을 소개한다.
component는 시스템의 구성 요소로 배포할 수 있는 가장 작은 단위이다.
이 책에서는 component를 위와 같이 정의한다.
소프트웨어 개발 초창기에는 프로그램이 메모리에 올라갈 위치를 프로그래머가 직접 지정했다. 이 방법의 경우 여러 개의 프로그램을 올리면 fragmentation이 계속 일어났다. 이에 대한 해결책으로 loader와 linker라는 개념이 생겼다. loader는 binary를 입력받은 후 memory에 load하면서 프로그램의 위치를 조절했다. 추가로 linking, binary 내부의 metadata를 이용해 external reference를 정의했고, 이를 link할 수 있었다. 소스코드가 컴파일 된 후 loader와 linker가 관리하는 방식으로 별다른 어려움 없이 component를 배포할 수 있게 되었다.
Component Cohesion Principles : REP, CCP, CRP
component cohesion을 높이기 위한 원칙 3가지.
REP : 재사용/릴리즈 등가 원칙 Reuse/Release Equivalence Principle
재사용 단위는 릴리즈 단위와 같다.
위 문장처럼 하나의 component에 묶인 class와 module은 함께 release해야한다는 원칙이다. 즉 component는 cohesion이 높은 class와 module로 묶여야 한다는 뜻이다.
CCP : 공통 폐쇄 원칙 Common Closure Principle
동일한 이유로 동일한 시점에 변경되는 class를 같은 component로 묶어라.
Single Responsibility Principle의 component 버전이다. Single Responsibiltiy Principle은 class는 단 하나의 책임만 가져야 한다는 원칙이다. 이와 같이 Common Closure Principle 또한 component는 단 하나의 책임만 가져야 한다는 것이다. (== component는 변경 이유가 여러 개 있어서는 안된다.)
또한 Open Closed Principle와도 관계가 있는데, 동일한 시점에 변경되는 class가 다른 component에 속해 있다면 변경된 component를 모두 재배포해야 한다. 이것보다는 동일한 시점에 변경되는 class를 같은 component에 묶어 둔다면 한 component만 재배포하면 된다.
CRP : 공통 재사용 원칙 Common Reuse Principle
필요하지 않은 것에 의존하지 마라.
Interface Segregation Principle의 component 버전이다. Interface Segregation Principle은 사용하지 않는 method를 포함한 interface에 의존하지 말라는 원칙이다. 이와 같이 Common Reuse Principle은 사용하지 않는 class를 가진 component에 의존하지 말라는 원칙이다. (== 강하게 결합되지 않는 class를 같은 component에 묶어서는 안 된다.)
Component Relationship Principle : ADP, SDP, SAP
Component 관계에 관한 원칙 3가지.
ADP : 의존성 비순환 원칙 Acyclic Dependency Principle
component dependency graph은 acyclic이어야 한다.
어떤 component가 의존하고 있던 component를 수정한다면 그 component는 작동하지 않게 된다. 이를 해결하기 위해 개발 환경을 release 가능한 component 단위로 분리해야 한다. 이를 통해 component는 각 작업 단위가 되고, 해당 component의 release를 다른 개발자가 사용할 수 있다. 만약 새로운 release가 나왔다면 그 component를 사용하는 팀에서는 release를 사용할지 말지 판단만 하면 된다. 따라서 어떤 팀도 다른 팀에 의존하지 않게 된다.
이를 위해서는 component dependency가 acyclic이어야 한다. 만약 dependency graph가 cyclic이라면 cycle을 가지는 모든 component를 하나의 component로 묶이며, 하나의 작업 단위가 되어버린다. 이를 막기 위해 아래 2가지 방법을 쓸 수 있다.
- Dependency Inversion Principle 사용
- 두 component가 depend하는 새로운 component 작성
이렇게 component dependency에서 cycle이 생기는 것을 막기 위해 조치를 하며 dependency graph는 서서히 바뀌며 top-down으로 설계될 수 없다. 따라서 component dependency graph가 cycle을 가지는지 항상 관찰해야 한다.
SDP : 안정된 의존성 법칙 Stable Dependency Principle
더 stable한 쪽에 depend하라.
dependency를 가지는 module은 설계하기 어렵다. 만약 component A가 component B를 depend한다면(import한다면), component B를 수정하면 component A가 오작동할 확률이 높기 때문에 수정하기 어려워진다. 즉 어떤 component를 누군가가 depend한다면 해당 component를 바꾸기 어려워진다. 이를 막기 위해 변하기 어려운 쪽에(stable한 쪽에) dependf해야만 한다. 아래 두 예시를 보자.

