
오늘은 Codeforces Round #797 Div. 3를 풀었다.
https://codeforces.com/contest/1690
Dashboard - Codeforces Round #797 (Div. 3) - Codeforces
codeforces.com
결과
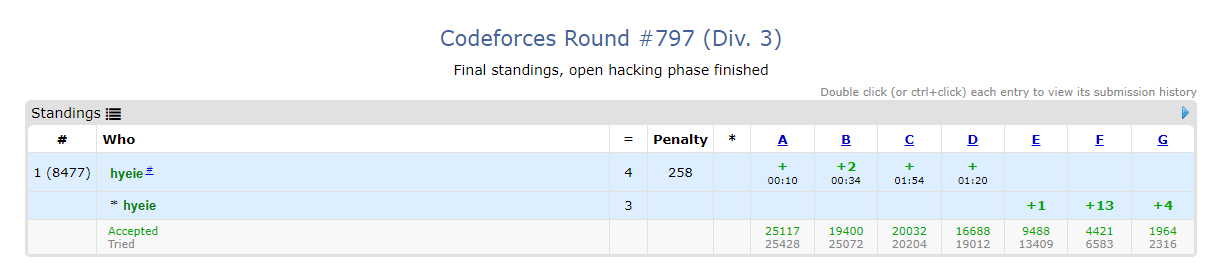
A, B, C, D번은 시간 내에 풀고 제출했다. 7문제 중 4문제를 맞췄다.
A번
규칙 찾기 문제
// x + x-1 + x-2 = 3x-3
int h1 = (int)ceil((double)(n+3)/3);
int h2 = (n - h1)/2 + 1;
int h3 = n - h1 - h2;
B번
간단한 문제였지만 범위 조절이 중요했다. b[i]가 0이 아닐 때 a[i] - b[i]의 차이의 min값을 저장하고, a[i] - min_value <= 0이거나 a[i] - min_value == b[i]면 continue, 그렇지 않으면 문제 조건을 만들 수 없다.
다만, 문제의 입력이 10억이었기 때문에 범위를 long long으로 잡아야 풀렸다.
void solve(){
int n; cin>>n;
vector<ll> a(n), b(n);
ll diff_min = INF;
for(int i = 0; i<n; i++){
cin>>a[i];
}
for(int i = 0; i<n; i++){
cin>>b[i];
if(b[i] != 0) diff_min = min(a[i] - b[i], diff_min);
}
for(int i = 0; i<n; i++){
if(a[i] < b[i]){
cout<<"NO\n";
return;
}
if(a[i] - diff_min <= 0 || a[i] - diff_min == b[i]) continue;
else{
cout<<"NO\n";
return;
}
}
cout<<"YES\n";
}
C번
simulation 문제. 처음에는 문제에 주어진 대로 queue로 풀려 했는데 너무 까마득해서 two-pointer로 풀었다.
void solve(){
int n; cin>>n;
vector<int> s(n), f(n);
for(int i = 0; i<n; i++){
cin>>s[i];
}
for(int i = 0; i<n; i++){
cin>>f[i];
}
int left = 0, right = 0, start_time;
while(left < n){
while(right < n -1 && f[right] > s[right + 1]){ // 다음 일의 시작이 현재 일의 끝보다 작은 경우 그 일 queue에 들어가 있다.
right++;
}
if(left == right){ // left, right index 값이 같으면 queue에 이 일만 있는 것
cout<<f[left] - s[left]<<' ';
left++; right++;
} else{ // queue에 일이 2개 이상 있는 경우.
start_time = s[left];
while(left <= right){ // 일의 시작 시간 = f[q.top()]
cout<<f[left] - start_time<<' ';
start_time = f[left];
left++;
}
right = left;
}
}
cout<<'\n';
}
D번
sliding window로 간단히 풀 수 있는 문제. 범위만 잘 조절하면 된다.