3개의 component가 X에 depend하고 있다. 책에서는 "X가 3개의 component를 책임지며, 따라서 X는 수정하기 어려우므로 stable하다. X는 어디에도 depend하지 않으므로 변경될 이유가 없으므로 independent하다"고 설명한다.
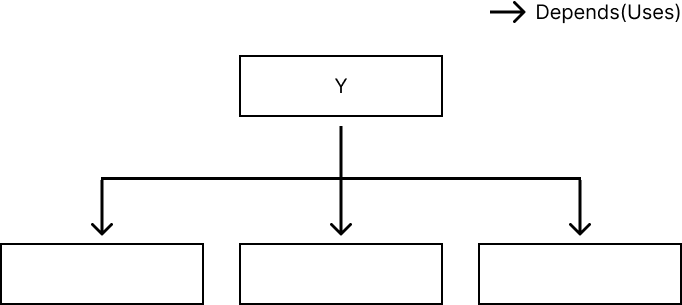
Y는 3개의 component에 depend하고 있다. 책에서는 "Y를 depend하는 component가 없기 때문에 Y는 책임성이 없으며, 수정하기 쉬우므로 instable하다. 다른 3개 component에 depend하므로 이들의 변경으로 인해 변경될 수 있다. 따라서 dependent하다"고 설명한다.
안정성 지표
- Fan-in : 해당 component를 depend하는 component의 개수
- Fan-out : 해당 component가 depend하는 component의 개수
- instability I (불안정성) : Fan-out / (Fan-in + Fan-out), 0이면 stable, 1이면 instable.
- I = 0일 때 다른 component에 의존하지 않으므로 다른 component를 책임지며, independent하다. 따라서 변경하기 어렵다. 반면 I = 1이면 다른 component에 의존하기만 하므로 책임지는 component가 없으므로 dependent하다. 따라서 변경하기 쉽다.
Stable Dependent Principle은 바깥으로 가면 갈수록 I값이 커야 한다는 것을 의미한다. 만약 깨진다면 Dependency Inversion Principle을 사용해 I가 감소하는 방향으로 dependency가 향해야 한다.
SAP : 안정된 추상화 원칙 Stable Abastraction Principle
component는 안정될 정도만큼만 abstraction되어야 한다.
business logic이나 고수준 architecture의 경우 변동성이 없기를 기대하기 때문에 이러한 component는 stable해야 한다.(I = 0이어야 한다.) stable component는 abstract component로, instable component는 concrete component로 사용하면 결국 dependency는 abstraction으로 향하게 된다.
추상화 정도 지표
- Nc : component의 class 개수
- Na : component의 abstract class와 interface 개수
- 추상화 정도 A : Na / Nc. abstract class와 interface의 비율.
주계열 Main Sequence

Instability와 추상화 정도 A의 graph를 그리면 위와 같다.
- Pain Zone : I, A가 (0, 0) 근처에 있는 component는 stable하면서 concrete하다. 따라서 이 component를 수정하기 위해서는 많은 것을 바꾸어야 하기 때문에 매우 어렵다.
- Uselessness Zone : I, A가 (1, 1) 근처에 있는 component는 unstable하면서 abstract하다. abstract하지만 이 component에 의존하는 component가 없기 때문에 필요없는 component이다.
- Main Sequence(주계열) : 여기에 있는 component는 너무 추상적이지도 않고, 너무 불안정하지도 않다. 이 component는 다른 component에 적당히 의존하며, 이 component에 적당한 component가 의존하고 있다. 바람직한 component이다.
이 값을 이용해 D 값을 도출할 수 있다. D값은 main sequence에 얼마나 가까이 위치하나를 의미하며 D값의 평균과 분산을 이용해 통계를 낼 수 있다. 다른 방법으로, 시간에 따라 D값의 변화를 추출해 어떻게 변하는지를 살펴볼 수도 있다.
- D : |A + I - 1|. D가 0일 때 main sequence에 위치하며, 1일 때 가장 멀리 위치한다.
Ch 5. 아키텍처
이 장에서는 architecture가 무엇인지, 어떤 식으로 architecture를 설계해야 하는지를 다룬다. 이 책의 제일 중요한 부분이며, 사실상 앞선 챕터들은 이 챕터를 설명하기 위한 빌드업이다.
아키텍처란 시스템의 형태이며 소프트웨어가 쉽게 개발, 배포, 운영, 유지보수되도록 만든다. 이를 위해 가능한 한 많은 선택지를 가능한 한 오래 남겨두는 전략을 따르며, 중요한 것은 abstraction하고, 세부사항은 plug-in 형태로 격리한다.
소트프웨어는 변경하기 쉬워야 한다. architecture는 이 대전제를 달성하기 위해 세부사항과 business logic을 엄격하게 분리하며, (자주 변하는) 세부사항의 변화가 business logic에 영향을 주지 않도록 설계한다. 이를 통해 가능한 한 많은 선택지를 가능한 한 오래 남겨두는 전략을 실현한다. 예를 들어 DB 종류가 MySQL인지 Oracle인지 H2인지는 세부사항이다. 프론트가 React인지 Vue인지 Web인지는 세부사항이다. 출력 장치가 모니터인지, 콘솔인지는 세부사항이다. 이러한 종류의 세부사항에 의존하지 않고 business logic을 만든다면 business logic을 구현하는 동안 다양한 실험을 해 볼 수 있고 더 많은 것을 시도할 수 있으며 이렇게 쌓인 데이터를 이용해 최선의 결정을 내릴 수 있다.
usecase의 결합 분리
component를 쪼갤 때 대표적으로 detail과 business logic으로 쪼갠다. 이들은 Common Closure Principle에 따르면 이들은 의도의 맥락에 따라 서로 다른 이유로 변경되기 때문이다.
뿐만 아니라 architecture는 모든 usecase를 알지는 못하지만 시스템의 기본적인 의도를 알고 있다. 또한 각 usecase는 서로 다른 이유로, 다른 속도로 발전해 가기 때문에 usecase로도 분리할 수 있다.

위 그림과 같이 usecase들을 분리하면 기존 component에 영향을 주지 않고 새로운 usecase를 계속해 추가할 수 있다. 이처럼 usecase의 결합을 각각 서로 다른 aspect로 분리함으로써 component를 독립시킬 수 있다.
만약 이 component가 다른 네트워크에서 실행된다면 이들 각각이 자신의 service를 제공하기 때문에 이들을 service, 또는 microservice라고 부르며 이러한 구조를 service oriented architecture라고 부른다. 이렇게 usecase와 계층의 결합을 분리하면 배포 측면에서도 유연성을 확보할 수 있으며, component가 완전히 분리되었기 때문에 각각의 개발 팀의 dependency도 사라진다.
중복
중복에도 여러 종류가 있다. 하나는 진짜 중복이다. 이 경우 한 instance가 변경되면 해당 변경을 모든 instance의 복사본에 적용해야 한다. 또 다른 하나는 우발적인 중복이다. 중복으로 보이는 두 코드가 서로 다른 속도와 다른 이유로 변경된다면 이 두 코드는 진짜 중복이 아니다.
usecase를 위 그림과 같이 분리할 때 이러한 문제와 마주치게 된다. 개발 초창기에는 대부분 비슷한 UI, 비슷한 query를 가지기 때문이다. 이를 막기 위해 중복이 진짜 중복인지 확인해야 한다.
따라서 분리하고, 각각이 같은 이유로 변경될지, 다른 이유로 변경될 수 있는지 고민해야 한다.
경계: 선 긋기
software architecture는 선을 긋는 기술이며, 이 선을 경계boundary라고 한다. Boundary는 component를 서로 분리하고, boundary 한쪽의 component가 다른 쪽의 component를 알지 못하게 막는다.
이러한 boundary를 이용해 usecase(business logic)과 관련없는 결정들, 예를 들어 framework, database, web server, 등등에 의존하지 않는 구조를 만든다.
관련이 있는 것과 없는 것에 boundary를 긋는다.
interface와 stub을 이용해 boundary를 생성할 수 있다. 아래 예시를 보자.

Business logic과 Database는 관계가 없다. DB는 세부사항이기 때문에 business logic은 DB에 관해 어떤 것도 알아서는 안 된다. 따라서 Dependency Inversion을 사용해 DB를 interface 뒤로 숨긴다. 이 때 boundary는 interface의 상속 관계에 수직으로 그어진다.

이렇게 dependency graph가 그려지면 Business Logic Component는 DB component의 존재를 모르기 때문에 바뀌어도 문제가 되지 않지만, DB component는 Business Logic에 의존하기 때문에 바뀌면 문제가 생긴다.