void solve(){
int n, k; // k개의 연속된 것이 black이기 위해서 몇개를 칠해야 하는지의 min값
cin>>n>>k;
string s; cin>>s;
// sliding window
int num_white = 0;
for(int i = 0; i<k; i++){
if(s[i] != 'B') num_white++;
}
int min_value = num_white;
for(int i = 0; i<n-k; i++){
if(s[i+k] == 'W') num_white++;
if(s[i] == 'W') num_white--;
min_value = min(min_value, num_white);
}
cout<<min_value<<'\n';
return;
}
Upsolving
C번(simualation)에서 시간을 너무 많이 썼다. B번에서도 범위 문제인 줄 모르고 다른 방법으로 풀다가 늦게 찾았고. 음... 조급해 할 필요는 없다고 생각하지만, 좀 더 빠르고 정확하게 해 보자. 풀다 보면 구현력이 늘 것이다. 될 때까지 머리 박으면 된다.
C번
two-pointer로 풀지 않고, 그냥 문제의 특성을 이용할 수도 있다.
만약 i번째 일과 i+1번째 일이 겹치지 않는다면 f[i] - s[i], 겹친다면 f[i] - f[i-1]이다. 이 특성을 이용해서 풀면 된다. 겹치는 것은 index를 이용해 비교해도 되지만, 겹친다면 cur_time(f[i-1])이 되고, 겹치지 않는다면 s[i]를 cur_time으로 지정해 버리면 된다. 호호...쩐다.
int cur_time = 0;
for(int i = 0; i<n; i++){
cur_time = max(cur_time, s[i]);
cout<<f[i] - cur_time<<' ';
cur_time = f[i];
}
E번
기본적으로 arr[i]에 대해, arr[i] / k는 무조건 답에 더해진다. 그러면 이것을 미리 답에 더해두고, arr[i] %= k를 해 준다. 그렇다면 남은 것은 arr[i], arr[j]를 골라서 arr[i] + arr[j] >= k인지 여부이다.
기본적으로 arr[i], arr[j]를 아무리 고르더라도 이 둘의 합은 2k보다 크거나 같아질 수 없다. 0 <= arr[i] < k이기 때문이다. 그렇다면 정렬한 후, greedy하게 고르기만 하면 된다.
two-pointer이다. 양 끝단으로부터 다가오고, arr[left] + arr[right] >= k라면 answer++이고, 한칸씩 당긴다. 그렇지 않다면 sum이 k보다 작다는 말이므로 left++해 준다.
이렇게 greedy하게 것에 대한 증명 : greedy하게 고르지 않은 것이 optimal이라 가정하자.
left++를 하면 left보다 더 큰 수가 오고, right--하면 right보다 더 작은 수가 옴. 위 가정은, 현재 left, right를 뽑을 수 있는데도 뽑지 않고 더 안쪽의 것을 위해 양보하는 상황임. left++를 해서 오는 수는 left보다 더 큼. 이 수를 고른다면 그만큼의 수를 낭비하기 때문에 not optimal임. right--를 해서 오는 수는 right보다 더 작음, 그만큼의 수를 cover하기 위해 left를 더 당겨야 함. 따라서 가정에 모순. QED.
void solve(){
int n, k; cin>>n>>k;
vector<int> arr(n);
ll answer = 0;
for(int i = 0; i<n; i++){
cin>>arr[i];
answer += arr[i] / k;
arr[i] %= k;
}
sort(arr.begin(), arr.end());
int left = 0, right = n-1;
while(left < right){
if(arr[left] + arr[right] >= k){
answer++;
left++; right--;
} else{
left++;
}
}
cout<<answer<<'\n';
}
F번
일단 처음에는 '각 cycle들의 LCM'인 것은 알았는데, 각 cycle을 구하는 데서 문제가 있었다. cycle이 있는지 검사 -> DFS를 무조건 떠올렸어야 했음에도 DFS를 선택 안해서 대참사가 벌어졌고... 그렇게 구현하는 중에 '똑같은 것이 반복되면 그것을 cycle로 생각'해버렸다. 그러나 이 경우, 'ababcababc'와 같은 cycle의 경우, abab가 반복되기 때문에 여기서 cut해버렸고, 여기서 문제가 생겼다. 그래서 cycle을 구하는 것 부터 다시...
DFS처럼, not visited인 것에 대해서 visited가 될 때 까지 loop를 돌리고, 그렇게 방문한 char들을 저장한다. 그러나 여기서 중요한 점 하나! 이렇게 구한 string이 'abab'와 같이, 같은 것이 반복되는 경우에는 cycle 길이가 2라고 생각해야 한다. 그러나 첫 접근과 같이 '똑같은 것이 반복되는 경우 cycle로 생각'하면 안되고, 제일 앞의 것을 뒤로 보내보아서 그것이 원래 string과 동일하다면 그만큼을 cycle로 생각할 수 있다. 예를 들어, 'abab'의 경우 'abab' - 'baba' - 'abab'가 되고, 최소 cycle은 2가 된다. 이렇게 하는 경우 'ababc'와 같은 경우는 'ababc' - 'babca' - 'abcab' - 'bcaba' - 'ababc'가 되어서 문제가 생기지 않는다. 이게 중요했다!
int gcd(int a, int b){
int r;
if(b > a) return gcd(b, a);
while(b != 0){
r = (int)a % b;
a = b;
b = r;
}
return a;
}
ll lcm(int a, int b){
return (ll)a * b / gcd(a, b);
}
// abcdefab와 같이 일반적인 경우 -> 길이를 리턴
// abcabc와 같이 반복되는 경우 -> 그 최소 cycle을 찾아 리턴
int minCycle(string s){
int i;
for(i = 1; i<s.length(); i++){
string f = s.substr(i), e = s.substr(0, i);
if(f + e == s) break;
}
return i;
}
void solve(){
int n; cin>>n;
string s; cin>>s;
vector<int> arr(n);
vector<bool> visited(n, false);
for(int i = 0; i<n; i++){
cin>>arr[i];
arr[i]--;
}
ll answer = 1;
for(int i = 0; i<n; i++){
if(visited[i]) continue;
string loop = "";
while(!visited[i]){ // cycle 찾기
loop += s[i];
visited[i] = true;
i = arr[i];
}
int min_cycle = minCycle(loop);
answer = lcm(answer, min_cycle);
}
cout<<answer<<'\n';
}
G번
기차의 group 개수를 출력하는 문제. 기차의 speed vector를 저장하고, a[i] < a[i+1]이면 a[i+1]은 a[i]와 같은 group에 들어간다. 다만 조금 다르게 생각해서 group의 시작 index를 set에 넣고 계산을 한다.
어떤 index k의 속도가 줄었을 때,
- k가 set에 존재하는 경우 - k는 이미 기차 group의 시작임 - 아무것도 할 필요 없음
- k가 set에 없는 경우 - k는 기차 group에 속해있음 - k가 속한 group의 속도보다 k의 속도가 더 작아야만 k로부터 시작하는 새 group이 생성됨
와 같다. 이걸 먼저 검사하고, 다음으로 'k가 속한 group인 k group, k+1 group, k+2 group, ... , end group에 대해, k group의 속도가 end group의 속도보다 작거나 같을 때까지' (speed[k] <= speed[end]인 모든 end에 대해) end를 set에서 지워야 한다. k의 속도보다 큰 것은 모두 k group에 들어가기 때문.
'k가 속한 group'은 어떻게 알아내느냐? set에서 binary search - lower bound를 한다. clusters.lower_bound(k)는 k보다 크거나 같은 값을 준다. 만약 k가 group의 선두라면 k를 리턴, 그렇지 않다면 k+1 group을 리턴한다. 그러나 clusters에 k가 있다는 것은 k가 그룹 선두라는 것이므로 prev(clusters.lower_bound(k))를 해서 k가 속한 group을 찾을 수 있다.
'k의 다음 group'은 어떻게 알아내느냐? set에서 upper bound를 한다. k가 set에 있든 없든, k 다음번의 group의 선두를 리턴한다. 이걸 이용해 speed[k]보다 큰 모든 group을 알아낼 수 있다.
시간복잡도는 O((n+m)logn)이다. 총 m번 탐색이며 모든 탐색에서 group에 값을 넣어도 set의 크기는 최대 2n이기 때문에 set의 모든 값을 erase해도 worst case O(2n)이다. 또한 각 탐색에서 binary search를 1번씩 하기 때문에 O((m+n)logn)이다.