이 예시는 DB를 예로 들지만 모든 세부사항을 이처럼 표현할 수 있다. 이러한 architecture를 plugin architecture라고 부른다. 세부사항을 plugin architecture로 구성함으로써 business logic은 independent하며, 자주 바뀌는 세부사항은 business logic에 dependent하다. 이처럼 dependency arrow는 항상 low level(detail)에서 high level(business logic)로 향해야 한다.
좀 더 자세히
dependency inversion이 일어날 때 경계에서 어떤 일이 일어나는지 아래 두 예시를 보자.

기존의 경우, low level인 client가 high level인 service를 호출한다. 따라서 flow of control은 low level에서 high level로 향하고, boundary에서 dependency 또한 low level에서 high level로 향한다. 이 때 호출당하는 쪽에 Data 정의가 위치한다.

dependency inversion이 적용되면 flow of control은 client가 service interface를 통해 low level인 ServiceImpl을 호출한다. 그러나 boundary에서 dependency는 이와 반대로, low level에서 high level로 depend한다. 이 때, 호출하는 쪽에 Data 정의가 위치한다.
따라서, 이러한 방식으로 구조를 분리하면 실 구현과 상관없이 component를 독립적으로 작업할 수 있다.
Business Logic
Entity
business logic은 사업적으로 수익을 얻거나 비용을 줄일 수 있는 규칙, 또는 절차이다. 책에서는 critical business rule이라고 명명한다. critical business data는 critical business rule이 필요로 하는 데이터이다.
critical business rule과 critical business data는 결합되어 있기 때문에 객체로 만들기 좋은 후보이며, 이러한 객체를 Entity라고 한다.
Entity는 critical business rules를 구체화한다. Entity는 어떤 시스템에서도 business를 수행하며, 어떠한 세부사항과도 관계없다.
Usecase
usecase는 자동화된 시스템이 사용하는 방법을 설명한다. 사용자가 제공하는 입력, 사용자에게 보여줄 출력, 해당 출력을 생성하기 위한 처리 단계를 기술한다.
usecase는 entity 내부의 critical business rule을 어떻게, 언제 호출할지 명시하는 규칙을 담는다.
Entity와 Usecase
Entity는 high level, Usecase는 low level이다. Usecase는 단일 서비스에 특화되어 있으며 Entity보다 입출력에 더 가까이 위치한다. Entity는 수많은 서비스에서 사용될 수 있도록 일반화된 것이기에 더 높은 추상화를 가지고 있다.
즉, Usecase가 Entity를 사용하며, 의존한다. 반면 Entity는 independent하다.
Usecase는 데이터 구조를 입력으로 받고, 계산 결과를 데이터 구조로 리턴한다. 입출력에 사용하는 데이터 구조와 Entity는 매우 유사할 수 있다. 그러나 이 둘은 가짜 중복이다. 시간이 지나면 이 둘은 완전히 다른 이유로 변경될 것이기 때문이다.
그래서 spring에서는 entity를 dto로 변경해 리턴한다.
험블 객체
humble object pattern은 테스트하기 어려운 행위와 테스트하기 쉬운 행위를 unit test하기 쉽게 하는 방법으로 고안되었다. 가장 기본적인 본질은 남기고, 테스트하기 어려운 행위를 모두 humble object로 옮긴다. 이를 통해 presenter와 view라는 서로 다른 class를 나눌 수 있다. 이처럼 테스트하기 쉬운 부분과 테스트하기 어려운 부분으로 나누면 architecture boundary가 정의된다.
예를 들어 GUI는 테스트하기 어렵지만 이 때 수행하는 행위는 검사하기 쉽다. presenter는 화면에 출력할 수 있는 형태로 데이터를 가공하고, view는 해당 데이터를 화면에 출력하기만 한다. view는 데이터를 화면에 출력할 뿐이며 다른 역할은 전혀 없다. 따라서 view는 humble object이며, unit test 시 presenter만 테스트하면 되므로 테스트 용이성이 크게 증가한다.
계층과 경계
architecture boundary는 어디에나 존재하기 때문에 언제 boundary가 필요한지 신중하게 파악해야 한다.
abstraction이 필요하리라고 미리 예측해서는 안 된다. 어디에 architecture boundary를 둬야 할지, 완벽하게 구현할 boundary는 무엇인지, 부분적으로 구현할 boundary는 무엇인지, 무시할 boundary는 무엇인지 결정해야만 한다. 프로젝트 초반에는 이 결정이 어려우므로 계속 지켜보며 boundary가 존재하지 않아 생기는 마찰을 관찰해야 한다.
과하게 architecture를 짜면 cost가 높다. 그렇다고 architecture가 없는 상황에서 architecture를 재구성하는 것도 cost가 높다. 따라서 잘 예측하고, 잘 관찰하고, 세부 결정을 뒤로 미뤄 최선의 선택을 해야 한다.
Main
main은 os를 제외하면 어떠한 것도 의존하지 않기 때문에 가장 낮은 level이다. 즉 main은 architecture에서 제일 바깥쪽에 위치하는 지저분한 low level module이다. 메인은 high level system을 위한 모든 resource를 로드한 후 flow of control을 넘긴다.
main을 초기 조건과 설정을 구성하고, 자원을 생성한 후 제어권을 넘기는 하나의 plug-in component로 생각한다면 설정 관련 문제를 쉽게 해결할 수 있다.
크고 작은 모든 서비스들
service를 사용함으로써 service 사이의 결합이 확실히 분리되고, 개발 및 배포를 독립적으로 할 수 있다고 여긴다. 그러나 책에서는 이에 대해 부정한다.
service는 process나 server의 경계를 가로지르는 함수 호출과 동일하다.
위 문장처럼 service를 하나의 함수 호출이라고 생각하면 쉽게 이해할 수 있다. 만약 business logic이 바뀌어 service 사이에서 주고받는 데이터 형식이 바뀌어야 한다면? 결국 service는 분리되지 않는다. 같은 상황에서 개발 및 배포도 같이 이루어져야 한다.
architecture boundary는 service 사이에 있지 않다. 오히려 service를 관통하며, service를 component 단위로 분할한다.
system architecture는 boundary와 boundary를 넘나드는 dependency에 의해 정의된다. 따라서 service 내부 또한 dependency 규칙을 준수하는 component architecture로 설계해야 한다.
테스트 boundary
test는 architecture의 가장 바깥쪽 원이다. 그 어떤 것도 test에 의존하지 않으며, test는 항상 system component에 의존한다.
test 또한 dependency를 가지고 있다. coupling이 아주 높은 test라면 시스템이 변경될 때 같이 변경되어야 하므로 component가 변경되면 테스트가 모두 실패하게 된다. 따라서 테스트를 system의 일부로 설계해야 한다. 항상 그렇듯, 변동성이 있는 것에 의존하면 안 된다.
정리
이 책은 처음부터 끝까지 쉽게 수정할 수 있는 소프트웨어를 작성하는 목표를 설정하고, 이 주된 방법으로 abstract나 interface를 사용한 Dependency Inversion를 제시하며, 언제 사용해야 하는지를 제시한다. 추가적으로 이런 저런 정보도. 항상 그렇지만 이런 책들은 필요하다고 생각될 때 읽는 게 새로운 시각을 열어주는 것 같다. 지금까지 작성했던 코드들을 생각해 보면서 반성하기도 하고, 배운 내용들과 읽은 내용들이 어우러져 놓쳤던 통찰을 열어 주기도 하고. 느낀 점이 많은 책이었다. 앞으로 코드를 짤 때 계속 class architecture와 dependency graph를 고민해야겠다.
정말 긴 책이지만 몇 줄로 간단하게 표현할 수 있을 것 같다.
- 소프트웨어는 쉽게 수정할 수 있어야 한다.
- 따라서 변동성이 있는 것에 의존하지 않고, 변하지 않는 것에 의존해야 한다.
- 이를 위해 변하지 않는 business logic과 쉽게 변하는 detail을 분리하고, detail을 plug-in으로 만들어 변경의 파급을 줄인다.
- 이 때 component architecture graph는 acyclic해야 한다.
- 또한 진짜 중복과 가짜 중복을 가려내야 한다.
- usecase를 분리해 cross cutting concern을 만들기도 한다.
- plug-in으로 만드는 방식은 Dependency Inversion을 이용한다. 이를 통해 항상 low level이 high level에 의존하게 만든다. 항상 concrete가 abstraction에 의존하게 만든다.
- 이를 통해 low level의 변경이 high level에 영향을 주지 않게 만들 수 있다.
- test 또한 system의 일부로 생각해 dependency를 고려해야 한다.
'Development > Study' 카테고리의 다른 글
| [개발서적] The Pragmatic Programmer 정리 (0) | 2023.03.22 |
|---|---|
| [개발서적] 다시 쓰는 Clean Code 정리 (0) | 2023.03.19 |
| [개발서적] Clean Code 정리 (0) | 2022.06.24 |