#define _USE_MATH_DEFINES
#include <iostream>
#include <vector>
#include <algorithm>
#include <string>
#include <queue>
#include <iterator>
#include <cmath>
#include <numeric>
#include <map>
#include <cmath>
#include <set>
using namespace std;
typedef long long ll;
typedef pair<int, int> pii;
typedef pair<int, string> pis;
void solve(){
string empty;
getline(cin, empty);
int n, m; cin>>n>>m;
vector<int> a(n);
set<int> clusters; // 기차 group의 시작 index. 오름차순 정렬되어 있지만, vector안쓰는 이유는 삭제 연산이 오래 걸려서
for(int i = 0; i<n; i++){
cin>>a[i];
if(clusters.empty() || a[*(clusters.rbegin())] > a[i]) clusters.insert(i);
}
int k, d;
for(int i = 0; i<m; i++){
cin>>k>>d;
k--;
a[k] -= d;
// 만약 set에 k가 있는 경우 -> k는 이미 기차 group의 시작임 -> 아무것도 할 필요 없음
// 없는 경우 -> k가 속한 group의 군집을 찾아야 함 -> prev(lower_bound()).
// 이후, 그 군집의 속도보다 바뀐 속도가 더 작아야 새로운 group을 만들 수 있음
if(clusters.find(k) == clusters.end()){ // 없는 경우, 그 군집의 value보다 작아야 넣을 수 있음
set<int>::iterator iter = prev(clusters.lower_bound(k));
if(a[*iter] > a[k]) clusters.insert(k);
} // 있는 경우, 아무것도 안 해도 됨
// TLE 나는 코드
/*
// 현 group부터 'group의 속도가 현 group보다 작기 전까지' 반복
set<int>::iterator iter = clusters.lower_bound(k), next_iter;
while(1){
next_iter = next(iter);
// 끝이거나, k의 value가 더 클 경우까지 계속 지움
if(next_iter == clusters.end() || a[*next_iter] < a[k]) break;
clusters.erase(next_iter);
}*/
// 현 group부터 'group의 속도가 현 group보다 작기 전까지' 반복
while(1){
set<int>::iterator iter = clusters.upper_bound(k);
// 끝이거나, k의 value가 더 클 경우까지 계속 지움
if(iter == clusters.end() || a[*iter] < a[k]) break;
clusters.erase(iter);
}
cout<<(int) clusters.size()<<' ';
}
cout<<'\n';
}
/*
각각 k, d에 대해 줄이고, 줄인 이후에 몇 개의 군집이 남아있는지 계산하는 문제임
set에는 기차가 시작하는 index를 두고,
k, d가 입력되어서 carriage의 속도를 감속시켜야 할 때 (k는 기차 index, d는 감속량)
set에 존재하는(group의 시작점) k보다 큰 모든 index i에 대해, a[i] >= a[k]라면 i로 시작하는 group은 지워야 한다.
또한 set은 오름차순 정렬이기에 a[i] < a[k]면 탐색을 그만두어도 된다.
시간복잡도는 O(mlogn)이며, 총 m번 탐색하며, 1번의 탐색에서 이진탐색에 logn이며, 모든 탐색에서 group에 값을 넣어봤자 set의 size는 2n, 따라서 erase하는 최대의 횟수는 2n이다.
즉, 총 m번 탐색, 총 2n번 삭제, 각 탐색에서 이진탐색 logn이니까 O((m+n)logn)이다.
*/
int main(void) {
cin.tie(0);
cout.tie(0);
std::ios_base::sync_with_stdio(0);
////////////////////// write your code below
int t; cin>>t;
while(t--){
solve();
}
//////////////////////
return 0;
}
'PS > PS Log' 카테고리의 다른 글
| 22.07.01 풀었던 문제들 (0) | 2022.07.01 |
|---|---|
| 22.06.30. 풀었던 문제들 (0) | 2022.06.30 |
| 22.06.28. 풀었던 문제들 (0) | 2022.06.28 |
| 22.06.27. 풀었던 문제들 *** 신발끈 공식 (0) | 2022.06.26 |
| 22.06.26. 풀었던 문제들 (0) | 2022.06.26 |